
Capítulo 8.3
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
path_data = '../../../assets/data/'
import numpy as np
import matplotlib
matplotlib.use('Agg')
%matplotlib inline
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')Classificação Cruzada por Mais de uma Variável
Quando os indivíduos têm múltiplas características, existem muitas maneiras diferentes de classificá-los. Por exemplo, se tivermos uma população de estudantes universitários para cada um dos quais registramos uma especialização e o número de anos na faculdade, então os estudantes podem ser classificados por especialização, ou por ano, ou por uma combinação de especialização e ano.
O método group também nos permite classificar os indivíduos de acordo com múltiplas variáveis. Isso é chamado de classificação cruzada.
Duas Variáveis: Contando o Número em Cada Categoria Pareada
A tabela more_cones registra o sabor, a cor e o preço de seis casquinhas de sorvete.
more_cones = Table().with_columns(
'Flavor', make_array('strawberry', 'chocolate', 'chocolate', 'strawberry', 'chocolate', 'bubblegum'),
'Color', make_array('pink', 'light brown', 'dark brown', 'pink', 'dark brown', 'pink'),
'Price', make_array(3.55, 4.75, 5.25, 5.25, 5.25, 4.75)
)
more_cones| Flavor | Color | Price |
|---|---|---|
| strawberry | pink | 3.55 |
| chocolate | light brown | 4.75 |
| chocolate | dark brown | 5.25 |
| strawberry | pink | 5.25 |
| chocolate | dark brown | 5.25 |
| bubblegum | pink | 4.75 |
Sabemos como usar group para contar a quantidade de casquinhas de cada sabor:
more_cones.group('Flavor')| Flavor | count |
|---|---|
| bubblegum | 1 |
| chocolate | 3 |
| strawberry | 2 |
Mas agora cada cone tem também uma cor. Para classificar os cones tanto por sabor quanto por cor, passaremos uma lista de rótulos como argumento para group. A tabela resultante tem uma linha para cada combinação única de valores que aparecem juntos nas colunas agrupadas. Como antes, um único argumento (uma lista, neste caso, mas uma array também funcionaria) fornece contagens de linhas.
Embora existam seis cones, há apenas quatro combinações únicas de sabor e cor. Dois dos cones eram de chocolate marrom escuro e dois de morango rosa.
more_cones.group(['Flavor', 'Color'])| Flavor | Color | count |
|---|---|---|
| bubblegum | pink | 1 |
| chocolate | dark brown | 2 |
| chocolate | light brown | 1 |
| strawberry | pink | 2 |
Duas variáveis: Encontrando uma característica de cada categoria emparelhada
Um segundo argumento agrega todas as outras colunas que não estão na lista de colunas agrupadas.
more_cones.group(['Flavor', 'Color'], sum)| Flavor | Color | Price sum |
|---|---|---|
| bubblegum | pink | 4.75 |
| chocolate | dark brown | 10.5 |
| chocolate | light brown | 4.75 |
| strawberry | pink | 8.8 |
Três ou Mais Variáveis. Você pode usar group para classificar linhas por três ou mais variáveis categóricas. Basta incluí-las em uma única lista que será passada como primeiro argumento. Mas a classificação cruzada por várias variáveis pode se tornar complexa, pois o número de combinações distintas de categorias pode ser bastante grande.
Tabelas Pivot: Rearranjando a Saída do group
Muitos usos de classificação cruzada envolvem apenas duas variáveis categóricas, como Flavor e Color no exemplo acima. Nesses casos, é possível exibir os resultados da classificação em um tipo diferente de tabela, chamada tabela Pivot. Tabelas Pivot, também conhecidas como tabelas de contingência, facilitam o trabalho com dados que foram classificados de acordo com duas variáveis.
Lembre-se do uso de group para contar o número de cones em cada categoria combinada de sabor e cor:
more_cones.group(['Flavor', 'Color'])| Flavor | Color | count |
|---|---|---|
| bubblegum | pink | 1 |
| chocolate | dark brown | 2 |
| chocolate | light brown | 1 |
| strawberry | pink | 2 |
Os mesmos dados podem ser exibidos de forma diferente usando o método de tabela pivot. Ignore o código por um momento e apenas examine a tabela de resultados.
more_cones.pivot('Flavor', 'Color')| Color | bubblegum | chocolate | strawberry |
|---|---|---|---|
| dark brown | 0 | 2 | 0 |
| light brown | 0 | 1 | 0 |
| pink | 1 | 0 | 2 |
Observe como esta tabela exibe todos os nove pares possíveis de sabor e cor, incluindo pares como “chiclete marrom escuro” que não existem em nossos dados. Observe também que a contagem em cada par aparece no corpo da tabela: para encontrar o número de cones de chocolate marrom claro, percorra com os olhos a linha marrom claro até encontrar a coluna chocolate.
O método group recebe uma lista de dois rótulos porque é flexível: poderia receber um, três ou mais. Por outro lado, pivot sempre recebe dois rótulos de coluna, um para determinar as colunas e outro para determinar as linhas.
pivot
O método pivot é intimamente relacionado ao método group: ele agrupa linhas que compartilham uma combinação de valores. Ele é diferente de group porque organiza os valores resultantes em uma grade. O primeiro argumento para pivot é o rótulo de uma coluna que contém os valores que serão usados para formar novas colunas no resultado. O segundo argumento é o rótulo de uma coluna usada para as linhas. O resultado fornece a contagem de todas as linhas da tabela original que compartilham a combinação de valores de coluna e linha.
Assim como group, pivot pode ser usado com argumentos adicionais para encontrar características de cada combinação de categorias. Um terceiro argumento opcional chamado values indica uma coluna de valores que substituirá as contagens em cada célula da grade. No entanto, todos esses valores não serão exibidos; o quarto argumento collect indica como coletá-los em um único valor agregado a ser exibido na célula.
Um exemplo ajudará a esclarecer isso. Aqui está pivot sendo usado para encontrar o preço total dos cones em cada célula.
more_cones.pivot('Flavor', 'Color', values='Price', collect=sum)| Color | bubblegum | chocolate | strawberry |
|---|---|---|---|
| dark brown | 0.0 | 10.5 | 0.0 |
| light brown | 0.0 | 4.75 | 0.0 |
| pink | 4.75 | 0.0 | 8.8 |
E aqui está o group fazendo a mesma coisa.
more_cones.group(['Flavor', 'Color'], sum)| Flavor | Color | Price sum |
|---|---|---|
| bubblegum | pink | 4.75 |
| chocolate | dark brown | 10.5 |
| chocolate | light brown | 4.75 |
| strawberry | pink | 8.8 |
Embora os números em ambas as tabelas sejam os mesmos, a tabela produzida pelo pivot é mais fácil de ler e se presta mais facilmente à análise. A vantagem do pivot é que ele coloca os valores agrupados em colunas adjacentes, para que possam ser combinados e comparados.
Exemplo: Educação e Renda dos Adultos Californianos
O Portal de Dados Abertos do Estado da Califórnia é uma fonte rica de informações sobre a vida dos californianos. É nossa fonte de um conjunto de dados sobre realização educacional e renda pessoal entre os californianos nos anos de 2008 a 2014. Os dados são derivados da Pesquisa da População Atual do Censo dos EUA.
Para cada ano, a tabela registra a Contagem da População de californianos em muitas combinações diferentes de idade, gênero, realização educacional e renda pessoal. Estudaremos apenas os dados para o ano de 2014.
full_table = Table.read_table(path_data + 'educ_inc.csv')
ca_2014 = full_table.where('Year', are.equal_to('1/1/14 0:00')).where('Age', are.not_equal_to('00 to 17'))
ca_2014| Year | Age | Gender | Educational Attainment | Personal Income | Population Count |
|---|---|---|---|---|---|
| 1/1/14 0:00 | 18 to 64 | Female | No high school diploma | H: 75,000 and over | 2058 |
| 1/1/14 0:00 | 65 to 80+ | Male | No high school diploma | H: 75,000 and over | 2153 |
| 1/1/14 0:00 | 65 to 80+ | Female | No high school diploma | G: 50,000 to 74,999 | 4666 |
| 1/1/14 0:00 | 65 to 80+ | Female | High school or equivalent | H: 75,000 and over | 7122 |
| 1/1/14 0:00 | 65 to 80+ | Female | No high school diploma | F: 35,000 to 49,999 | 7261 |
| 1/1/14 0:00 | 65 to 80+ | Male | No high school diploma | G: 50,000 to 74,999 | 8569 |
| 1/1/14 0:00 | 18 to 64 | Female | No high school diploma | G: 50,000 to 74,999 | 14635 |
| 1/1/14 0:00 | 65 to 80+ | Male | No high school diploma | F: 35,000 to 49,999 | 15212 |
| 1/1/14 0:00 | 65 to 80+ | Male | College, less than 4-yr degree | B: 5,000 to 9,999 | 15423 |
| 1/1/14 0:00 | 65 to 80+ | Female | Bachelor’s degree or higher | A: 0 to 4,999 | 15459 |
Cada linha da tabela corresponde a uma combinação de idade, gênero, nível educacional e renda. Existem 127 dessas combinações no total!
Como primeiro passo, é uma boa ideia começar com apenas uma ou duas variáveis. Vamos nos concentrar apenas em um par: realização educacional e renda pessoal.
educ_inc = ca_2014.select('Educational Attainment', 'Personal Income', 'Population Count')
educ_inc| Educational Attainment | Personal Income | Population Count |
|---|---|---|
| No high school diploma | H: 75,000 and over | 2058 |
| No high school diploma | H: 75,000 and over | 2153 |
| No high school diploma | G: 50,000 to 74,999 | 4666 |
| High school or equivalent | H: 75,000 and over | 7122 |
| No high school diploma | F: 35,000 to 49,999 | 7261 |
| No high school diploma | G: 50,000 to 74,999 | 8569 |
| No high school diploma | G: 50,000 to 74,999 | 14635 |
| No high school diploma | F: 35,000 to 49,999 | 15212 |
| College, less than 4-yr degree | B: 5,000 to 9,999 | 15423 |
| Bachelor’s degree or higher | A: 0 to 4,999 | 15459 |
Vamos começar olhando apenas para o nível educacional. As categorias dessa variável foram subdivididas pelos diferentes níveis de renda. Portanto, agruparemos a tabela por Educational Attainment e sum a Population Count em cada categoria.
education = educ_inc.select('Educational Attainment', 'Population Count')
educ_totals = education.group('Educational Attainment', sum)
educ_totals| Educational Attainment | Population Count sum |
|---|---|
| Bachelor’s degree or higher | 8525698 |
| College, less than 4-yr degree | 7775497 |
| High school or equivalent | 6294141 |
| No high school diploma | 4258277 |
Existem apenas quatro categorias de nível de escolaridade. As contagens são tão grandes que é mais útil observar as porcentagens. Para isso, usaremos a função ‘percents’ que definimos em uma seção anterior. Ela converte uma matriz de números para uma matriz de porcentagens do total na matriz de entrada.
def percents(array_x):
return np.round( (array_x/sum(array_x))*100, 2)
Agora temos a distribuição do nível de escolaridade entre os adultos californianos. Mais de 30% têm diploma de bacharel ou superior, enquanto quase 16% não possuem diploma de ensino médio.
educ_distribution = educ_totals.with_column(
'Population Percent', percents(educ_totals.column(1))
)
educ_distribution| Educational Attainment | Population Count sum | Population Percent |
|---|---|---|
| Bachelor’s degree or higher | 8525698 | 31.75 |
| College, less than 4-yr degree | 7775497 | 28.96 |
| High school or equivalent | 6294141 | 23.44 |
| No high school diploma | 4258277 | 15.86 |
Usando pivot, podemos obter uma tabela de contingência (uma tabela de contagens) de adultos californianos classificados cruzadamente por Educational Attainment e Personal Income.
totals = educ_inc.pivot('Educational Attainment', 'Personal Income', values='Population Count', collect=sum)
totals| Personal Income | Bachelor’s degree or higher | College, less than 4-yr degree | High school or equivalent | No high school diploma |
|---|---|---|---|---|
| A: 0 to 4,999 | 575491 | 985011 | 1161873 | 1204529 |
| B: 5,000 to 9,999 | 326020 | 810641 | 626499 | 597039 |
| C: 10,000 to 14,999 | 452449 | 798596 | 692661 | 664607 |
| D: 15,000 to 24,999 | 773684 | 1345257 | 1252377 | 875498 |
| E: 25,000 to 34,999 | 693884 | 1091642 | 929218 | 464564 |
| F: 35,000 to 49,999 | 1122791 | 1112421 | 782804 | 260579 |
| G: 50,000 to 74,999 | 1594681 | 883826 | 525517 | 132516 |
| H: 75,000 and over | 2986698 | 748103 | 323192 | 58945 |
Aqui você vê o poder do pivot sobre outros métodos de cruzamento de classificação. Cada coluna de contagens é uma distribuição de renda pessoal em um nível específico de realização educacional. Converter as contagens em porcentagens nos permite comparar as quatro distribuições.
distributions = totals.select(0).with_columns(
"Bachelor's degree or higher", percents(totals.column(1)),
'College, less than 4-yr degree', percents(totals.column(2)),
'High school or equivalent', percents(totals.column(3)),
'No high school diploma', percents(totals.column(4))
)
distributions| Personal Income | Bachelor’s degree or higher | College, less than 4-yr degree | High school or equivalent | No high school diploma |
|---|---|---|---|---|
| A: 0 to 4,999 | 6.75 | 12.67 | 18.46 | 28.29 |
| B: 5,000 to 9,999 | 3.82 | 10.43 | 9.95 | 14.02 |
| C: 10,000 to 14,999 | 5.31 | 10.27 | 11.0 | 15.61 |
| D: 15,000 to 24,999 | 9.07 | 17.3 | 19.9 | 20.56 |
| E: 25,000 to 34,999 | 8.14 | 14.04 | 14.76 | 10.91 |
| F: 35,000 to 49,999 | 13.17 | 14.31 | 12.44 | 6.12 |
| G: 50,000 to 74,999 | 18.7 | 11.37 | 8.35 | 3.11 |
| H: 75,000 and over | 35.03 | 9.62 | 5.13 | 1.38 |
À primeira vista, você pode ver que mais de 35% daqueles com diplomas de Bacharel ou superior tinham renda de $75,000 ou mais, enquanto menos de 10% das pessoas nas outras categorias de educação tinham esse nível de renda.
O gráfico de barras abaixo compara as distribuições de renda pessoal dos adultos californianos que não têm diploma do ensino médio com aqueles que completaram um diploma de Bacharel ou superior. A diferença nas distribuições é marcante. Há uma clara associação positiva entre a educação e a renda pessoal.
distributions.select(0, 1, 4).barh(0)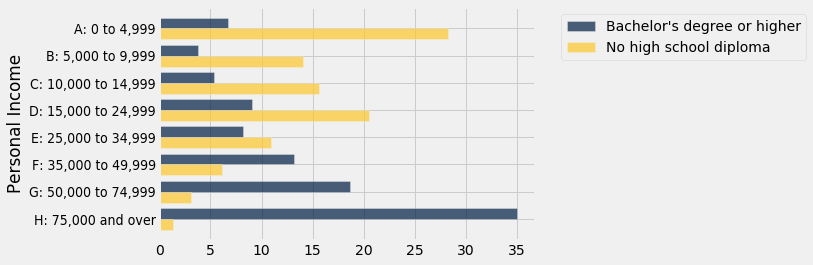
| ← Capítulo 8.2 – Classificando por uma Variável | Capítulo 8.4 – Unindo Tabelas por Colunas → |