
Capítulo 12.1
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
path_data = '../../../assets/data/'
import numpy as np
import matplotlib
matplotlib.use('Agg')
%matplotlib inline
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
Teste A/B
Na análise de dados moderna, decidir se duas amostras numéricas vêm da mesma distribuição subjacente é chamado de teste A/B. O nome refere-se aos rótulos das duas amostras, A e B.
Vamos desenvolver o método no contexto de um exemplo. Os dados são provenientes de uma amostra de recém-nascidos em um grande sistema hospitalar. Trataremos como se fosse uma amostra aleatória simples, embora a amostragem tenha sido feita em múltiplos estágios. Stat Labs por Deborah Nolan e Terry Speed contém detalhes sobre um conjunto de dados maior do qual este conjunto é extraído.
Fumantes e Não Fumantes
A tabela births contém as seguintes variáveis para 1.174 pares mãe-bebê: o peso ao nascer do bebê em onças, o número de dias gestacionais, a idade da mãe em anos completos, a altura da mãe em polegadas, o peso durante a gravidez em libras e se a mãe fumou ou não durante a gravidez.
births = Table.read_table(path_data + 'baby.csv')
births| Birth Weight | Gestational Days | Maternal Age | Maternal Height | Maternal Pregnancy Weight | Maternal Smoker |
|---|---|---|---|---|---|
| 120 | 284 | 27 | 62 | 100 | False |
| 113 | 282 | 33 | 64 | 135 | False |
| 128 | 279 | 28 | 64 | 115 | True |
| 108 | 282 | 23 | 67 | 125 | True |
| 136 | 286 | 25 | 62 | 93 | False |
| 138 | 244 | 33 | 62 | 178 | False |
| 132 | 245 | 23 | 65 | 140 | False |
| 120 | 289 | 25 | 62 | 125 | False |
| 143 | 299 | 30 | 66 | 136 | True |
| 140 | 351 | 27 | 68 | 120 | False |
Um dos objetivos do estudo era verificar se o tabagismo materno estava associado ao peso ao nascer. Vamos ver o que podemos dizer sobre as duas variáveis.
Começaremos selecionando apenas Birth Weight e Maternal Smoker. Há 715 não fumantes entre as mulheres da amostra e 459 fumantes.
smoking_and_birthweight = births.select('Maternal Smoker', 'Birth Weight')smoking_and_birthweight.group('Maternal Smoker')| Maternal Smoker | count |
|---|---|
| False | 715 |
| True | 459 |
Vejamos a distribuição dos pesos ao nascer dos bebês das mães não fumantes em comparação com os das mães fumantes. Para gerar dois histogramas sobrepostos, usaremos hist com o argumento opcional group que é uma coluna rótulo ou índice. As linhas da tabela são primeiro agrupadas por esta coluna e então um histograma é desenhado para cada uma.
smoking_and_birthweight.hist('Birth Weight', group = 'Maternal Smoker')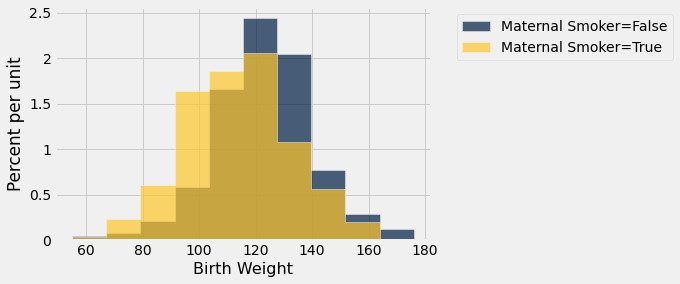
A distribuição dos pesos dos bebês nascidos de mães que fumaram parece estar ligeiramente deslocada para a esquerda da distribuição correspondente às mães não fumantes. Os pesos dos bebês das mães que fumaram parecem ser menores em média do que os pesos dos bebês das não fumantes.
Isso levanta a questão de saber se a diferença reflete apenas variação ao acaso ou uma diferença nas distribuições na população maior. Poderia ser que não houvesse diferença entre as duas distribuições na população, mas estaríamos vendo uma diferença nas amostras apenas por causa das mães que foram selecionadas?
As Hipóteses
Podemos tentar responder a essa pergunta por meio de um teste de hipóteses. O modelo de chance que testaremos diz que não há diferença subjacente nas populações; as distribuições nas amostras são diferentes apenas devido ao acaso.
Formalmente, esta é a hipótese nula. Precisaremos descobrir como simular uma estatística útil sob esta hipótese. Mas, para começar, vamos apenas declarar as duas hipóteses naturais.
Hipótese nula: Na população, a distribuição dos pesos ao nascer dos bebês é a mesma para mães que não fumam e para mães que fumam. A diferença na amostra é devida ao acaso.
Hipótese alternativa: Na população, os bebês das mães que fumam têm um peso ao nascer menor, em média, do que os bebês das não fumantes.
Estatística do Teste
A hipótese alternativa compara os pesos médios ao nascer dos dois grupos e diz que a média para as mães que fumam é menor. Portanto, é razoável usarmos a diferença entre as médias dos dois grupos como nossa estatística.
Faremos a subtração na ordem “peso médio do grupo que fuma – peso médio do grupo que não fuma”. Valores pequenos (ou seja, grandes valores negativos) dessa estatística favorecerão a hipótese alternativa.
O valor observado da estatística do teste é cerca de -9,27 onças.
means_table = smoking_and_birthweight.group('Maternal Smoker', np.average)
means_table| Maternal Smoker | Birth Weight average |
|---|---|
| False | 123.085 |
| True | 113.819 |
means = means_table.column(1)
observed_difference = means.item(1) - means.item(0)
observed_difference| Out[1]: | -9.266142572024918 |
Vamos calcular tais diferenças repetidamente em nossas simulações abaixo, então vamos definir uma função para fazer o trabalho. A função recebe dois argumentos:
- o nome da tabela de dados
- o rótulo da coluna que contém a variável booleana para agrupamento
Ela retorna a diferença entre as médias do grupo True e do grupo False.
Você logo verá por que estamos especificando os dois argumentos. Por enquanto, verifique se a função retorna o que deve.
def difference_of_means(table, group_label):
"""Leva: nome da tabela,
rótulo da coluna que indica o grupo ao qual a linha pertence
Retorna: Diferença dos pesos médios ao nascer dos dois grupos"""
reduced = table.select('Birth Weight', group_label)
means_table = reduced.group(group_label, np.average)
means = means_table.column(1)
return means.item(1) - means.item(0)Para verificar se a função está funcionando, vamos usá-la para calcular a diferença observada entre as médias dos pesos ao nascer dos dois grupos na amostra.
difference_of_means(births, 'Maternal Smoker')| Out[2]: | -9.266142572024918 |
É o mesmo que o valor de observed_difference calculado anteriormente.
Previsão da Estatística Sob a Hipótese Nula
Para ver como a estatística deve variar sob a hipótese nula, temos que descobrir como simular a estatística sob essa hipótese. Um método inteligente baseado em permutações aleatórias faz exatamente isso.
Se não houvesse diferença entre as duas distribuições na população subjacente, então o fato de um peso ao nascer ter o rótulo True ou False em relação ao tabagismo materno não deveria fazer diferença na média. A ideia, então, é embaralhar todos os rótulos aleatoriamente entre as mães. Isso é chamado de permutação aleatória.
O embaralhamento garante que a contagem dos rótulos True não mude, nem a contagem dos rótulos False. Isso é importante para a comparabilidade das diferenças simuladas de médias e a diferença original das médias. Veremos mais tarde no curso que o tamanho da amostra afeta a variabilidade de uma média amostral.
Calcule a diferença entre as duas novas médias de grupo: a média do peso dos bebês cujas mães foram rotuladas aleatoriamente como fumantes e a média do peso dos bebês das mães restantes que foram rotuladas aleatoriamente como não fumantes. Este é um valor simulado da estatística do teste sob a hipótese nula.
Vamos ver como fazer isso. É sempre uma boa ideia começar com os dados. Reduzimos a tabela para ter apenas as colunas que precisamos.
smoking_and_birthweight| Maternal Smoker | Birth Weight |
|---|---|
| False | 120 |
| False | 113 |
| True | 128 |
| True | 108 |
| False | 136 |
| False | 138 |
| False | 132 |
| False | 120 |
| True | 143 |
| False | 140 |
Existem 1.174 linhas na tabela. Para embaralhar todos os rótulos, sortearemos uma amostra aleatória de 1.174 linhas sem reposição. Em seguida, a amostra incluirá todas as linhas da tabela, em ordem aleatória.
Podemos usar o método de tabela sample com o argumento opcional with_replacement=False. Não precisamos especificar um tamanho de amostra, porque por padrão, sample desenha tantas vezes quantas linhas houver na tabela.
shuffled_labels = smoking_and_birthweight.sample(with_replacement = False).column(0)
original_and_shuffled = smoking_and_birthweight.with_column('Shuffled Label', shuffled_labels)original_and_shuffled| Maternal Smoker | Birth Weight | Shuffled Label |
|---|---|---|
| False | 120 | True |
| False | 113 | False |
| True | 128 | False |
| True | 108 | True |
| False | 136 | False |
| False | 138 | False |
| False | 132 | True |
| False | 120 | False |
| True | 143 | True |
| False | 140 | False |
A mãe de cada bebê agora tem um rótulo aleatório de fumante/não fumante na coluna Shuffled Label, enquanto seu rótulo original está em Maternal Smoker. Se a hipótese nula for verdadeira, todos os rearranjos aleatórios dos rótulos deverão ser igualmente prováveis.
Vamos ver quão diferentes são os pesos médios nos dois grupos rotulados aleatoriamente.
shuffled_only = original_and_shuffled.select('Birth Weight','Shuffled Label')
shuffled_group_means = shuffled_only.group('Shuffled Label', np.average)
shuffled_group_means| Shuffled Label | Birth Weight average |
|---|---|
| False | 119.277 |
| True | 119.752 |
As médias dos dois grupos selecionados aleatoriamente estão um pouco mais próximas do que as médias dos dois grupos originais. Podemos usar nossa função difference_of_means para encontrar as duas diferenças.
difference_of_means(original_and_shuffled, 'Shuffled Label')| Out[3]: | 0.4747109100050153 |
difference_of_means(original_and_shuffled, 'Maternal Smoker')| Out[4]: | -9.266142572024918 |
Mas será que uma mistura diferente poderia resultar em uma diferença maior entre as médias dos grupos? Para ter uma ideia da variabilidade, precisamos simular a diferença muitas vezes.
Como sempre, vamos começar definindo uma função que simula um valor da estatística de teste sob a hipótese nula. Isso se resume a coletar o código que escrevemos acima.
A função é chamada one_simulated_difference_of_means. Ela não recebe argumentos e retorna a diferença entre as médias dos pesos ao nascer de dois grupos formados pela mistura aleatória de todos os rótulos.
def one_simulated_difference_of_means():
"""Retorna: Diferença entre pesos médios ao nascer
de bebês de fumantes e não fumantes após embaralhar rótulos"""
# array de shuffed labels
shuffled_labels = births.sample(with_replacement=False).column('Maternal Smoker')
# tabela de birth weights e shuffled labels
shuffled_table = births.select('Birth Weight').with_column(
'Shuffled Label', shuffled_labels)
return difference_of_means(shuffled_table, 'Shuffled Label') Execute a célula abaixo algumas vezes para ver como a saída muda.
one_simulated_difference_of_means()| Out[5]: | -0.058299434770034964 |
Teste de Permutação
Os testes baseados em permutações aleatórias dos dados são chamados de testes de permutação. Estamos realizando um neste exemplo. Na célula abaixo, simularemos nossa estatística de teste – a diferença entre o peso médio ao nascer dos dois grupos formados aleatoriamente – muitas vezes e colete as diferenças em uma matriz.
differences = make_array()
repetitions = 5000
for i in np.arange(repetitions):
new_difference = one_simulated_difference_of_means()
differences = np.append(differences, new_difference)O array differences contém 5.000 valores simulados de nossa estatística de teste: a diferença entre o peso médio no grupo de fumantes e o peso médio no grupo de não fumantes, quando os rótulos são atribuídos aleatoriamente.
Conclusão do Teste
O histograma abaixo mostra a distribuição desses 5.000 valores. É a distribuição empírica da estatística de teste simulada sob a hipótese nula. Isso é uma previsão sobre a estatística de teste, baseada na hipótese nula.
Table().with_column('Difference Between Group Means', differences).hist()
print('Observed Difference:', observed_difference)
plots.title('Prediction Under the Null Hypothesis');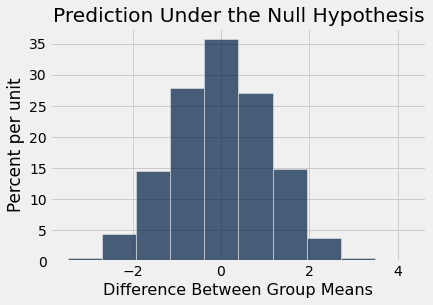
Observe como a distribuição está centrada aproximadamente em torno de 0. Isso faz sentido, porque sob a hipótese nula, os dois grupos devem ter médias aproximadamente iguais. Portanto, a diferença entre as médias dos grupos deve estar em torno de 0.
A diferença observada na amostra original é de cerca de -9,27 onças, o que nem mesmo aparece na escala horizontal do histograma. O valor observado da estatística e o comportamento previsto da estatística sob a hipótese nula são inconsistentes.
A conclusão do teste é que os dados favorecem a hipótese alternativa em relação à hipótese nula. Isso suporta a hipótese de que o peso médio ao nascer de bebês nascidos de mães que fumam é menor do que o peso médio ao nascer de bebês de mães não fumantes.
Se você deseja calcular um p-valor empírico, lembre-se de que valores baixos da estatística favorecem a hipótese alternativa.
empirical_p = np.count_nonzero(differences <= observed_difference) / repetitions
empirical_p| Out[6]: | 0.0 |
O p-valor empírico é 0, o que significa que nenhuma das 5.000 amostras permutadas resultou em uma diferença de -9,27 ou menos. Esta é apenas uma aproximação. A chance exata de obter uma diferença nesse intervalo não é 0. Mas é extremamente pequeno, de acordo com a nossa simulação, e portanto podemos rejeitar a hipótese nula.
Outro Teste de Permutação
Podemos usar o mesmo método para comparar outros atributos dos fumantes e dos não fumantes, como a idade. Os histogramas das idades dos dois grupos mostram que, na amostra, as mães que fumavam tendiam a ser mais jovens.
smoking_and_age = births.select('Maternal Smoker', 'Maternal Age')
smoking_and_age.hist('Maternal Age', group = 'Maternal Smoker')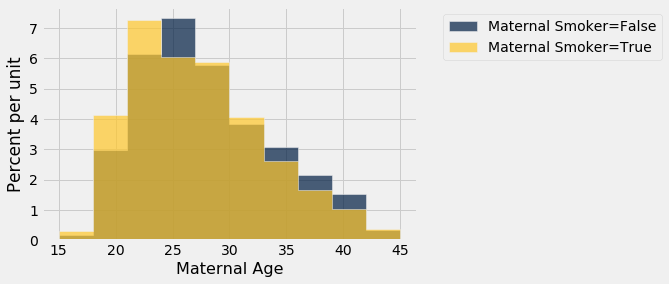
A diferença observada entre as idades médias é de cerca de -0.8 anos.
Vamos reescrever o código que comparou o peso ao nascer para que agora compare as idades dos fumantes e dos não fumantes.
def difference_of_means(table, group_label):
"""Leva: nome da tabela,
rótulo da coluna que indica o grupo ao qual a linha pertence
Retorna: Diferença das idades médias dos dois grupos"""
reduced = table.select('Maternal Age', group_label)
means_table = reduced.group(group_label, np.average)
means = means_table.column(1)
return means.item(1) - means.item(0)observed_age_difference = difference_of_means(births, 'Maternal Smoker')
observed_age_difference| Out[7]: | -0.8076725017901509 |
Lembre-se de que a diferença é calculada como a média da idade dos fumantes menos a média da idade dos não fumantes. O sinal negativo indica que os fumantes são mais jovens em média.
Essa diferença é devida ao acaso, ou reflete uma diferença subjacente na população?
Como antes, podemos usar um teste de permutação para responder a essa pergunta. Se as distribuições subjacentes das idades nos dois grupos forem iguais, então a distribuição empírica da diferença com base em amostras permutadas preverá como a estatística deve variar devido ao acaso.
Vamos seguir o mesmo processo que em qualquer simulação. Começaremos escrevendo uma função que retorna um valor simulado da diferença entre médias, e então escreveremos um for loop para simular numerosos valores assim e coletá-los em uma matriz.
def one_simulated_difference_of_means():
"""Retorna: Diferença entre idades médias
de fumantes e não fumantes após embaralhar os rótulos"""
# array de rótulos embaralhados
shuffled_labels = births.sample(with_replacement=False).column('Maternal Smoker')
# tabela de idades e rótulos embaralhados
shuffled_table = births.select('Maternal Age').with_column(
'Shuffled Label', shuffled_labels)
return difference_of_means(shuffled_table, 'Shuffled Label') age_differences = make_array()
repetitions = 5000
for i in np.arange(repetitions):
new_difference = one_simulated_difference_of_means()
age_differences = np.append(age_differences, new_difference)A diferença observada está na cauda da distribuição empírica das diferenças simuladas sob a hipótese nula.
Table().with_column(
'Difference Between Group Means', age_differences).hist(
right_end = observed_age_difference)
# Plotting parameters; you can ignore the code below
plots.ylim(-0.1, 1.2)
plots.scatter(observed_age_difference, 0, color='red', s=40, zorder=3)
plots.title('Prediction Under the Null Hypothesis')
print('Observed Difference:', observed_age_difference)| Out[8]: | Observed Difference: -0.8076725017901509 |

Mais uma vez, a distribuição empírica das diferenças simuladas está centrada aproximadamente em torno de 0, porque a simulação está sob a hipótese nula de que não há diferença entre as distribuições dos dois grupos.
O p-valor empírico do teste é a proporção de diferenças simuladas que foram iguais ou menores que a diferença observada. Isso ocorre porque valores baixos da diferença favorecem a hipótese alternativa de que os fumantes eram, em média, mais jovens.
empirical_p = np.count_nonzero(age_differences <= observed_age_difference) / 5000
empirical_p| Out[9]: | 0.0108 |
O p-valor empírico está em torno de 1% e, portanto, o resultado é estatisticamente significativo. O teste apoia a hipótese de que os fumantes eram, em média, mais jovens.
| ← Capítulo 12 – Comparando Duas Amostras | Capítulo 12.2 – Causalidade → |