
Capítulo 15.3
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
%matplotlib inline
path_data = '../../../assets/data/'
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
import numpy as np
O Método dos Mínimos Quadrados
Desenvolvemos a equação da linha de regressão que passa por um gráfico de dispersão em formato de bola de futebol. Mas nem todos os gráficos de dispersão têm esse formato, nem mesmo os lineares. Todo gráfico de dispersão possui uma linha “melhor” que o atravessa? Em caso afirmativo, podemos usar as fórmulas para a inclinação e interceptação desenvolvidas na seção anterior ou precisamos de novas?
Para abordar essas questões, precisamos de uma definição razoável de “melhor”. Lembre-se de que o propósito da linha é prever ou estimar valores de y, dados valores de x. As estimativas geralmente não são perfeitas. Cada uma está afastada do valor verdadeiro por um erro. Um critério razoável para uma linha ser a “melhor” é que ela tenha o menor erro geral possível entre todas as linhas retas.
Nesta seção, tornaremos esse critério preciso e veremos se podemos identificar a melhor linha reta segundo o critério.
def standard_units(any_numbers):
"Converta qualquer array de números em unidades padrão."
return (any_numbers - np.mean(any_numbers))/np.std(any_numbers)
def correlation(t, x, y):
return np.mean(standard_units(t.column(x))*standard_units(t.column(y)))
def slope(table, x, y):
r = correlation(table, x, y)
return r * np.std(table.column(y))/np.std(table.column(x))
def intercept(table, x, y):
a = slope(table, x, y)
return np.mean(table.column(y)) - a * np.mean(table.column(x))
def fit(table, x, y):
"""Retorne a altura da linha de regressão em cada valor de x."""
a = slope(table, x, y)
b = intercept(table, x, y)
return a * table.column(x) + bNosso primeiro exemplo é um conjunto de dados que tem uma linha para cada capítulo do romance “Little Women.” O objetivo é estimar o número de caracteres (isto é, letras, espaços, sinais de pontuação e assim por diante) com base no número de pontos finais. Lembre-se de que tentamos fazer isso na primeira aula deste curso.
little_women = Table.read_table(path_data + 'little_women.csv')
little_women = little_women.move_to_start('Periods')
little_women.show(3)| Periods | Characters |
|---|---|
| 189 | 21759 |
| 188 | 22148 |
| 231 | 20558 |
little_women.scatter('Periods', 'Characters')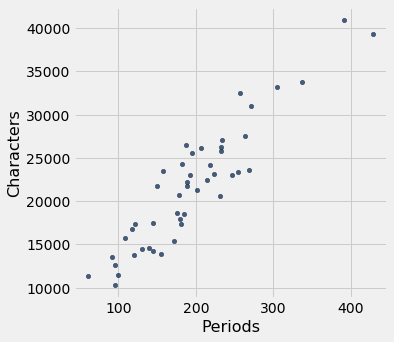
Para explorar os dados, precisaremos usar as funções correlation, slope, intercept, e fitdefinido na seção anterior.
correlation(little_women, 'Periods', 'Characters')| Out[1]: | 0.9229576895854816 |
O gráfico de dispersão é notavelmente próximo do linear e a correlação é superior a 0,92.
Erro na Estimativa
O gráfico abaixo mostra o gráfico de dispersão e a linha que desenvolvemos na seção anterior. Ainda não sabemos se essa é a melhor entre todas as linhas. Primeiro temos que dizer precisamente o que “melhor” significa.
lw_with_predictions = little_women.with_column('Linear Prediction', fit(little_women, 'Periods', 'Characters'))
lw_with_predictions.scatter('Periods')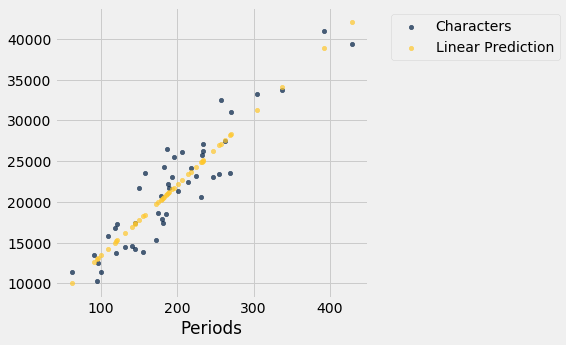
Correspondente a cada ponto do gráfico de dispersão, existe um erro de previsão calculado como o valor real menos o valor previsto. É a distância vertical entre o ponto e a linha, com sinal negativo se o ponto estiver abaixo da linha.
actual = lw_with_predictions.column('Characters')
predicted = lw_with_predictions.column('Linear Prediction')
errors = actual - predictedlw_with_predictions.with_column('Error', errors)| Periods | Characters | Linear Prediction | Error |
|---|---|---|---|
| 189 | 21759 | 21183.6 | 575.403 |
| 188 | 22148 | 21096.6 | 1051.38 |
| 231 | 20558 | 24836.7 | -4278.67 |
| 195 | 25526 | 21705.5 | 3820.54 |
| 255 | 23395 | 26924.1 | -3529.13 |
| 140 | 14622 | 16921.7 | -2299.68 |
| 131 | 14431 | 16138.9 | -1707.88 |
| 214 | 22476 | 23358 | -882.043 |
| 337 | 33767 | 34056.3 | -289.317 |
| 185 | 18508 | 20835.7 | -2327.69 |
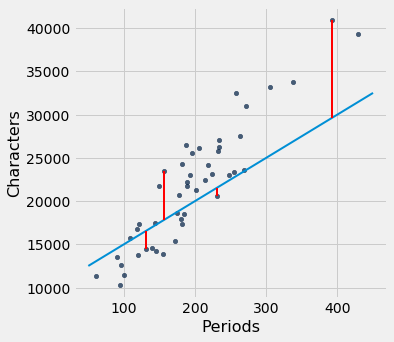
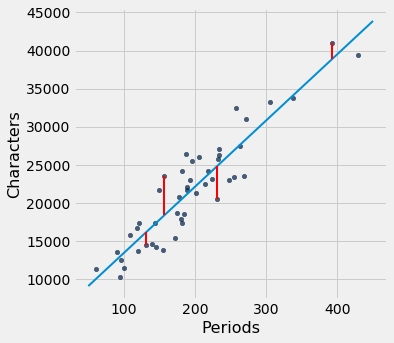
Podemos usar slope e intercept para calcular a inclinação e a interceptação da linha ajustada. O gráfico abaixo mostra a linha (em azul claro). Os erros correspondentes a quatro dos pontos são mostrados em vermelho. Não há nada de especial nesses quatro pontos. Eles foram escolhidos apenas pela clareza da exibição. A função lw_errors pega uma inclinação e uma interceptação (nessa ordem) como argumentos e desenha a figura.
lw_reg_slope = slope(little_women, 'Periods', 'Characters')
lw_reg_intercept = intercept(little_women, 'Periods', 'Characters')
sample = [[131, 14431], [231, 20558], [392, 40935], [157, 23524]]
def lw_errors(slope, intercept):
little_women.scatter('Periods', 'Characters')
xlims = np.array([50, 450])
plots.plot(xlims, slope * xlims + intercept, lw=2)
for x, y in sample:
plots.plot([x, x], [y, slope * x + intercept], color='r', lw=2)print('Slope of Regression Line: ', np.round(lw_reg_slope), 'characters per period')
print('Intercept of Regression Line:', np.round(lw_reg_intercept), 'characters')
lw_errors(lw_reg_slope, lw_reg_intercept)| Out[2]: | Slope of Regression Line: 87.0 characters per period Intercept of Regression Line: 4745.0 characters |

Se tivéssemos usado uma linha diferente para criar nossas estimativas, os erros teriam sido diferentes. O gráfico abaixo mostra quão grandes seriam os erros se usássemos outra linha para estimativa. O segundo gráfico mostra grandes erros obtidos usando uma linha, isso é totalmente bobo.
lw_errors(50, 10000)
lw_errors(-100, 50000)
Erro Quadrático Médio
O que precisamos agora é de uma medida geral do tamanho aproximado dos erros. Você reconhecerá a abordagem para criar isso – é exatamente a maneira como desenvolvemos o SD.
Se você usar qualquer linha arbitrária para calcular suas estimativas, então alguns de seus erros provavelmente serão positivos e outros negativos. Para evitar cancelamento ao medir o tamanho aproximado dos erros, tomaremos a média dos erros quadrados em vez da média dos próprios erros.
O erro quadrático médio de estimação é uma medida de quão grandes são os erros quadrados, mas, como observamos anteriormente, suas unidades são difíceis de interpretar. Tirar a raiz quadrada resulta no erro quadrático médio da raiz (rmse), que está nas mesmas unidades da variável sendo prevista e, portanto, muito mais fácil de entender.
Minimização do Erro Quadrático Médio
Nossas observações até agora podem ser resumidas da seguinte forma.
- Para obter estimativas de y com base em x, você pode usar qualquer linha que desejar.
- Toda linha tem um erro quadrático médio de estimação.
- Linhas “melhores” têm erros menores.
Existe uma linha “melhor”? Isto é, existe uma linha que minimiza o erro quadrático médio entre todas as linhas?
Para responder a essa pergunta, começaremos definindo uma função lw_rmse para calcular o erro quadrático médio de qualquer linha através do diagrama de dispersão de Little Women. A função recebe a inclinação e a interceptação (nessa ordem) como seus argumentos.
def lw_rmse(slope, intercept):
lw_errors(slope, intercept)
x = little_women.column('Periods')
y = little_women.column('Characters')
fitted = slope * x + intercept
mse = np.mean((y - fitted) ** 2)
print("Root mean squared error:", mse ** 0.5)lw_rmse(50, 10000)| Out[3]: | Root mean squared error: 4322.167831766537 |
lw_rmse(-100, 50000)| Out[4]: | Root mean squared error: 16710.11983735375 |

Linhas ruins têm valores grandes de rmse, como esperado. Mas o rmse é muito menor se escolhermos uma inclinação e interceptação próxima daquelas da linha de regressão.
lw_rmse(90, 4000)| Out[5]: | Root mean squared error: 2715.5391063834586 |
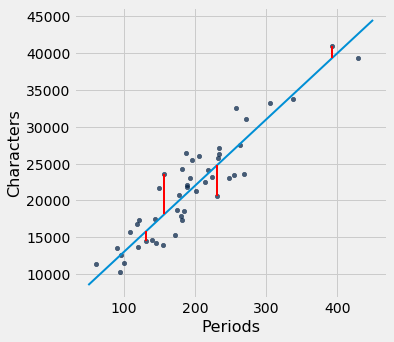
Aqui está a raiz do erro quadrático médio correspondente à linha de regressão. Por um fato notável da matemática, nenhuma outra linha pode superar esta.
- A linha de regressão é a única linha reta que minimiza o erro quadrático médio de estimativa entre todas as linhas retas.
lw_rmse(lw_reg_slope, lw_reg_intercept)| Out[6]: | Root mean squared error: 2701.690785311856 |
A prova desta afirmação requer matemática abstrata que está além do escopo deste curso. Por outro lado, temos uma ferramenta poderosa – Python – que realiza grandes cálculos numéricos com facilidade. Portanto, podemos usar Python para confirmar que a linha de regressão minimiza o erro quadrático médio.
Otimização Numérica
Primeiro, note que uma linha que minimiza o erro quadrático médio (rqm) também é uma linha que minimiza o erro quadrático. A raiz quadrada não faz diferença para a minimização. Portanto, vamos economizar um passo de cálculo e apenas minimizar o erro quadrático médio (eqm).
Estamos tentando prever o número de caracteres (y) com base no número de períodos (x) nos capítulos de ‘Little Women’. Se usarmos a linha
ela terá um eqm que depende da inclinação a e da interceptação b. A função lw_mse recebe a inclinação e a interceptação como argumentos e retorna o eqm correspondente.
def lw_mse(any_slope, any_intercept):
x = little_women.column('Periods')
y = little_women.column('Characters')
fitted = any_slope*x + any_intercept
return np.mean((y - fitted) ** 2)Vamos verificar se lw_mse obtém a resposta correta para o erro quadrático médio da linha de regressão. Lembre-se de que lw_mse retorna o erro quadrático médio, então temos que tirar a raiz quadrada para obter o rqm.
lw_mse(lw_reg_slope, lw_reg_intercept)**0.5| Out[7]: | 2701.690785311856 |
É o mesmo valor que obtivemos usando lw_rmse mais cedo:
lw_rmse(lw_reg_slope, lw_reg_intercept)| Out[8]: | Root mean squared error: 2701.690785311856 |

Você pode confirmar que lw_mse também retorna o valor correto para outras inclinações e interceptações. Por exemplo, aqui está o resultado da linha extremamente ruim que tentamos anteriormente.
lw_mse(-100, 50000)**0.5| Out[9]: | 16710.11983735375 |
E aqui está o resultado de uma linha que está próxima da linha de regressão.
lw_mse(90, 4000)**0.5| Out[10]: | 2715.5391063834586 |
Se experimentarmos diferentes valores, podemos encontrar uma inclinação e interceptação de baixo erro por tentativa e erro, mas isso levaria um tempo. Felizmente, existe uma função Python que faz todas as tentativas e erros para nós.
A função minimize pode ser usada para encontrar os argumentos de uma função para os quais a função retorna seu valor mínimo. O Python usa uma abordagem semelhante de tentativa e erro, seguindo as mudanças que levam a valores de saída incrementalmente menores.
O argumento de minimize é uma função que, por sua vez, aceita argumentos numéricos e retorna um valor numérico. Por exemplo, a função lw_mse aceita uma inclinação numérica e uma interceptação como seus argumentos e retorna o mse correspondente.
A chamada minimize(lw_mse) retorna um array que consiste na inclinação e na interceptação que minimizam o mse. Esses valores minimizantes são aproximações excelentes alcançadas por tentativa e erro inteligente, não valores exatos baseados em fórmulas.
best = minimize(lw_mse)
best| Out[11]: | array([ 86.97784117, 4744.78484535]) |
Esses valores são os mesmos que calculamos anteriormente usando as funções slope e intercept. Vemos pequenas variações devido à natureza inexata do minimize, mas os valores são essencialmente os mesmos.
print("slope from formula: ", lw_reg_slope)
print("slope from minimize: ", best.item(0))
print("intercept from formula: ", lw_reg_intercept)
print("intercept from minimize: ", best.item(1))| Out[12]: | slope from formula: 86.97784125829821 slope from minimize: 86.97784116615884 intercept from formula: 4744.784796574928 intercept from minimize: 4744.784845352655 |
A Linha dos Mínimos Quadrados
Portanto, descobrimos não apenas que a linha de regressão minimiza o erro quadrático médio, mas também que minimizar o erro quadrático médio nos dá a linha de regressão. A linha de regressão é a única linha que minimiza o erro quadrático médio.
É por isso que a linha de regressão às vezes é chamada de “linha dos mínimos quadrados.”
| ← Capítulo 15.2 – Linha de Regressão | Capítulo 15.4 – Regressão de Mínimos Quadrados → |