
Capítulo 15.2
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
import numpy as np
path_data = '../../../assets/data/'
%matplotlib inline
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
A Linha de Regressão
O coeficiente de correlação r não apenas mede como os pontos em um gráfico de dispersão estão agrupados em torno de uma linha reta. Ele também ajuda a identificar a linha reta em torno da qual os pontos estão agrupados. Nesta seção, vamos refazer o caminho que Galton e Pearson percorreram para descobrir essa linha.
Como vimos, nosso conjunto de dados sobre as alturas dos pais e seus filhos adultos indica uma associação linear entre as duas variáveis. A linearidade foi confirmada quando nossas previsões das alturas dos filhos com base nas alturas dos pais aproximadamente seguiram uma linha reta.
original = Table.read_table(path_data + 'family_heights.csv')
heights = Table().with_columns(
'MidParent', original.column('midparentHeight'),
'Child', original.column('childHeight')
)
def predict_child(mpht):
"""Retorna uma previsão da altura de um filho
cujos pais têm uma altura do meio dos pais de mpht.
A previsão é a altura média dos filhos
cuja altura do meio dos pais está na faixa de mpht mais ou menos 0,5 polegadas.
"""
close_points = heights.where('MidParent', are.between(mpht-0.5, mpht + 0.5))
return close_points.column('Child').mean()
heights_with_predictions = heights.with_column(
'Prediction', heights.apply(predict_child, 'MidParent')
)
heights_with_predictions.scatter('MidParent')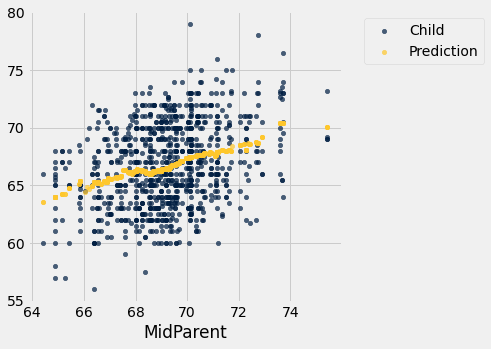
Medindo em Unidades Padrão
Vamos ver se conseguimos encontrar uma maneira de identificar esta linha. Primeiro, observe que a associação linear não depende das unidades de medida – podemos muito bem medir ambas as variáveis em unidades padrão.
def standard_units(xyz):
"Converta qualquer array de números em unidades padrão."
return (xyz - np.mean(xyz))/np.std(xyz)
heights_SU = Table().with_columns(
'MidParent SU', standard_units(heights.column('MidParent')),
'Child SU', standard_units(heights.column('Child'))
)
heights_SUheights_SU = Table().with_columns(
'MidParent SU', standard_units(heights.column('MidParent')),
'Child SU', standard_units(heights.column('Child'))
)
heights_SU| MidParent SU | Child SU |
|---|---|
| 3.45465 | 1.80416 |
| 3.45465 | 0.686005 |
| 3.45465 | 0.630097 |
| 3.45465 | 0.630097 |
| 2.47209 | 1.88802 |
| 2.47209 | 1.60848 |
| 2.47209 | -0.348285 |
| 2.47209 | -0.348285 |
| 1.58389 | 1.18917 |
| 1.58389 | 0.350559 |
Nesta escala, podemos calcular nossas previsões exatamente como antes. Mas primeiro temos que descobrir como converter nossa antiga definição de pontos “próximos” para um valor na nova escala. Dissemos que as alturas dos pais médios eram “próximos” se eles estivessem a 0,5 polegadas um do outro Como as unidades padrão medem distâncias em unidades de SDs, temos que descobrir quantos SDs da altura do pai médio correspondem a 0,5 polegadas.
Um SD de altura dos pais médios tem cerca de 1,8 polegadas. Portanto, 0,5 polegadas equivale a cerca de 0,28 SDs.
sd_midparent = np.std(heights.column(0))
sd_midparent| Out[1]: | 1.8014050969207571 |
0.5/sd_midparent| Out[2]: | 0.277561110965367 |
Agora estamos prontos para modificar nossa função de previsão para fazer previsões na escala de unidades padrão. Tudo o que mudou é que estamos usando a tabela de valores em unidades padrão e definindo “close” como acima.
def predict_child_su(mpht_su):
"""Retornar uma previsão da altura (em unidades padrão) de uma criança
cujos pais têm uma altura midparent de mpht_su em unidades padrão.
"""
close = 0.5/sd_midparent
close_points = heights_SU.where('MidParent SU', are.between(mpht_su-close, mpht_su + close))
return close_points.column('Child SU').mean()
heights_with_su_predictions = heights_SU.with_column(
'Prediction SU', heights_SU.apply(predict_child_su, 'MidParent SU')
)
heights_with_su_predictions.scatter('MidParent SU')
Este gráfico parece exatamente com o gráfico desenhado na escala original. Apenas os números nos eixos mudaram. Isso confirma que podemos entender o processo de previsão apenas trabalhando em unidades padrão.
Identificando a Linha em Unidades Padrão
O gráfico de dispersão acima tem uma forma oval – ou seja, é aproximadamente oval como uma bola de futebol americano. Nem todos os gráficos de dispersão são em forma de bola, nem mesmo aqueles que mostram associação linear. Mas nesta seção trabalharemos apenas com gráficos de dispersão em forma de bola. Na próxima seção, generalizaremos nossa análise para outras formas de gráficos.
Aqui está um gráfico de dispersão em forma de bola com ambas as variáveis medidas em unidades padrão. A linha de 45 graus está mostrada em vermelho.
r = 0.5
x_demo = np.random.normal(0, 1, 10000)
z_demo = np.random.normal(0, 1, 10000)
y_demo = r*x_demo + np.sqrt(1 - r**2)*z_demo
plots.figure(figsize=(6,6))
plots.xlim(-4, 4)
plots.ylim(-4, 4)
plots.scatter(x_demo, y_demo, s=10)
#plots.plot([-4, 4], [-4*0.6,4*0.6], color='g', lw=2)
plots.plot([-4,4],[-4,4], color='r', lw=2)
#plots.plot([1.5,1.5], [-4,4], color='k', lw=2)
plots.xlabel('x in standard units')
plots.ylabel('y in standard units');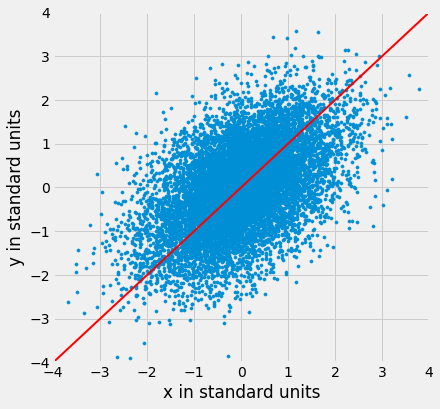
Mas a linha de 45 graus não é a linha que separa os centros das faixas verticais. Você pode ver isso na figura abaixo, onde a linha vertical em 1,5 unidades padrão é mostrada em preto. Os pontos no gráfico de dispersão próximos as todas as linhas pretas têm alturas aproximadamente na faixa de -2 a 3. A linha vermelha é muito alta para ser destacada no centro.
r = 0.5
x_demo = np.random.normal(0, 1, 10000)
z_demo = np.random.normal(0, 1, 10000)
y_demo = r*x_demo + np.sqrt(1 - r**2)*z_demo
plots.figure(figsize=(6,6))
plots.xlim(-4, 4)
plots.ylim(-4, 4)
plots.scatter(x_demo, y_demo, s=10)
#plots.plot([-4, 4], [-4*0.6,4*0.6], color='g', lw=2)
plots.plot([-4,4],[-4,4], color='r', lw=2)
plots.plot([1.5,1.5], [-4,4], color='k', lw=2)
plots.xlabel('x in standard units')
plots.ylabel('y in standard units');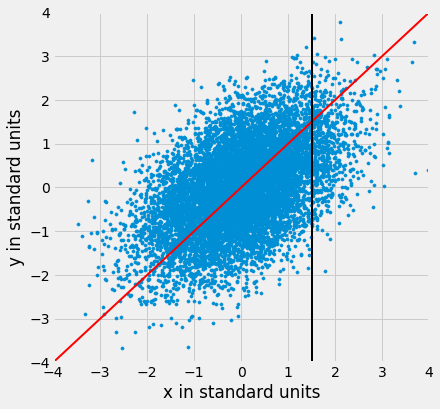
Portanto, a linha de 45 graus não é o “gráfico das médias”. Essa linha é a verde mostrada abaixo.
r = 0.5
x_demo = np.random.normal(0, 1, 10000)
z_demo = np.random.normal(0, 1, 10000)
y_demo = r*x_demo + np.sqrt(1 - r**2)*z_demo
plots.figure(figsize=(6,6))
plots.xlim(-4, 4)
plots.ylim(-4, 4)
plots.scatter(x_demo, y_demo, s=10)
plots.plot([-4, 4], [-4*0.6,4*0.6], color='g', lw=2)
plots.plot([-4,4],[-4,4], color='r', lw=2)
plots.plot([1.5,1.5], [-4,4], color='k', lw=2)
plots.xlabel('x in standard units')
plots.ylabel('y in standard units');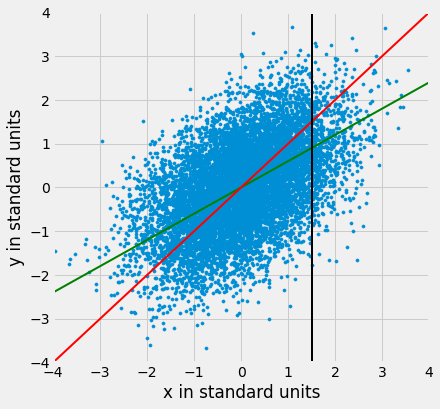
Ambas as linhas passam pela origem (0, 0). A linha verde passa pelos centros das faixas verticais (pelo menos aproximadamente) e é mais plana do que a linha vermelha de 45 graus.
A inclinação da linha de 45 graus é 1. Portanto, a inclinação da linha verde “gráfico das médias” é um valor positivo, mas menor que 1.
Que valor poderia ser esse? Você adivinhou – é r.
A Linha de Regressão, em Unidades Padronizadas
A linha verde “gráfico das médias” é chamada de linha de regressão, por um motivo que explicaremos em breve. Mas primeiro, vamos simular alguns gráficos de dispersão em forma de bola de futebol com diferentes valores de r, e ver como a linha muda. Em cada caso, a linha vermelha de 45 graus foi desenhada para comparação.
A função que realiza a simulação é chamada regression_line e recebe r como argumento.
def regression_line(r):
x = np.random.normal(0, 1, 10000)
z = np.random.normal(0, 1, 10000)
y = r*x + (np.sqrt(1-r**2))*z
plots.figure(figsize=(6, 6))
plots.xlim(-4, 4)
plots.ylim(-4, 4)
plots.scatter(x, y)
plots.plot([-4, 4], [-4*r,4*r], color='g', lw=2)
if r >= 0:
plots.plot([-4,4],[-4,4], lw=2, color='r')
else:
plots.plot([-4,4], [4,-4], lw=2, color='r')
regression_line(0.95)
regression_line(0.6)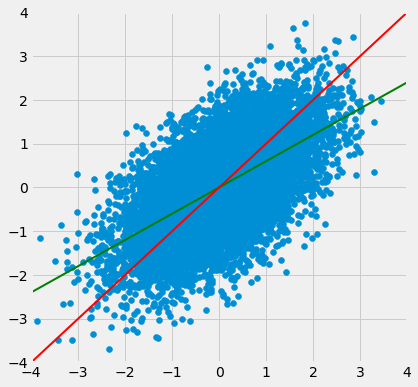
Quando r está próximo de 1, o gráfico de dispersão, a linha de 45 graus e a linha de regressão estão todas muito próximas umas das outras. Mas para valores mais moderados de r, a linha de regressão é perceptivelmente mais plana.
O Efeito de Regressão
Em termos de previsão, isso significa que para pais cuja altura média dos pais está em 1,5 unidades padrão, nossa previsão da altura do filho é um pouco menor do que 1,5 unidades padrão. Se a altura média dos pais for de 2 unidades padrão, prevemos que a altura do filho será um pouco menor do que 2 unidades padrão.
Em outras palavras, prevemos que o filho será um pouco mais próximo da média do que os pais. Isso é chamado de “regressão à média” e é como o nome regressão surge.
A regressão à média também funciona quando a altura média dos pais é abaixo da média. Filhos cuja altura média dos pais foi abaixo da média acabaram sendo um pouco mais altos em relação à sua geração, em média.
Em geral, indivíduos que estão afastados da média em uma variável esperam-se que estejam um pouco menos afastados da média em outra. Isso é chamado de efeito de regressão.
Lembre-se de que o efeito de regressão é uma afirmação sobre médias. Por exemplo, ele diz que se você pegar todos os filhos cuja altura média dos pais é de 1,5 unidades padrão, então a altura média dessas crianças é um pouco menos que 1,5 unidades padrão. Não diz que todas essas crianças serão um pouco menos que 1,5 unidades padrão em altura. Algumas serão mais altas e outras mais baixas. A média dessas alturas será menor que 1,5 unidades padrão.
A Equação da Linha de Regressão
Na regressão, usamos o valor de uma variável (que chamaremos de x) para prever o valor de outra (que chamaremos de y). Quando as variáveis x e y são medidas em unidades padrão, a linha de regressão para prever y com base em x tem inclinação r e passa pela origem. Assim, a equação da linha de regressão pode ser escrita como:
Nas unidades originais dos dados, isso se torna
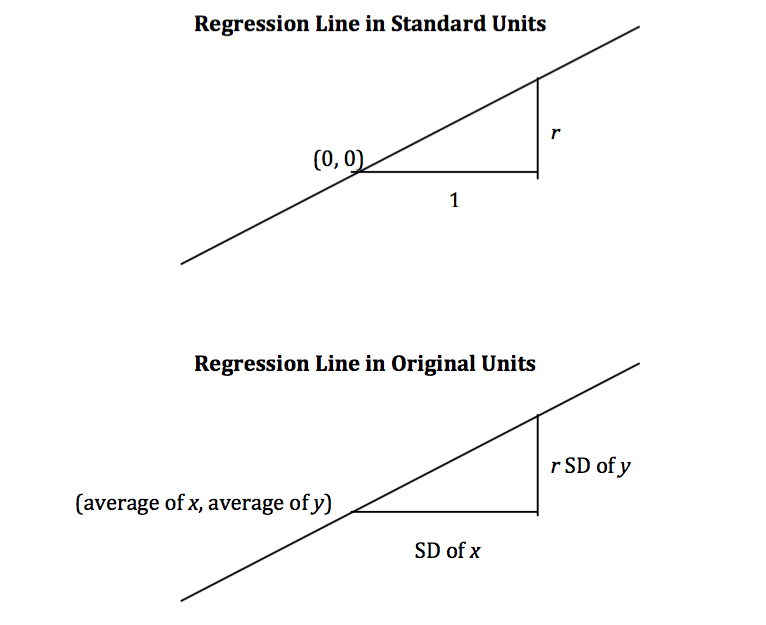
A inclinação e o intercepto da linha de regressão em unidades originais podem ser derivados do diagrama acima.
As três funções abaixo calculam a correlação, a inclinação e o intercepto. Todas elas recebem três argumentos: o nome da tabela, o rótulo da coluna contendo x, e o rótulo da coluna contendo y.
def correlation(t, label_x, label_y):
return np.mean(standard_units(t.column(label_x))*standard_units(t.column(label_y)))
def slope(t, label_x, label_y):
r = correlation(t, label_x, label_y)
return r*np.std(t.column(label_y))/np.std(t.column(label_x))
def intercept(t, label_x, label_y):
return np.mean(t.column(label_y)) - slope(t, label_x, label_y)*np.mean(t.column(label_x))
A linha de Regressão nas Unidades dos Dados
A correlação entre a altura dos pais médios e a altura da criança é de 0,32:
family_r = correlation(heights, 'MidParent', 'Child')
family_r| Out[3]: | 0.32094989606395924 |
Também podemos encontrar a equação da linha de regressão para prever a altura da criança com base na altura dos pais médios.
family_slope = slope(heights, 'MidParent', 'Child')
family_intercept = intercept(heights, 'MidParent', 'Child')
family_slope, family_intercept| Out[4]: | (0.637360896969479, 22.63624054958975) |
A equação da linha de regressão é
Isso também é conhecido como equação de regressão. O principal uso da equação de regressão é prever y com base em x.
Por exemplo, para uma altura média dos pais de 70.48 polegadas, a equação de regressão prevê que a altura da criança seja de 67.56 polegadas.
family_slope * 70.48 + family_intercept| Out[5]: | 67.55743656799862 |
Nossa previsão original, criada tomando a altura média de todas as crianças que tinham alturas dos pais médios próximas de 70,48, ficou bem próxima: 67,63 polegadas em comparação com a previsão da linha de regressão de 67,55 polegadas.
heights_with_predictions.where('MidParent', are.equal_to(70.48)).show(3)| MidParent | Child | Prediction |
|---|---|---|
| 70.48 | 74 | 67.6342 |
| 70.48 | 70 | 67.6342 |
| 70.48 | 68 | 67.6342 |
Aqui estão todas as linhas da tabela, juntamente com as nossas previsões originais e as novas previsões de regressão das alturas das crianças.
heights_with_predictions = heights_with_predictions.with_column(
'Regression Prediction', family_slope * heights.column('MidParent') + family_intercept
)
heights_with_predictions| MidParent | Child | Prediction | Regression Prediction |
|---|---|---|---|
| 75.43 | 73.2 | 70.1 | 70.7124 |
| 75.43 | 69.2 | 70.1 | 70.7124 |
| 75.43 | 69 | 70.1 | 70.7124 |
| 75.43 | 69 | 70.1 | 70.7124 |
| 73.66 | 73.5 | 70.4158 | 69.5842 |
| 73.66 | 72.5 | 70.4158 | 69.5842 |
| 73.66 | 65.5 | 70.4158 | 69.5842 |
| 73.66 | 65.5 | 70.4158 | 69.5842 |
| 72.06 | 71 | 68.5025 | 68.5645 |
| 72.06 | 68 | 68.5025 | 68.5645 |
heights_with_predictions.scatter('MidParent')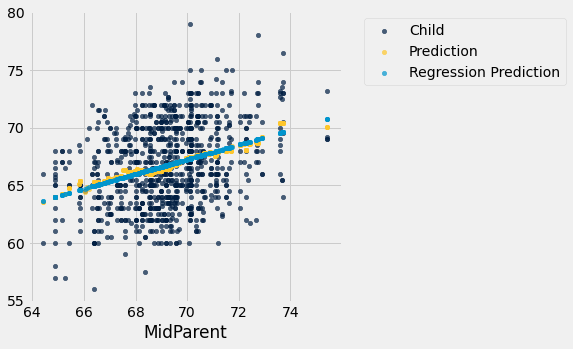
Os pontos cinza mostram as previsões de regressão, todos na linha de regressão. Observe como a linha está muito próxima do gráfico dourado das médias. Para estes dados, a linha de regressão faz um bom trabalho de aproximar os centros das faixas verticais.
Valores Ajustados
As previsões estão todas na linha e são conhecidas como “valores ajustados”. A função fit recebe o nome da tabela e os rótulos de x e y, e retorna uma matriz de valores ajustados, um para cada ponto no gráfico de dispersão.
def fit(table, x, y):
"""Retorna a altura da linha de regressão em cada valor de x."""
a = slope(table, x, y)
b = intercept(table, x, y)
return a * table.column(x) + b
É mais fácil ver a linha no gráfico abaixo do que no acima.
heights.with_column('Fitted', fit(heights, 'MidParent', 'Child')).scatter('MidParent')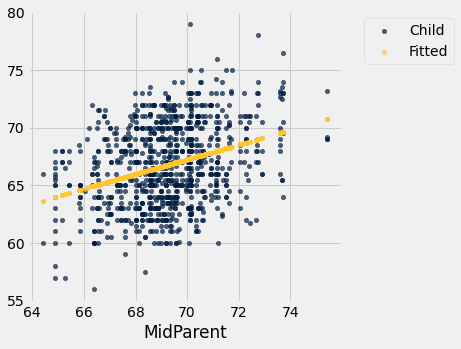
Outra maneira de traçar a linha é usar a opção fit_line=True com o método Table scatter.
heights.scatter('MidParent', fit_line=True)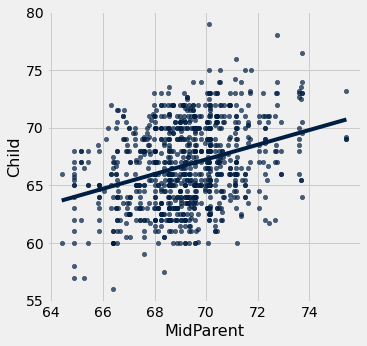
Unidades de Medida da Inclinação
A inclinação é uma razão, e vale a pena dedicar um momento para estudar as unidades em que ela é medida. Nosso exemplo vem do conjunto de dados familiar sobre mães que deram à luz em um sistema hospitalar. O gráfico de dispersão dos pesos da gravidez versus alturas se parece com uma bola de futebol que foi usada em muitos jogos, mas é próxima o suficiente de uma bola de futebol para que possamos justificar colocar nossa linha ajustada nela. Nas seções posteriores veremos como tornar essas justificativas mais formais.
baby = Table.read_table(path_data + 'baby.csv')
baby.scatter('Maternal Height', 'Maternal Pregnancy Weight', fit_line=True)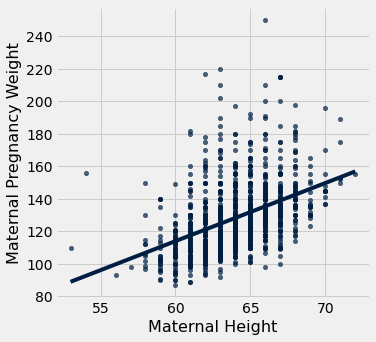
slope(baby, 'Maternal Height', 'Maternal Pregnancy Weight')| Out[6]: | 3.572846259275056 |
A inclinação da linha de regressão é de 3,57 libras por polegada. Isso significa que, para duas mulheres que têm 1 polegada de diferença na altura, nossa previsão do peso durante a gravidez será diferente em 3,57 libras. Para uma mulher que é 2 polegadas mais alta do que outra, nossa previsão do peso durante a gravidez será
libras a mais do que nossa previsão para a mulher mais baixa.
Observe que as faixas verticais sucessivas no gráfico de dispersão estão separadas por uma polegada, porque as alturas foram arredondadas para a polegada mais próxima. Outra maneira de pensar na inclinação é pegar duas faixas consecutivas (que estão necessariamente a 1 polegada de distância), correspondendo a dois grupos de mulheres separados por 1 polegada de altura. A inclinação de 3,57 libras por polegada significa que o peso médio durante a gravidez do grupo mais alto é cerca de 3,57 libras maior do que o do grupo mais baixo.
Exemplo
Suponha que nosso objetivo seja usar regressão para estimar a altura de um basset hound com base em seu peso, usando uma amostra que parece consistente com o modelo de regressão. Suponha que a correlação observada r seja 0,5, e que as estatísticas resumidas para as duas variáveis sejam conforme a tabela abaixo:
| média | SD | |
|---|---|---|
| altura | 14 polegadas | 2 polegadas |
| peso | 50 libras | 5 libras |
Para calcular a equação da linha de regressão, precisamos da inclinação e do intercepto.
A equação da linha de regressão nos permite calcular a altura estimada, em polegadas, com base em um peso dado em libras:
A inclinação da linha mede o aumento na altura estimada por unidade de aumento no peso. A inclinação é positiva, e é importante notar que isso não significa que achamos que os basset hounds ficam mais altos se ganharem peso. A inclinação reflete a diferença nas alturas médias de dois grupos de cães que estão a 1 libra de distância no peso. Especificamente, considere um grupo de cães cujo peso seja w libras, e o grupo cujo peso seja w+1 libras. Estima-se que o segundo grupo seja em média 0,2 polegadas mais alto. Isso é verdade para todos os valores de w na amostra.
Em geral, a inclinação da linha de regressão pode ser interpretada como o aumento médio em y por unidade de aumento em x. Note que se a inclinação for negativa, então para cada unidade de aumento em x, a média de y diminui.
Nota Final
Mesmo que não estabeleçamos a base matemática para a equação de regressão, podemos ver que ela fornece previsões bastante boas quando o gráfico de dispersão tem a forma de uma bola de futebol. É um fato matemático surpreendente que, independentemente da forma do gráfico de dispersão, a mesma equação fornece o “melhor” entre todas as linhas retas. Esse é o tema da próxima seção.
| ← Capítulo 15.1 – Correlação | Capítulo 15.3 – Método dos Mínimos Quadrados → |