
Capítulo 15.1
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
%matplotlib inline
path_data = '../../../assets/data/'
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
import math
import numpy as np
from scipy import stats
Correlação
Nesta seção, desenvolveremos uma medida de quão fortemente agrupado um diagrama de dispersão está em relação a uma linha reta. Formalmente, isso é chamado de medição de associação linear.
def r_scatter(r):
plots.figure(figsize=(5,5))
"Gere um gráfico de dispersão com uma correlação aproximadamente r"
x = np.random.normal(0, 1, 1000)
z = np.random.normal(0, 1, 1000)
y = r*x + (np.sqrt(1-r**2))*z
plots.scatter(x, y)
plots.xlim(-4, 4)
plots.ylim(-4, 4)
A tabela hybrid contém dados sobre carros híbridos de passageiros vendidos nos Estados Unidos de 1997 a 2013. Os dados foram adaptados do arquivo de dados online do Prof. Larry Winner da Universidade da Flórida. As colunas são:
vehicle: modelo do carroyear: ano de fabricaçãomsrp: preço de varejo sugerido pelo fabricante em dólares de 2013acceleration: taxa de aceleração em km por hora por segundompg: economia de combustível em milhas por galãoclass: classe do modelo.
hybrid = Table.read_table(path_data + 'hybrid.csv')
hybrid| vehicle | year | msrp | acceleration | mpg | class |
|---|---|---|---|---|---|
| Prius (1st Gen) | 1997 | 24509.7 | 7.46 | 41.26 | Compact |
| Tino | 2000 | 35355 | 8.2 | 54.1 | Compact |
| Prius (2nd Gen) | 2000 | 26832.2 | 7.97 | 45.23 | Compact |
| Insight | 2000 | 18936.4 | 9.52 | 53 | Two Seater |
| Civic (1st Gen) | 2001 | 25833.4 | 7.04 | 47.04 | Compact |
| Insight | 2001 | 19036.7 | 9.52 | 53 | Two Seater |
| Insight | 2002 | 19137 | 9.71 | 53 | Two Seater |
| Alphard | 2003 | 38084.8 | 8.33 | 40.46 | Minivan |
| Insight | 2003 | 19137 | 9.52 | 53 | Two Seater |
| Civic | 2003 | 14071.9 | 8.62 | 41 | Compact |
O gráfico abaixo é um gráfico de dispersão de msrp versus acceleration. Isso significa que msrp é plotado no eixo vertical e accelaration na horizontal.
hybrid.scatter('acceleration', 'msrp')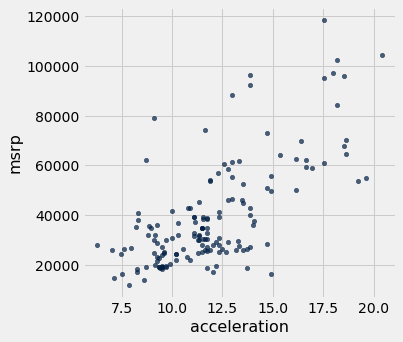
Observe a associação positiva. A dispersão dos pontos está inclinada para cima, indicando que os carros com maior aceleração tendem a custar mais, em média; por outro lado, os carros que custam mais tendem a ter maior aceleração, em média.
O diagrama de dispersão de MSRP versus quilometragem mostra uma associação negativa. Carros híbridos com maior quilometragem tendem a custar menos, em média. Isso parece surpreendente até que você considere que carros que aceleram rapidamente tendem a ser menos eficientes em termos de combustível e têm menor quilometragem. Como o gráfico de dispersão anterior mostrou, esses também eram os carros que tendiam a custar mais.
hybrid.scatter('mpg', 'msrp')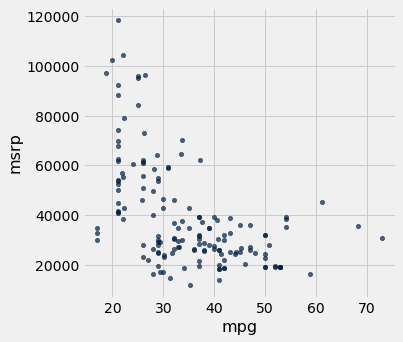
Juntamente com a associação negativa, o diagrama de dispersão de preço versus eficiência mostra uma relação não linear entre as duas variáveis. Os pontos parecem estar agrupados em torno de uma curva, não em torno de uma linha reta.
Se restringirmos os dados apenas à classe SUV, no entanto, a associação entre preço e eficiência ainda é negativa, mas a relação parece ser mais linear. A relação entre preço e aceleração dos SUV também mostra uma tendência linear, mas com uma inclinação positiva.
suv = hybrid.where('class', 'SUV')
suv.scatter('mpg', 'msrp')
suv.scatter('acceleration', 'msrp')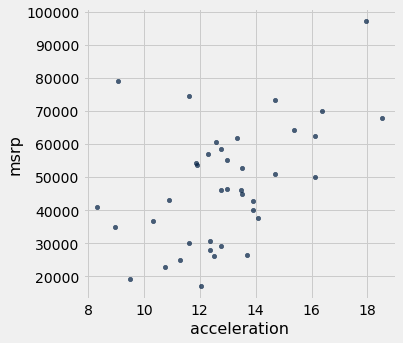
Você deve ter notado que podemos derivar informações úteis da orientação geral e da forma de um diagrama de dispersão mesmo sem prestar atenção às unidades em que as variáveis foram medidas.
De fato, poderíamos plotar todas as variáveis em unidades padrão e os gráficos teriam a mesma aparência. Isso nos dá uma maneira de comparar o grau de linearidade em dois diagramas de dispersão.
Lembre-se de que em uma seção anterior definimos a função standard_units para converter uma matriz de números em unidades padrão.
def standard_units(any_numbers):
"Converte qualquer matriz de números em unidades padrão."
return (any_numbers - np.mean(any_numbers))/np.std(any_numbers)
Podemos usar esta função para redesenhar os dois diagramas de dispersão para os SUVs, com todas as variáveis medidas em unidades padrão.
Table().with_columns(
'mpg (standard units)', standard_units(suv.column('mpg')),
'msrp (standard units)', standard_units(suv.column('msrp'))
).scatter(0, 1)
plots.xlim(-3, 3)
plots.ylim(-3, 3);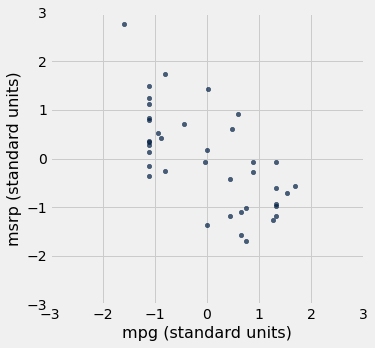
Table().with_columns(
'acceleration (standard units)', standard_units(suv.column('acceleration')),
'msrp (standard units)', standard_units(suv.column('msrp'))
).scatter(0, 1)
plots.xlim(-3, 3)
plots.ylim(-3, 3);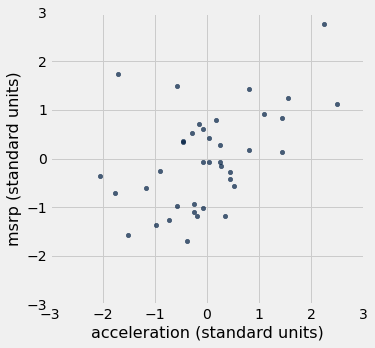
As associações que vemos nestes gráficos são as mesmas que vimos antes. Além disso, como os dois diagramas de dispersão agora são desenhados exatamente na mesma escala, podemos ver que a relação linear no segundo diagrama é um pouco mais difusa do que no primeiro.
Agora definiremos uma medida que usa unidades padrão para quantificar os tipos de associação que vimos.
O coeficiente de correlação
O coeficiente de correlação mede a força da relação linear entre duas variáveis. Graficamente, ele mede o quão agrupado está o diagrama de dispersão em torno de uma linha reta.
O termo coeficiente de correlação não é fácil de dizer, então geralmente é abreviado para correlação e denotado por r.
Aqui estão alguns fatos matemáticos sobre r que vamos observar por simulação.
- O coeficiente de correlação r é um número entre -1 e 1.
- r mede até que ponto o diagrama de dispersão se agrupa em torno de uma linha reta.
- r = 1 se o diagrama de dispersão for uma linha reta perfeita inclinada para cima, e r = -1 se o diagrama de dispersão for uma linha reta perfeita inclinada para baixo.
A função r_scatter recebe um valor de r como argumento e simula um gráfico de dispersão com uma correlação muito próxima de r. Devido à aleatoriedade na simulação, não se espera que a correlação seja exatamente igual a r.
Chame r_scatter algumas vezes, com diferentes valores de r como argumento, e veja como o gráfico de dispersão muda.
Quando r=1, o gráfico de dispersão é perfeitamente linear e inclinado para cima. Quando r=-1, o gráfico de dispersão é perfeitamente linear e inclinado para baixo. Quando r=0, o gráfico de dispersão é uma nuvem amorfa em torno do eixo horizontal, e as variáveis são ditas não correlacionadas.
r_scatter(0.9)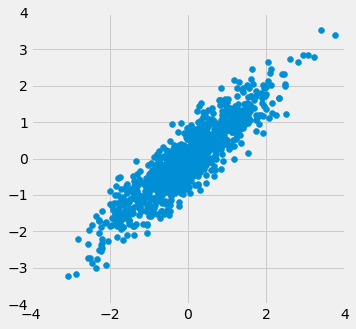
r_scatter(0.25)
r_scatter(0)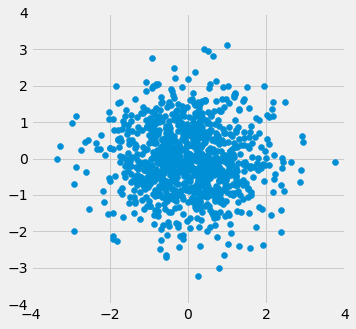
r_scatter(-0.55)
Calculando r
A fórmula para r não é aparente a partir de nossas observações até agora. Ela possui uma base matemática que está fora do escopo desta aula. No entanto, como veremos, o cálculo é direto e nos ajuda a entender várias das propriedades de r.
Fórmula para r:
r é a média dos produtos das duas variáveis, quando ambas as variáveis são medidas em unidades padrão.
Aqui estão os passos no cálculo. Vamos aplicar os passos a uma tabela simples de valores de x e y.
x = np.arange(1, 7, 1)
y = make_array(2, 3, 1, 5, 2, 7)
t = Table().with_columns(
'x', x,
'y', y
)
t| x | y |
|---|---|
| 1 | 2 |
| 2 | 3 |
| 3 | 1 |
| 4 | 5 |
| 5 | 2 |
| 6 | 7 |
Com base no diagrama de dispersão, esperamos que r seja positivo, mas não igual a 1.
t.scatter(0, 1, s=30, color='red')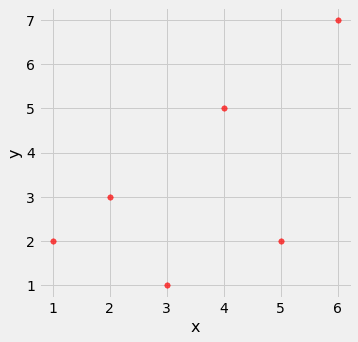
Passo 1. Converta cada variável em unidades padrão.
t_su = t.with_columns(
'x (standard units)', standard_units(x),
'y (standard units)', standard_units(y)
)
t_su| x | y | x (standard units) | y (standard units) |
|---|---|---|---|
| 1 | 2 | -1.46385 | -0.648886 |
| 2 | 3 | -0.87831 | -0.162221 |
| 3 | 1 | -0.29277 | -1.13555 |
| 4 | 5 | 0.29277 | 0.811107 |
| 5 | 2 | 0.87831 | -0.648886 |
| 6 | 7 | 1.46385 | 1.78444 |
Passo 2. Multiplique cada par de unidades padrão.
t_product = t_su.with_column('product of standard units', t_su.column(2) * t_su.column(3))
t_product| x | y | x (standard units) | y (standard units) | product of standard units |
|---|---|---|---|---|
| 1 | 2 | -1.46385 | -0.648886 | 0.949871 |
| 2 | 3 | -0.87831 | -0.162221 | 0.142481 |
| 3 | 1 | -0.29277 | -1.13555 | 0.332455 |
| 4 | 5 | 0.29277 | 0.811107 | 0.237468 |
| 5 | 2 | 0.87831 | -0.648886 | -0.569923 |
| 6 | 7 | 1.46385 | 1.78444 | 2.61215 |
Passo 3. r é a média dos produtos computados no Passo 2.
# r é a média dos produtos das unidades padrão
r = np.mean(t_product.column(4))
r| Out[1]: | 0.6174163971897709 |
Como esperado, r é positivo, mas não é igual a 1.
Propriedades de r
O cálculo mostra que:
- r é um número puro. Ele não possui unidades. Isso ocorre porque r é baseado em unidades padrão.
- r não é afetado pela mudança de unidades em nenhum dos eixos. Isso também ocorre porque r é baseado em unidades padrão.
- r não é afetado pela troca dos eixos. Algebraicamente, isso ocorre porque o produto das unidades padrão não depende de qual variável é chamada de x e qual é y. Geometricamente, a troca de eixos reflete o gráfico de dispersão em relação à linha y=x, mas não altera a quantidade de agrupamento nem o sinal da associação.
t.scatter('y', 'x', s=30, color='red')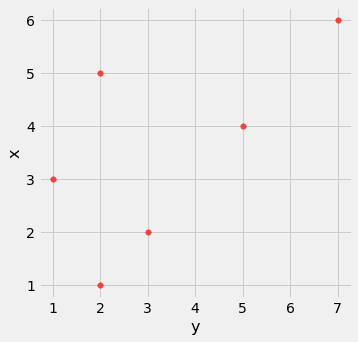
A função correlation
Estaremos calculando correlações repetidamente, então será útil definir uma função que as calcule executando todas as etapas descritas acima. Vamos definir uma função correlation que recebe uma tabela e os rótulos de duas colunas no tabela. A função retorna r, a média dos produtos desses valores de coluna em unidades padrão.
def correlation(t, x, y):
return np.mean(standard_units(t.column(x))*standard_units(t.column(y)))
Vamos chamar a função nas colunas x e y de t. A função retorna a mesma resposta para a correlação entre x e y que obtivemos pela aplicação direta de a fórmula para r.
correlation(t, 'x', 'y')| Out[2]: | 0.6174163971897709 |
Como notamos, a ordem em que as variáveis são especificadas não importa.
correlation(t, 'y', 'x')| Out[3]: | 0.6174163971897709 |
Chamar correlation nas colunas da tabela suv nos dá a correlação entre preço e quilometragem, bem como a correlação entre preço e aceleração.
correlation(suv, 'mpg', 'msrp')| Out[4]: | -0.6667143635709919 |
correlation(suv, 'acceleration', 'msrp')| Out[5]: | 0.48699799279959155 |
Esses valores confirmam o que tínhamos observado:
- Existe uma associação negativa entre preço e eficiência, enquanto a associação entre preço e aceleração é positiva.
- A relação linear entre preço e aceleração é um pouco mais fraca (correlação cerca de 0,5) do que entre preço e quilometragem (correlação cerca de -0,67).
Correlação é um conceito simples e poderoso, mas às vezes é mal utilizado. Antes de usar r, é importante estar ciente do que a correlação mede e do que não mede.
Associação não implica Causalidade
Correlação mede apenas associação. Correlação não implica causalidade. Embora a correlação entre o peso e a habilidade matemática das crianças em um distrito escolar possa ser positiva, isso não significa que fazer matemática faça as crianças ficarem mais pesadas ou que ganhar peso melhore as habilidades matemáticas das crianças. Idade é uma variável de confusão: crianças mais velhas são tanto mais pesadas quanto melhores em matemática do que crianças mais novas, em média.
Correlação Mede Associação Linear
Correlação mede apenas um tipo de associação – linear. Variáveis que têm forte associação não linear podem ter correlação muito baixa. Aqui está um exemplo de variáveis que têm uma relação quadrática perfeita y = x^2, mas têm correlação igual a 0.
new_x = np.arange(-4, 4.1, 0.5)
nonlinear = Table().with_columns(
'x', new_x,
'y', new_x**2
)
nonlinear.scatter('x', 'y', s=30, color='r')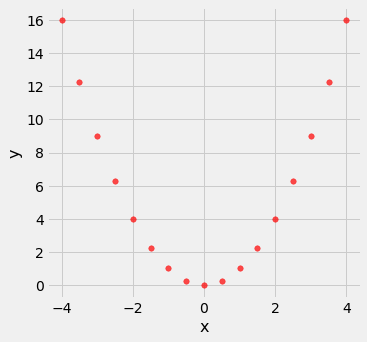
correlation(nonlinear, 'x', 'y')| Out[6]: | 0.0 |
A Correlação é Afetada por Outliers
Outliers podem ter um grande efeito na correlação. Aqui está um exemplo onde um gráfico de dispersão para o qual r é igual a 1 é transformado em um gráfico para o qual r é igual a 0, pela adição de apenas um ponto periférico .
line = Table().with_columns(
'x', make_array(1, 2, 3, 4),
'y', make_array(1, 2, 3, 4)
)
line.scatter('x', 'y', s=30, color='r')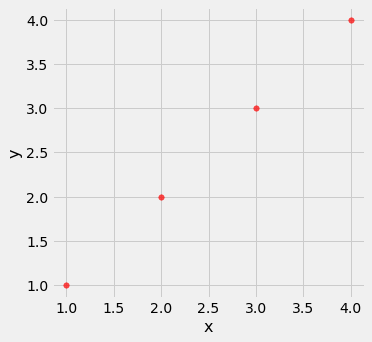
correlation(line, 'x', 'y')| Out[7]: | 1.0 |
outlier = Table().with_columns(
'x', make_array(1, 2, 3, 4, 5),
'y', make_array(1, 2, 3, 4, 0)
)
outlier.scatter('x', 'y', s=30, color='r')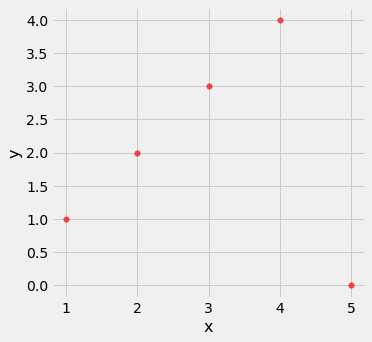
correlation(outlier, 'x', 'y')| Out[8]: | 0.0 |
As Correlações Ecológicas devem ser Interpretadas com Cuidado
Correlações baseadas em dados agregados podem ser enganosas. Como exemplo, aqui estão dados sobre as pontuações do SAT de Leitura Crítica e Matemática em 2014. Há um ponto para cada um dos 50 estados e um para Washington, D.C. A coluna Taxa de Participação contém a porcentagem de alunos do último ano do ensino médio que fizeram o teste. As três próximas colunas mostram a pontuação média no estado em cada parte do teste, e a coluna final é a média das pontuações totais no teste.
sat2014 = Table.read_table(path_data + 'sat2014.csv').sort('State')
sat2014| State | Participation Rate | Critical Reading | Math | Writing | Combined |
|---|---|---|---|---|---|
| Alabama | 6.7 | 547 | 538 | 532 | 1617 |
| Alaska | 54.2 | 507 | 503 | 475 | 1485 |
| Arizona | 36.4 | 522 | 525 | 500 | 1547 |
| Arkansas | 4.2 | 573 | 571 | 554 | 1698 |
| California | 60.3 | 498 | 510 | 496 | 1504 |
| Colorado | 14.3 | 582 | 586 | 567 | 1735 |
| Connecticut | 88.4 | 507 | 510 | 508 | 1525 |
| Delaware | 100 | 456 | 459 | 444 | 1359 |
| District of Columbia | 100 | 440 | 438 | 431 | 1309 |
| Florida | 72.2 | 491 | 485 | 472 | 1448 |
O diagrama de dispersão das pontuações em matemática versus pontuações em leitura crítica está fortemente agrupado em torno de uma linha reta; a correlação é próxima de 0,985.
sat2014.scatter('Critical Reading', 'Math')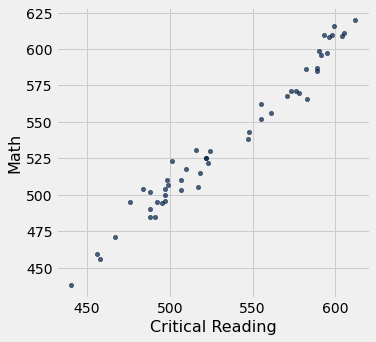
correlation(sat2014, 'Critical Reading', 'Math')| Out[9]: | 0.9847558411067434 |
Isso é uma correlação extremamente alta. Mas é importante observar que isso não reflete a força da relação entre as pontuações de Matemática e Leitura Crítica dos estudantes.
Os dados consistem em pontuações médias em cada estado. Mas os estados não fazem os testes – os estudantes sim. Os dados na tabela foram criados agrupando todos os estudantes de cada estado em um único ponto nas médias das duas variáveis naquele estado. Mas nem todos os estudantes no estado estarão nesse ponto, pois os estudantes variam em seu desempenho. Se você plotar um ponto para cada estudante em vez de apenas um para cada estado, haverá uma nuvem de pontos em torno de cada ponto na figura acima. A imagem geral será mais difusa. A correlação entre as pontuações de Matemática e Leitura Crítica dos estudantes será menor do que o valor calculado com base nas médias estaduais.
Correlações baseadas em agregações e médias são chamadas de correlações ecológicas e são frequentemente relatadas. Como acabamos de ver, elas devem ser interpretadas com cuidado.
Sério ou irônico?
Em 2012, um artigo no respeitado New England Journal of Medicine examinou a relação entre o consumo de chocolate e os Prêmios Nobel em um grupo de países. A Scientific American respondeu seriamente, enquanto outros foram mais descontraídos. Você é livre para tomar sua própria decisão! O seguinte gráfico, fornecido no artigo, deve motivá-lo a ir dar uma olhada.
from IPython.display import Image
Image("../../../images/chocoNobel.png")
| ← Capítulo 15 – Previsão | Capítulo 15.2 – Linha de Regressão → |