
Capítulo 14.1
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
%matplotlib inline
path_data = '../../../assets/data/'
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
import pylab as pl
import numpy as np
Propriedades da Média
Neste curso, temos usado as palavras “média” e “média aritmética” de forma intercambiável e continuaremos a fazê-lo. A definição de média será familiar para você desde os tempos de escola ou até antes.
Definição. A média ou média aritmética de uma coleção de números é a soma de todos os elementos da coleção, dividida pelo número de elementos na coleção.
Os métodos np.average e np.mean retornam a média de um array.
not_symmetric = make_array(2, 3, 3, 9)
np.average(not_symmetric)| Out[1]: | 4.25 |
np.mean(not_symmetric)| Out[2]: | 4.25 |
Propriedades Básicas
A definição e o exemplo acima apontam algumas propriedades da média.
- Ela não precisa ser um elemento da coleção.
- Ela não precisa ser um número inteiro, mesmo que todos os elementos da coleção sejam inteiros.
- Ela está entre os menores e maiores valores da coleção.
- Não precisa estar na metade entre os dois extremos; não é geralmente verdade que metade dos elementos de uma coleção estão acima da média.
- Se a coleção consiste em valores de uma variável medida em unidades especificadas, então a média tem as mesmas unidades também.
Agora estudaremos outras propriedades que são úteis para entender a média e sua relação com outras estatísticas.
A Média é um “Suavizador”
Você pode pensar em calcular a média como uma operação de “equalização” ou “suavização”. Por exemplo, imagine os valores em not_symmetric acima como dólares nos bolsos de quatro pessoas diferentes. Para obter a média, você primeiro coloca todo o dinheiro em um grande pote e depois divide igualmente entre as quatro pessoas. Elas começaram com diferentes quantias de dinheiro em seus bolsos ($2, $3, $3, e $9), mas agora cada pessoa tem $4,25, o valor médio.
Proporções são Médias
Se uma coleção consiste apenas em uns e zeros, então a soma da coleção é o número de uns nela, e a média da coleção é a proporção de uns.
zero_one = make_array(1, 1, 1, 0)
sum(zero_one)| Out[3]: | 3 |
np.mean(zero_one)| Out[4]: | 0.75 |
Você pode substituir 1 pelo booleano True e 0 por False:
np.mean(make_array(True, True, True, False))| Out[5]: | 0.75 |
Como as proporções são um caso especial de médias, os resultados sobre médias de amostras aleatórias também se aplicam a proporções de amostras aleatórias.
A Média e o Histograma
A média da coleção {2, 3, 3, 9} é 4.25, que não é o “ponto médio” dos dados. Então, o que a média mede?
Para ver isso, observe que a média pode ser calculada de diferentes maneiras.
média = 4.25
= (2 + 3 + 3 + 9)⁄4
= 2 ⋅ 1⁄4 + 3 ⋅ 1⁄4 + 3 ⋅ 1⁄4 + 9 ⋅ 1⁄4
= 2 ⋅ 1⁄4 + 3 ⋅ 2⁄4 + 9 ⋅ 1⁄4
= 2 ⋅ 0.25 + 3 ⋅ 0.5 + 9 ⋅ 0.25
A última expressão é um exemplo de um fato geral: quando calculamos a média, cada valor distinto na coleção é ponderado pela proporção de vezes que ele aparece na coleção.
Isso tem uma consequência importante. A média de uma coleção depende apenas dos valores distintos e suas proporções, não do número de elementos na coleção. Em outras palavras, a média de uma coleção depende apenas da distribuição dos valores na coleção.
Portanto, se duas coleções têm a mesma distribuição, então elas têm a mesma média.
Por exemplo, aqui está outra coleção que tem a mesma distribuição que not_symmetric e, portanto, a mesma média.
not_symmetric| Out[6]: | array([2, 3, 3, 9]) |
same_distribution = make_array(2, 2, 3, 3, 3, 3, 9, 9)
np.mean(same_distribution)| Out[7]: | 4.25 |
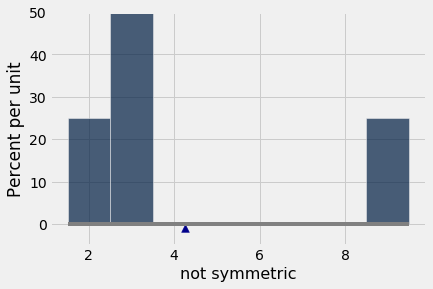
A média é um atributo físico do histograma da distribuição. Aqui está o histograma da distribuição de not_symmetricou equivalentemente a distribuição de same_distribution.
t1 = Table().with_columns('not symmetric', not_symmetric)
t1.hist(bins=np.arange(1.5, 9.6, 1))

Imagine o histograma como uma figura feita de papelão presa a um fio que corre ao longo do eixo horizontal, e imagine as barras como pesos presos nos valores 2, 3 e 9. Suponha que você tente equilibrar esta figura em um ponto no fio. Se o ponto estiver próximo de 2, a figura vai tombar para a direita. Se o ponto estiver próximo de 9, a figura vai tombar para a esquerda. Em algum lugar entre está o ponto onde a figura vai se equilibrar; esse ponto é o 4,25, a média.
A média é o centro de gravidade ou ponto de equilíbrio do histograma.
Para entender por que isso é verdade, é útil conhecer um pouco de física. O centro de gravidade é calculado exatamente como calculamos a média, usando os valores distintos ponderados por suas proporções.
Por ser um ponto de equilíbrio, a média às vezes é exibida como um fulcro ou triângulo na base do histograma.
mean_ns = np.mean(not_symmetric)
t1.hist(bins=np.arange(1.5, 9.6, 1))
plots.scatter(mean_ns, -0.009, marker='^', color='darkblue', s=60)
plots.plot([1.5, 9.5], [0, 0], color='grey')
plots.ylim(-0.05, 0.5);
A Média e a Mediana
Se a nota de um aluno em um teste está abaixo da média, isso implica que o aluno está na metade inferior da turma nesse teste?
Felizmente para o aluno, a resposta é: “Não necessariamente.” O motivo está relacionado à relação entre a média, que é o ponto de equilíbrio do histograma, e a mediana, que é o “ponto médio” dos dados.
A relação é fácil de ver em um exemplo simples. Aqui está o histograma da coleção {2, 3, 3, 4}, que está no array symmetric. A distribuição é simétrica em torno de 3. A média e a mediana são ambas iguais a 3.
symmetric = make_array(2, 3, 3, 4)
t2 = Table().with_columns('symmetric', symmetric)
mean_s = np.mean(symmetric)
t2.hist(bins=np.arange(1.5, 4.6, 1))
plots.scatter(mean_s, -0.009, marker='^', color='darkblue', s=60)
plots.xlim(1, 10)
plots.ylim(-0.05, 0.5);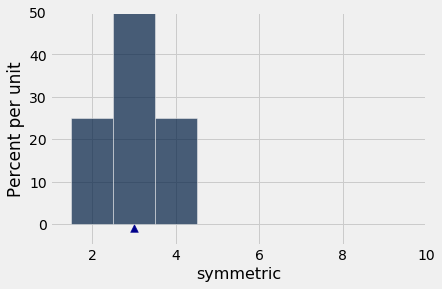
np.mean(symmetric)| Out[8]: | 3.0 |
percentile(50, symmetric)| Out[9]: | 3 |
Em geral, para distribuições simétricas, a média e a mediana são iguais.
E se a distribuição não for simétrica? Vamos comparar symmetric e not_symmetric.
t3 = t2.with_column(
'not_symmetric', not_symmetric
)
t3.hist(bins=np.arange(1.5, 9.6, 1))
plots.scatter(mean_s, -0.009, marker='^', color='darkblue', s=60)
plots.scatter(mean_ns, -0.009, marker='^', color='gold', s=60)
plots.ylim(-0.05, 0.5);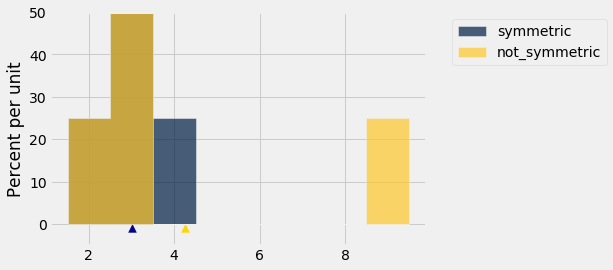
O histograma azul representa a distribuição original symmetric. O histograma dourado de not_symmetric começa da mesma forma que o azul na extremidade esquerda, mas sua barra mais à direita deslocou-se para o valor 9. A parte marrom é onde os dois histogramas se sobrepõem.
A mediana e a média da distribuição azul são ambas iguais a 3. A mediana da distribuição dourada também é igual a 3, embora a metade direita esteja distribuída de forma diferente da metade esquerda.
Mas a média da distribuição dourada não é 3: o histograma dourado não se equilibraria em 3. O ponto de equilíbrio deslocou-se para a direita, para 4,25.
Na distribuição dourada, 3 em cada 4 entradas (75%) estão abaixo da média. O estudante com uma nota abaixo da média pode, portanto, se alegrar. Ele ou ela pode estar na maioria da classe.
Em geral, se o histograma tem uma cauda em um lado (o termo formal é “skewed”), então a média é puxada para longe da mediana na direção da cauda.
Exemplo
A tabela sf2015 contém dados salariais e de benefícios dos funcionários da cidade de São Francisco em 2015. Como antes, restringiremos nossa análise aos que tiveram o equivalente a pelo menos meio período de trabalho durante o ano.
sf2015 = Table.read_table(path_data + 'san_francisco_2015.csv').where('Salaries', are.above(10000))| Out[10]: | Como vimos anteriormente, a remuneração mais alta estava acima de $600.000, mas a grande maioria dos funcionários tinha remunerações abaixo de $300.000. |
sf2015.select('Total Compensation').hist(bins = np.arange(10000, 700000, 25000))

Este histograma está inclinado para a direita; tem uma cauda para a direita.
A média é afastada da mediana em direção à cauda. Portanto, esperamos que a compensação média seja maior que a mediana, e esse é realmente o caso.
compensation = sf2015.column('Total Compensation')
percentile(50, compensation)| Out[11]: | 110305.79 |
np.mean(compensation)| Out[12]: | 114725.98411824222 |
As distribuições de rendimentos de grandes populações tendem a ser distorcidas para a direita. Quando a maior parte da população tem rendimentos médios a baixos, mas uma proporção muito pequena tem rendimentos muito elevados, o histograma tem uma cauda longa e fina para a direita.
A renda média é afetada por esta cauda: quanto mais a cauda se estende para a direita, maior se torna a média. Mas a mediana não é afetada pelos valores nos extremos da distribuição. É por isso que os economistas muitas vezes resumem as distribuições de renda pela mediana em vez da média.
| ← Capítulo 14 – Por que a Média Importa | Capítulo 14.2 – Variabilidade → |