
Capítulo 7.3
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
import numpy as np
path_data = '../../../assets/data/'
%matplotlib inline
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')Gráficos Sobrepostos
Neste capítulo, aprendemos como visualizar dados desenhando gráficos. Um uso comum dessas visualizações é comparar dois conjuntos de dados. Nesta seção, veremos como sobrepor gráficos, ou seja, desenhá-los em um único gráfico em um par comum de eixos.
Para que a sobreposição faça sentido, os gráficos que estão sendo sobrepostos devem representar as mesmas variáveis e serem medidos nas mesmas unidades.
Para desenhar gráficos sobrepostos, os métodos scatter, plot e barh podem ser chamados da mesma maneira. Para scatter e plot, uma coluna deve servir como o eixo horizontal comum para todos os gráficos sobrepostos. Para barh, uma coluna deve servir como o eixo comum que é o conjunto de categorias. A chamada geral parece assim:
name_of_table.method(column_label_of_common_axis, array_of_labels_of_variables_to_plot)
Mais comumente, primeiro selecionaremos apenas as colunas necessárias para nosso gráfico e depois chamaremos o método especificando apenas a variável no eixo comum:
name_of_table.method(column_label_of_common_axis)
Gráficos de Dispersão Sobrepostos
A tabela sons_heights faz parte de um conjunto de dados históricos sobre as alturas de pais e seus filhos. Especificamente, a população consiste em 179 homens que foram os primeiros nascidos em suas famílias. Os dados são suas próprias alturas e as alturas de seus pais. Todas as alturas foram medidas em polegadas.
sons_heights = Table.read_table(path_data + 'sons_heights.csv')
sons_heights| father | mother | son |
|---|---|---|
| 78.5 | 67.0 | 73.2 |
| 75.5 | 66.5 | 73.5 |
| 75.0 | 64.0 | 71.0 |
| 75.0 | 64.0 | 70.5 |
| 75.0 | 58.5 | 72.0 |
| 74.0 | 68.0 | 76.5 |
| 74.0 | 62.0 | 74.0 |
| 73.0 | 67.0 | 71.0 |
| 73.0 | 67.0 | 68.0 |
| 73.0 | 66.5 | 71.0 |
| … (169 rows omitted) | ||
O método scatter nos permite visualizar como as alturas dos filhos estão relacionadas às alturas de ambos os pais. No gráfico, as alturas dos filhos formarão o eixo horizontal comum.
sons_heights.scatter('son')
Repare como especificamos apenas a variável (alturas dos filhos) no eixo horizontal comum. O Python desenhou dois gráficos de dispersão: um para a relação entre essa variável e as outras duas.
Cada ponto representa uma linha da tabela, ou seja, um trio “pai, mãe, filho”. Para todos os pontos, o eixo horizontal representa a altura do filho. Nos pontos azuis, o eixo vertical representa a altura do pai. Nos pontos dourados, o eixo vertical representa as alturas da mãe.
Tanto o gráfico de dispersão em dourado quanto o azul têm inclinação para cima e mostram uma associação positiva entre as alturas dos filhos e as alturas de ambos os pais. O gráfico azul (dos pais) é geralmente mais alto que o dourado, porque os pais eram, em geral, mais altos que as mães.
Gráficos de linhas sobrepostas
O próximo exemplo envolve dados sobre crianças de tempos mais recentes. Voltaremos à tabela de dados do Censo us_pop, criada novamente abaixo para referência. A partir desta tabela, extrairemos a contagem de todas as crianças em cada uma das faixas etárias de 0 a 18 anos.
# Leia a tabela completa do Censo
data = 'http://www2.census.gov/programs-surveys/popest/technical-documentation/file-layouts/2010-2019/nc-est2019-agesex-res.csv'
full_census_table = Table.read_table(data)
# Selecione colunas da tabela completa e renomeie algumas delas
partial_census_table = full_census_table.select('SEX', 'AGE', 'POPESTIMATE2014', 'POPESTIMATE2019')
us_pop = partial_census_table.relabeled('POPESTIMATE2014', '2014').relabeled('POPESTIMATE2019', '2019')
# Acesse as linhas correspondentes a todas as crianças de 0 a 18 anos
children = us_pop.where('SEX', are.equal_to(0)).where('AGE', are.below(19)).drop('SEX')
children.show()| AGE | 2014 | 2019 |
|---|---|---|
| 0 | 3954787 | 3783052 |
| 1 | 3948891 | 3829599 |
| 2 | 3958711 | 3922044 |
| 3 | 4005928 | 3998665 |
| 4 | 4004032 | 4043323 |
| 5 | 4004576 | 4028281 |
| 6 | 4133372 | 4017227 |
| 7 | 4152666 | 4022319 |
| 8 | 4118349 | 4066194 |
| 9 | 4106068 | 4061874 |
| 10 | 4114558 | 4060940 |
| 11 | 4084457 | 4189261 |
| 12 | 4067187 | 4208387 |
| 13 | 4168095 | 4175221 |
| 14 | 4231353 | 4164459 |
| 15 | 4162828 | 4175459 |
| 16 | 4165925 | 4150420 |
| 17 | 4181940 | 4142425 |
| 18 | 4221344 | 4255827 |
Podemos agora desenhar dois gráficos de linhas sobrepostas, mostrando o número de crianças nas diferentes faixas etárias para cada um dos anos de 2014 e 2019. A chamada é análoga à chamada de scatter no exemplo anterior.
children.plot('AGE')
Embora os rótulos do eixo horizontal incluam alguns números meio-inteiros, é importante lembrar que só temos dados nas idades de 0, 1, 2, e assim por diante. Os gráficos de linha “unem os pontos” entre eles.
Os dois gráficos se cruzam em alguns lugares. Por exemplo, houve mais crianças de 6 anos em 2014 do que em 2019, e houve mais crianças de 12 anos em 2019 do que em 2014.
É claro que as crianças de 12 anos em 2019 consistem principalmente nas crianças que tinham 7 anos em 2014. Para ver isso nos gráficos, compare o gráfico dourado na AGE 12 e o gráfico azul na AGE 7. Você perceberá que o gráfico dourado (2019) se parece muito com o gráfico azul (2014) deslocado para a direita em 5 anos. O deslocamento é acompanhado por um leve aumento devido ao efeito líquido das crianças que entraram no país entre 2014 e 2019 superando aquelas que saíram. Felizmente, nessas idades, não há muita perda de vida.
Gráficos de Barras
A Fundação Kaiser Family compilou dados do Censo sobre a distribuição de raça e etnia nos EUA. O site da Fundação fornece compilações de dados para toda a população dos EUA em 2019, bem como para crianças nos EUA que tinham menos de 18 anos naquele ano.
A tabela usa_ca é adaptada de seus dados para os Estados Unidos e Califórnia. As colunas representam todos nos EUA, todos na Califórnia, crianças nos EUA e crianças na Califórnia.
O corpo da tabela contém porcentagens nas diferentes categorias. Cada coluna mostra a distribuição da variável Ethnicity/Race no grupo de pessoas correspondente a essa coluna. Então em cada coluna, as entradas somam 100. A categoria API consiste em asiáticos e ilhéus do Pacífico, incluindo havaianos nativos. A categoria Other inclui nativos americanos, nativos do Alasca e pessoas que se identificam com múltiplas raças.
usa_ca = Table.read_table(path_data + 'usa_ca_2019.csv')
usa_ca| Ethnicity/Race | USA All | CA All | USA Children | CA Children |
|---|---|---|---|---|
| API | 5.8 | 15.1 | 4.9 | 11.5 |
| Black | 12.2 | 5.3 | 13.4 | 4.9 |
| Hispanic | 18.5 | 39.5 | 25.6 | 52.1 |
| White | 60.1 | 36.4 | 50.0 | 25.5 |
| Other | 3.4 | 3.7 | 6.1 | 6.0 |
É natural querer comparar essas distribuições. Faz sentido comparar as colunas diretamente, porque todas as entradas são porcentagens e, portanto, estão na mesma escala.
O método barh nos permite visualizar as comparações desenhando vários gráficos de barras nos mesmos eixos. A chamada é análoga àquelas para scatter e plot: temos que especificar o eixo comum das categorias.
usa_ca.barh('Ethnicity/Race')
Embora desenhar os gráficos de barras sobrepostos seja direto, há informações em excesso neste gráfico para conseguirmos separar semelhanças e diferenças entre as populações. É muito mais fácil comparar as populações um par de cada vez.
Vamos começar comparando as populações inteiras dos EUA e da Califórnia.
usa_ca.select('Ethnicity/Race', 'USA All', 'CA All').barh('Ethnicity/Race')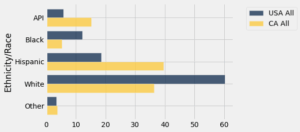
As duas distribuições são bastante diferentes. A Califórnia tem porcentagens mais altas nas categorias API e Hispanic, e correspondentes porcentagens mais baixas nas categorias Black e White. As porcentagens na categoria Other são bastante semelhantes nas duas populações. As diferenças se devem em grande parte à localização geográfica da Califórnia e aos padrões de imigração e migração, tanto historicamente quanto nas últimas décadas.
Como você pode ver no gráfico, quase 40% da população da Califórnia em 2019 era Hispanic. Uma comparação com a população de crianças do estado indica que a proporção Hispanic provavelmente será maior nos próximos anos. Entre as crianças californianas em 2019, mais de 50% estavam na categoria Hispanic.
usa_ca.select('Ethnicity/Race', 'CA All', 'CA Children').barh('Ethnicity/Race')
Conjuntos de dados mais complexos naturalmente dão origem a visualizações variadas e interessantes, incluindo gráficos sobrepostos de diferentes tipos. Para analisar esses dados, é útil ter mais habilidades em manipulação de dados, para que possamos colocar os dados em uma forma que nos permita usar métodos como os desta seção. No próximo capítulo, desenvolveremos algumas dessas habilidades.
| ← Capítulo 7.2 – Visualizando Distribuições Numéricas | Capítulo 8 – Funções e Tabelas → |