
Capítulo 15.6
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
path_data = '../../../assets/data/'
import numpy as np
from scipy import stats
import matplotlib
matplotlib.use('Agg')
%matplotlib inline
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
Diagnóstico Numérico
Além da visualização, podemos usar propriedades numéricas de resíduos para avaliar a qualidade da regressão. Não provaremos essas propriedades matematicamente. Em vez disso, iremos observá-las por cálculo e ver o que elas nos dizem sobre a regressão.
Todos os fatos listados abaixo são válidos para todas as formas de gráficos de dispersão, sejam eles lineares ou não.
family_heights = Table.read_table(path_data + 'family_heights.csv')
heights = family_heights.select('midparentHeight', 'childHeight')
heights = heights.relabel(0, 'MidParent').relabel(1, 'Child')
dugong = Table.read_table(path_data + 'dugongs.csv')
dugong = dugong.move_to_start('Length')
hybrid = Table.read_table(path_data + 'hybrid.csv')def standard_units(x):
return (x - np.mean(x))/np.std(x)
def correlation(table, x, y):
x_in_standard_units = standard_units(table.column(x))
y_in_standard_units = standard_units(table.column(y))
return np.mean(x_in_standard_units * y_in_standard_units)
def slope(table, x, y):
r = correlation(table, x, y)
return r * np.std(table.column(y))/np.std(table.column(x))
def intercept(table, x, y):
a = slope(table, x, y)
return np.mean(table.column(y)) - a * np.mean(table.column(x))
def fit(table, x, y):
a = slope(table, x, y)
b = intercept(table, x, y)
return a * table.column(x) + b
def residual(table, x, y):
return table.column(y) - fit(table, x, y)
def scatter_fit(table, x, y):
table.scatter(x, y, s=15)
plots.plot(table.column(x), fit(table, x, y), lw=4, color='gold')
plots.xlabel(x)
plots.ylabel(y)
def residual_plot(table, x, y):
x_array = table.column(x)
t = Table().with_columns(
x, x_array,
'residuals', residual(table, x, y)
)
t.scatter(x, 'residuals', color='r')
xlims = make_array(min(x_array), max(x_array))
plots.plot(xlims, make_array(0, 0), color='darkblue', lw=4)
plots.title('Residual Plot')
def regression_diagnostic_plots(table, x, y):
scatter_fit(table, x, y)
residual_plot(table, x, y) heights = heights.with_columns(
'Fitted Value', fit(heights, 'MidParent', 'Child'),
'Residual', residual(heights, 'MidParent', 'Child')
)Gráficos Residuais não Mostram Tendência
Para cada regressão linear, seja boa ou ruim, o gráfico residual não mostra nenhuma tendência. No geral, é plano. Em outras palavras, os resíduos e a variável preditora não estão correlacionados.
Você pode ver isso em todos os gráficos de resíduos acima. Também podemos calcular a correlação entre a variável preditora e os resíduos em cada caso.
correlation(heights, 'MidParent', 'Residual')| Out[1]: | -2.719689807647064e-16 |
Isso não parece zero, mas é um número minúsculo que é 0, exceto pelo erro de arredondamento devido ao cálculo. Aqui está novamente, correto para 10 casas decimais. O sinal de menos é por causa do arredondamento acima.
round(correlation(heights, 'MidParent', 'Residual'), 10)| Out[2]: | -0.0 |
dugong = dugong.with_columns(
'Fitted Value', fit(dugong, 'Length', 'Age'),
'Residual', residual(dugong, 'Length', 'Age')
)
round(correlation(dugong, 'Length', 'Residual'), 10)| Out[3]: | 0.0 |
Média dos Resíduos
Independentemente da forma do diagrama de dispersão, a média dos resíduos é 0.
Isso é análogo ao fato de que, se você pegar qualquer lista de números e calcular a lista de desvios em relação à média, a média dos desvios será 0.
Em todos os gráficos de resíduos acima, você viu a linha horizontal em 0 passando pelo centro do gráfico. Isso é uma visualização desse fato.
Como exemplo numérico, aqui está a média dos resíduos na regressão das alturas das crianças com base nas alturas dos pais.
round(np.mean(heights.column('Residual')), 10)| Out[4]: | 0.0 |
O mesmo acontece com a média dos resíduos na regressão da idade dos dugongos em seu comprimento. A média dos resíduos é 0, fora o erro de arredondamento.
round(np.mean(dugong.column('Residual')), 10)| Out[5]: | 0.0 |
SD dos Resíduos
Independentemente da forma do gráfico de dispersão, o desvio padrão (SD) dos resíduos é uma fração do desvio padrão da variável resposta. A fração é √(1-r2).
Em breve veremos como isso mede a precisão da estimativa de regressão. Mas primeiro, vamos confirmar isso com um exemplo.
No caso das alturas dos filhos e alturas dos pais, o desvio padrão dos resíduos é de cerca de 3,39 polegadas.
np.std(heights.column('Residual'))| Out[6]: | 3.3880799163953426 |
Isso é o mesmo que √(1-r2) vezes o SD da variável de resposta:
r = correlation(heights, 'MidParent', 'Child')
np.sqrt(1 - r**2) * np.std(heights.column('Child'))| Out[7]: | 3.388079916395342 |
O mesmo é verdade para a regressão da quilometragem na aceleração de carros híbridos. A correlação r é negativa (cerca de -0,5), mas r^2 é positiva e, portanto, √(1-r2) é uma fração.
r = correlation(hybrid, 'acceleration', 'mpg')
r| Out[8]: | -0.5060703843771186 |
hybrid = hybrid.with_columns(
'fitted mpg', fit(hybrid, 'acceleration', 'mpg'),
'residual', residual(hybrid, 'acceleration', 'mpg')
)
np.std(hybrid.column('residual')), np.sqrt(1 - r**2)*np.std(hybrid.column('mpg'))| Out[9]: | (9.43273683343029, 9.43273683343029) |
Agora vamos ver como o desvio padrão dos resíduos é uma medida de quão boa é a regressão. Lembre-se de que a média dos resíduos é 0. Portanto, quanto menor for o desvio padrão dos resíduos, mais próximos os resíduos estarão de 0. Em outras palavras, se o desvio padrão dos resíduos for pequeno, o tamanho geral dos erros na regressão será pequeno.
Os casos extremos são quando r=1 ou r=-1. Em ambos os casos, √(1-r2) = 0. Portanto, os resíduos têm uma média de 0 e um desvio padrão de 0 também, e, portanto, os resíduos são todos iguais a 0. A linha de regressão faz um trabalho perfeito de estimativa. Como vimos anteriormente neste capítulo, se r = ± 1, o diagrama de dispersão é uma linha reta perfeita e é a mesma que a linha de regressão, portanto, não há erro na estimativa de regressão.
Mas geralmente r não está nos extremos. Se r não for nem ± 1 nem 0, então √(1-r2) é uma fração adequada, e o tamanho geral aproximado do erro da estimativa de regressão está entre 0 e o desvio padrão de y.
O pior caso é quando r = 0. Então √(1-r2) =1, e o desvio padrão dos resíduos é igual ao desvio padrão de y. Isso é consistente com a observação de que, se r=0, então a linha de regressão é uma linha plana na média de y. Nessa situação, o erro quadrático médio da regressão é o desvio quadrático médio em relação à média de y, que é o desvio padrão de y. Em termos práticos, se r = 0, então não há associação linear entre as duas variáveis, portanto, não há benefício em usar a regressão linear.
Outra Maneira de Interpretar r
Podemos reescrever o resultado acima para dizer que, independentemente da forma do diagrama de dispersão,
Um resultado complementar é que, independentemente da forma do diagrama de dispersão, o desvio padrão dos valores ajustados é uma fração do desvio padrão dos valores observados de y. A fração é | r |.
Para ver de onde vem a fração, observe que os valores ajustados estão todos na linha de regressão, enquanto os valores observados de y são as alturas de todos os pontos no diagrama de dispersão e são mais variáveis.
scatter_fit(heights, 'MidParent', 'Child')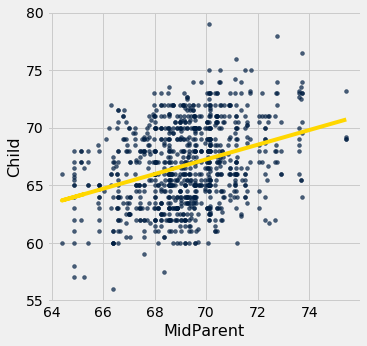
Os valores ajustados variam de cerca de 64 a cerca de 71, enquanto as alturas de todas as crianças são um pouco mais variáveis, variando de cerca de 55 a 80.
Para verificar o resultado numericamente, basta calcular os dois lados da identidade.
correlation(heights, 'MidParent', 'Child')| Out[10]: | 0.32094989606395924 |
Aqui está a razão entre o SD dos valores ajustados e o SD dos valores observados de peso ao nascer:
np.std(heights.column('Fitted Value'))/np.std(heights.column('Child'))| Out[11]: | 0.32094989606395957 |
A proporção é igual a r, confirmando nosso resultado.
Onde entra o valor absoluto? Primeiro, observe que os SDs não podem ser negativos, nem uma proporção de SDs. Então, o que acontece quando r é negativo? O exemplo de eficiência de combustível e aceleração nos mostrará.
correlation(hybrid, 'acceleration', 'mpg')| Out[12]: | -0.5060703843771186 |
np.std(hybrid.column('fitted mpg'))/np.std(hybrid.column('mpg'))| Out[13]: | 0.5060703843771186 |
A razão entre os dois desvio padrão (DPs) é | r |.
Uma maneira mais comum de expressar esse resultado é lembrar que
e, portanto, ao elevar ao quadrado ambos os lados do nosso resultado,
| ← Capítulo 15.5 – Diagnósticos Visuais |