
Capítulo 5
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
path_data = '../../assets/data/'
Sequências
Os valores podem ser agrupados em coleções, o que permite aos programadores organizar esses valores e referir-se a todos eles com um único nome. Ao agrupar valores, podemos escrever um código que realiza um cálculo em muitos dados de uma só vez.
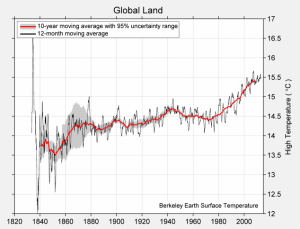
Chamar a função make_array em vários valores os coloca em um array, que é um tipo de coleção sequencial. Abaixo, coletamos quatro temperaturas diferentes em um array chamado highs. Estas são as temperaturas médias diárias máximas estimadas sobre toda a terra na Terra (em graus Celsius) para as décadas em torno de 1850, 1900, 1950 e 2000, respectivamente,
expressas como desvios da temperatura média absoluta máxima entre 1951 e 1980, que foi de 14.48 graus.
baseline_high = 14.48
highs = make_array(baseline_high - 0.880, baseline_high - 0.093,
baseline_high + 0.105, baseline_high + 0.684)
highs| Out[2]: | array([13.6 , 14.387, 14.585, 15.164]) |
Coleções nos permitem passar múltiplos valores para uma função usando um único nome. Por exemplo, a função sum calcula a soma de todos os valores em uma coleção, e a função len calcula o seu comprimento. (Isso é o número de valores que colocamos nela.) Usando-as juntas, podemos calcular a média de uma coleção.
sum(highs)/len(highs)| Out[3]: | 14.434000000000001 |
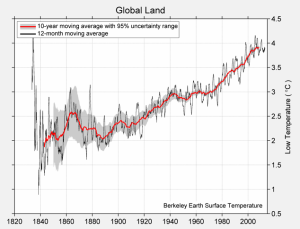
O gráfico completo das temperaturas máximas e mínimas diárias aparece abaixo.
Média de alta temperatura diária
Média de temperatura baixa diária
| ← Capítulo 4.3 – Comparações | Capítulo 5.1 – Arrays → |