
Capítulo 15
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
import matplotlib
path_data = '../../assets/data/'
matplotlib.use('Agg')
%matplotlib inline
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
import numpy as np
Previsão
Um aspecto importante da ciência de dados é descobrir o que os dados podem nos dizer sobre o futuro. O que os dados sobre clima e poluição indicam sobre as temperaturas daqui a algumas décadas? Com base no perfil de internet de uma pessoa, quais sites têm maior probabilidade de interessá-la? Como o histórico médico de um paciente pode ser usado para avaliar como ele ou ela responderá a um tratamento?
Para responder a essas perguntas, os cientistas de dados desenvolveram métodos para fazer previsões. Neste capítulo, estudaremos uma das maneiras mais comumente usadas de prever o valor de uma variável com base no valor de outra.
Aqui está um conjunto de dados históricos usado para prever as alturas de adultos com base nas alturas de seus pais. Estudamos este conjunto de dados em uma seção anterior. A tabela heights contém dados sobre a altura dos pais e a altura dos filhos (ambos em polegadas) para uma população de 934 “filhos” adultos. Lembre-se de que a altura dos pais é uma média das alturas dos dois pais.
# Dados sobre a altura dos pais e dos filhos adultos
original = Table.read_table(path_data + 'family_heights.csv')
heights = Table().with_columns(
'MidParent', original.column('midparentHeight'),
'Child', original.column('childHeight')
)
heights| MidParent | Child |
|---|---|
| 75.43 | 73.2 |
| 75.43 | 69.2 |
| 75.43 | 69 |
| 75.43 | 69 |
| 73.66 | 73.5 |
| 73.66 | 72.5 |
| 73.66 | 65.5 |
| 73.66 | 65.5 |
| 72.06 | 71 |
| 72.06 | 68 |
heights.scatter('MidParent')
Uma das principais razões para estudar os dados foi poder prever a altura de um adulto de um filho nascido de pais semelhantes aos do conjunto de dados. Fizemos essas previsões na Seção 8.1, após notarmos a associação positiva entre as duas variáveis.
Nossa abordagem foi basear a previsão em todos os pontos que correspondem a uma altura de pais médios próxima à altura de pais médios da nova pessoa. Para isso, escrevemos uma função chamada predict_child que recebe uma altura de pais médios como argumento e retorna a altura média de todas as crianças que tiveram alturas de pais médios dentro de meio polegada do argumento.
def predict_child(mpht):
"""Retorna uma previsão da altura de uma criança
cujos pais têm altura média de mpht.
A previsão é a altura média das crianças
cuja altura média dos pais está na faixa de mpht mais ou menos 0,5 polegadas.
"""
close_points = heights.where('MidParent', are.between(mpht-0.5, mpht + 0.5))
return close_points.column('Child').mean()
Aplicamos a função à coluna de alturas Midparent e visualizamos o resultado.
# Aplique predizer_child a todas as alturas do pai médio
heights_with_predictions = heights.with_column(
'Prediction', heights.apply(predict_child, 'MidParent')
)
# Desenhe o gráfico de dispersão original junto com os valores previstos
heights_with_predictions.scatter('MidParent')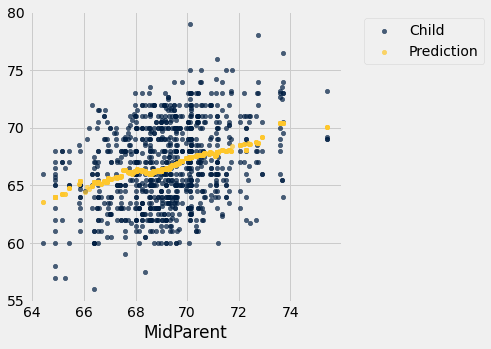
A previsão em uma determinada altura do meio-pai fica aproximadamente no centro da faixa vertical de pontos na altura dada. Este método de previsão é chamado de regressão. Mais tarde neste capítulo veremos se podemos evitar nossas definições arbitrárias de “proximidade” sendo “dentro de 0,5 polegadas”. Mas primeiro desenvolveremos uma medida que pode ser usada em muitos ambientes para decidir quão boa uma variável será como preditora de outra.
| ← Capítulo 14.6 – Escolhendo um Tamanho de Amostra | Capítulo 15.1 – Correlação → |