
Capítulo 13.2
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
%matplotlib inline
path_data = '../../../assets/data/'
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
import numpy as np
O Bootstrap
Uma cientista de dados está usando os dados de uma amostra aleatória para estimar um parâmetro desconhecido. Ela utiliza a amostra para calcular o valor de uma estatística que será sua estimativa.
Uma vez que ela calculou o valor observado da sua estatística, ela poderia simplesmente apresentá-lo como sua estimativa e seguir em frente. Mas ela é uma cientista de dados. Ela sabe que sua amostra aleatória é apenas uma das muitas possíveis amostras aleatórias e, portanto, sua estimativa é apenas uma das várias estimativas plausíveis.
Em quanto essas estimativas podem variar? Para responder a isso, parece que ela precisa tirar outra amostra da população e calcular uma nova estimativa com base na nova amostra. Mas ela não tem os recursos para voltar à população e tirar outra amostra.
Parece que a cientista de dados está presa.
Felizmente, uma ideia brilhante chamada bootstrap pode ajudá-la. Como não é viável gerar novas amostras da população, o bootstrap gera novas amostras aleatórias por meio de um método chamado reamostragem: as novas amostras são sorteadas aleatoriamente da amostra original.
Nesta seção, veremos como e por que o bootstrap funciona. No restante do capítulo, usaremos o bootstrap para inferência.
Remuneração dos Funcionários na Cidade de São Francisco
O SF OpenData é um site onde a cidade e o condado de São Francisco disponibilizam alguns de seus dados publicamente. Um dos conjuntos de dados contém informações de remuneração dos funcionários da cidade. Isso inclui profissionais médicos em hospitais administrados pela cidade, policiais, bombeiros, trabalhadores de transporte, funcionários eleitos e todos os outros funcionários da cidade.
Os dados de remuneração para o ano calendário de 2019 estão na tabela sf2019.
sf2019 = Table.read_table(path_data + 'san_francisco_2019.csv')sf2019.show(3)| Organization Group | Department | Job Family | Job | Salary | Overtime | Benefits | Total Compensation |
|---|---|---|---|---|---|---|---|
| Public Protection | Adult Probation | Information Systems | IS Trainer-Journey | 91332 | 0 | 40059 | 131391 |
| Public Protection | Adult Probation | Information Systems | IS Engineer-Assistant | 123241 | 0 | 49279 | 172520 |
| Public Protection | Adult Probation | Information Systems | IS Business Analyst-Senior | 115715 | 0 | 46752 | 162468 |
Há uma linha para cada um dos mais de 44.500 funcionários. Existem inúmeras colunas contendo informações sobre a afiliação departamental da cidade e detalhes das diferentes partes do pacote de remuneração do funcionário. Aqui está a linha correspondente a London Breed, prefeito de São Francisco em 2019 .
sf2019.where('Job', 'Mayor')| Organization Group | Department | Job Family | Job | Salary | Overtime | Benefits | Total Compensation |
|---|---|---|---|---|---|---|---|
| General Administration & Finance | Mayor | Administrative & Mgmt (Unrep) | Mayor | 342974 | 0 | 98012 | 440987 |
Vamos estudar a coluna final, Total Compensation. Isso representa o salário do funcionário mais a contribuição da cidade para seus planos de aposentadoria e benefícios.
Os pacotes financeiros em um ano calendário às vezes podem ser difíceis de entender, pois dependem da data de contratação, se o funcionário está mudando de emprego dentro da cidade, e assim por diante. Por exemplo, os valores mais baixos na coluna Total Compensation parecem um pouco estranhos.
sf2019.sort('Total Compensation')| Organization Group | Department | Job Family | Job | Salary | Overtime | Benefits | Total Compensation |
|---|---|---|---|---|---|---|---|
| Public Protection | Adult Probation | Probation & Parole | Deputy Probation Officer | 0 | 0 | 0 | 0 |
| Public Protection | Fire Department | Clerical, Secretarial & Steno | Senior Clerk Typist | 0 | 0 | 0 | 0 |
| Public Protection | Juvenile Court | Correction & Detention | Counselor, Juvenile Hall PERS | 0 | 0 | 0 | 0 |
| Public Protection | Police | Clerical, Secretarial & Steno | Clerk Typist | 0 | 0 | 0 | 0 |
| Public Protection | Sheriff | Correction & Detention | Deputy Sheriff | 0 | 0 | 0 | 0 |
| Public Works, Transportation & Commerce | Airport Commission | Sub-Professional Engineering | StdntDsgn Train2/Arch/Eng/Plng | 0 | 0 | 0 | 0 |
| Public Works, Transportation & Commerce | Airport Commission | Clerical, Secretarial & Steno | Executive Secretary 1 | 0 | 0 | 0 | 0 |
| Public Works, Transportation & Commerce | Airport Commission | Payroll, Billing & Accounting | Senior Account Clerk | 0 | 0 | 0 | 0 |
| Public Works, Transportation & Commerce | Airport Commission | Housekeeping & Laundry | Custodian | 0 | 0 | 0 | 0 |
| Public Works, Transportation & Commerce | Airport Commission | Housekeeping & Laundry | Custodian | 0 | 0 | 0 | 0 |
Para maior clareza de interpretação, focaremos nossa atenção naqueles que tiveram aproximadamente o equivalente a um emprego de meio período ou mais durante todo o ano. Com um salário mínimo de cerca de 15 dólares por hora e 20 horas por semana durante 52 semanas , isso é um salário de mais de 15.000 dólares.
sf2019 = sf2019.where('Salary', are.above(15000))sf2019.num_rows| Out[1]: | 37103 |
População e Parâmetro
Deixe esta tabela de pouco mais de 37.000 linhas ser a nossa população. Aqui está um histograma das remunerações totais dos funcionários nesta tabela.
sf_bins = np.arange(0, 726000, 25000)
sf2019.select('Total Compensation').hist(bins=sf_bins)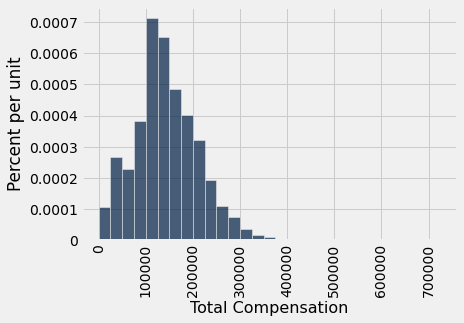
Embora a maioria dos valores esteja abaixo de 300.000 dólares, alguns são um pouco mais altos. Por exemplo, a remuneração total do Diretor de Investimentos foi superior a 700.000 dólares. É por isso que o eixo horizontal se estende bastante à direita das barra visíveis.
sf2019.sort('Total Compensation', descending=True).show(2)| Organization Group | Department | Job Family | Job | Salary | Overtime | Benefits | Total Compensation |
|---|---|---|---|---|---|---|---|
| General Administration & Finance | Retirement Services | Administrative & Mgmt (Unrep) | Chief Investment Officer | 577633 | 0 | 146398 | 724031 |
| General Administration & Finance | Retirement Services | Unassigned | Managing Director | 483072 | 0 | 134879 | 617951 |
Suponha que o parâmetro que nos interessa seja a mediana das remunerações totais.
Como podemos nos dar ao luxo de ter todos os dados da população, podemos simplesmente calcular o parâmetro:
pop_median = percentile(50, sf2019.column('Total Compensation'))
pop_median| Out[2]: | 135747.0 |
A mediana da compensação total de todos os funcionários foi de 135.747 dólares.
Do ponto de vista prático, não há motivo para tirarmos uma amostra para estimar esse parâmetro, pois simplesmente conhecemos o seu valor. Mas nesta seção, vamos fingir que não sabemos o valor e ver quão bem podemos estimá-lo com base em uma amostra aleatória.
Nas seções seguintes, voltaremos à realidade e trabalharemos em situações onde o parâmetro é desconhecido. Por enquanto, somos oniscientes.
Uma Amostra Aleatória e uma Estimativa
Vamos sortear uma amostra de 500 funcionários aleatoriamente, sem reposição, e a mediana da compensação total dos funcionários amostrados servirá como nossa estimativa do parâmetro.
our_sample = sf2019.sample(500, with_replacement=False)
our_sample.select('Total Compensation').hist(bins=sf_bins)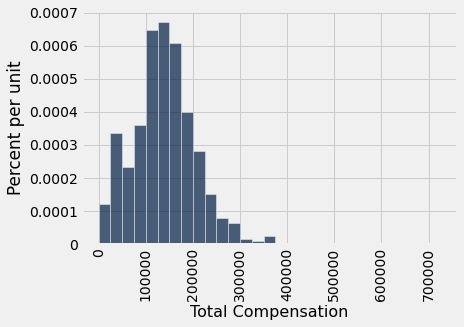
est_median = percentile(50, our_sample.column('Total Compensation'))
est_median| Out[3]: | 136835.0 |
O tamanho da amostra é grande. Pela lei das médias, a distribuição da amostra se assemelha à da população. Consequentemente, a mediana da amostra é bastante comparável à mediana da população, embora, claro, não seja exatamente a mesma.
Então agora temos uma estimativa do parâmetro. Mas se a amostra tivesse sido diferente, a estimativa teria um valor diferente. Gostaríamos de poder quantificar o quanto a estimativa poderia variar entre as amostras. Essa medida de variabilidade nos ajudará a medir quão precisamente podemos estimar o parâmetro.
Para ver quão diferente a estimativa seria se a amostra tivesse sido diferente, poderíamos simplesmente tirar outra amostra da população. Mas isso seria trapaça. Estamos tentando imitar a vida real, em que não teremos todos os dados da população à mão.
De alguma forma, temos que obter outra amostra aleatória sem amostrar novamente da população.
O Bootstrap: Reamostragem a Partir da Amostra
O que temos é uma grande amostra aleatória da população. Como sabemos, uma grande amostra aleatória provavelmente se assemelha à população da qual foi retirada. Esta observação permite que cientistas de dados se levantem pelos próprios cadarços: o procedimento de amostragem pode ser replicado amostrando a partir da amostra.
Aqui estão os passos do método bootstrap para gerar outra amostra aleatória que se assemelha à população:
- Trate a amostra original como se fosse a população.
- Tire da amostra, aleatoriamente com reposição, o mesmo número de vezes que o tamanho da amostra original.
É importante reamostrar o mesmo número de vezes que o tamanho da amostra original. A razão é que a variabilidade de uma estimativa depende do tamanho da amostra. Como nossa amostra original consistia de 500 funcionários, nossa mediana da amostra foi baseada em 500 valores. Para ver quão diferente a amostra poderia ter sido, temos que compará-la à mediana de outras amostras de tamanho 500.
Se tirássemos 500 vezes aleatoriamente sem reposição de nossa amostra de 500, simplesmente teríamos a mesma amostra de volta. Ao tirar com reposição, criamos a possibilidade de que as novas amostras sejam diferentes da original, porque alguns funcionários podem ser escolhidos mais de uma vez e outros não.
Por que o Bootstrap Funciona
Por que isso é uma boa ideia? Pela lei das médias, a distribuição da amostra original provavelmente se assemelha à população, e as distribuições de todas as “reamostras” provavelmente se assemelham à amostra original. Portanto, as distribuições de todas as reamostras provavelmente se assemelham à população também.
from IPython.display import Image
Image("../../../images/bootstrap_pic.png")
Uma Mediana Reamostrada
Lembre-se de que o método sample extrai linhas de uma tabela com substituição por padrão, e quando é usado sem especificar um tamanho de amostra, por padrão o tamanho da amostra é igual ao número de linhas da tabela. Isso é perfeito para o bootstrap! Aqui é uma nova amostra extraída da amostra original e a mediana da amostra correspondente.
resample_1 = our_sample.sample()resample_1.select('Total Compensation').hist(bins=sf_bins)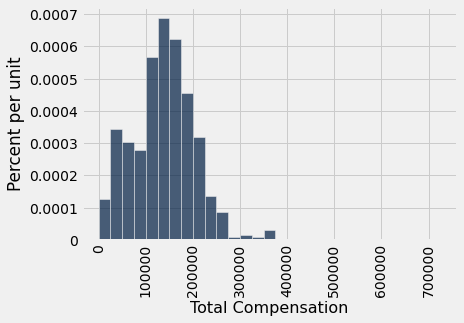
resampled_median_1 = percentile(50, resample_1.column('Total Compensation'))
resampled_median_1| Out[4]: | 141793.0 |
Este valor é uma estimativa da mediana da população.
Ao reamostrar repetidas vezes, podemos obter muitas dessas estimativas e, portanto, uma distribuição empírica das estimativas.
resample_2 = our_sample.sample()
resampled_median_2 = percentile(50, resample_2.column('Total Compensation'))
resampled_median_2| Out[4]: | 135880.0 |
Vamos coletar esse código e definir uma função one_bootstrap_median que retorna uma mediana inicializada da compensação total, com base na inicialização da amostra aleatória original que chamamos de our_sample.
def one_bootstrap_median():
resampled_table = our_sample.sample()
bootstrapped_median = percentile(50, resampled_table.column('Total Compensation'))
return bootstrapped_medianExecute a célula abaixo algumas vezes para ver como as medianas inicializadas variam. Lembre-se de que cada uma delas é uma estimativa da mediana da população.
one_bootstrap_median()| Out[5]: | 132175.0 |
Distribuição Empírica de Bootstrap da Mediana da Amostra
Agora podemos repetir o processo de bootstrap várias vezes executando um loop for como de costume. Em cada iteração, chamaremos a função one_bootstrap_median para gerar um valor da mediana bootstrapped com base em nossa amostra original our_sample. Então anexaremos a mediana inicializada ao array de coleção bstrap_medians.
Como estamos solicitando 5.000 repetições, o código pode demorar um pouco para ser executado. Há muita reamostragem a ser feita!
num_repetitions = 5000
bstrap_medians = make_array()
for i in np.arange(num_repetitions):
bstrap_medians = np.append (bstrap_medians, one_bootstrap_median())Aqui está um histograma empírico das 5.000 medianas bootstrap. O ponto verde é o parâmetro da população: é a mediana de toda a população, que é o que estamos tentando estimar. Neste exemplo, sabemos seu valor, mas nós não o usei no processo de inicialização.
resampled_medians = Table().with_column('Bootstrap Sample Median', bstrap_medians)
median_bins=np.arange(120000, 160000, 2000)
resampled_medians.hist(bins = median_bins)
# Plotting parameters; you can ignore this code
parameter_green = '#32CD32'
plots.ylim(-0.000005, 0.00014)
plots.scatter(pop_median, 0, color=parameter_green, s=40, zorder=2);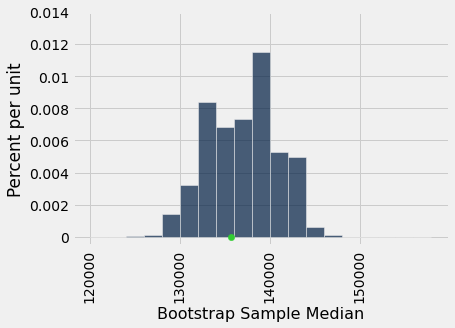
É importante lembrar que o ponto verde é fixo: são 135.747 dólares, a mediana da população. O histograma empírico é o resultado de sorteios aleatórios e estará situado aleatoriamente em relação ao ponto verde.
Lembre-se também de que o objetivo de todos esses cálculos é estimar a mediana da população, que é o ponto verde. Nossas estimativas são todas as medianas amostrais geradas aleatoriamente, cujo histograma você vê acima. Queremos que o conjunto dessas estimativas contenha o parâmetro. Se não contiver, então as estimativas estão erradas.
As Estimativas Capturam o Parâmetro?
Com que frequência o histograma empírico das medianas reamostradas fica firmemente sobre o ponto verde, e não apenas o toca com suas caudas ou não o cobre de todo? Para responder a isso, devemos definir “ficar firmemente”. Vamos tomar isso como “os 95% centrais das medianas reamostradas contêm o ponto verde”.
Aqui estão os dois extremos do intervalo dos “95% centrais” das medianas reamostradas:
left = percentile(2.5, bstrap_medians)
left| Out[6]: | 129524.0 |
right = percentile(97.5, bstrap_medians)
right| Out[7]: | 143446.0 |
A mediana populacional de 135.747 dólares está entre esses dois números. O intervalo e a mediana populacional são mostrados no histograma abaixo.
resampled_medians.hist(bins = median_bins)
# Plotting parameters; you can ignore this code
plots.ylim(-0.000005, 0.00014)
plots.plot([left, right], [0, 0], color='yellow', lw=3, zorder=1)
plots.scatter(pop_median, 0, color=parameter_green, s=40, zorder=2);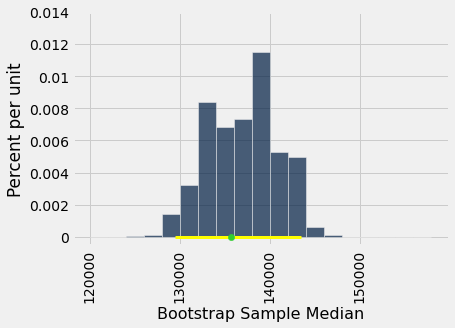
O intervalo dos “95% do meio” das estimativas capturou o parâmetro em nosso exemplo. Mas foi um acaso?
Para ver com que frequência o intervalo contém o parâmetro, temos que executar todo o processo repetidamente. Especificamente, replicaremos o seguinte processo 100 vezes:
- Tirar uma amostra aleatória original de tamanho 500 da população.
- Realizar 5000 replicações do processo bootstrap e gerar o intervalo dos “95% do meio” das medianas reamostradas.
Terminaremos com 100 intervalos e contaremos quantos deles contêm a mediana da população.
Spoiler: A teoria estatística do bootstrap diz que o número deve ser em torno de 95. Pode estar no início dos 90 ou final dos 90, mas não esperamos que se desvie muito de 95.
Começaremos escrevendo uma função bootstrap_median que leva dois argumentos: o nome da tabela contendo a amostra aleatória original e o número de amostras bootstrap a serem retiradas. Ela retorna uma matriz de medianas bootstrap, uma de cada amostra bootstrap.
def bootstrap_median(original_sample, num_repetitions):
medians = make_array()
for i in np.arange(num_repetitions):
new_bstrap_sample = original_sample.sample()
new_bstrap_median = percentile(50, new_bstrap_sample.column('Total Compensation'))
medians = np.append(medians, new_bstrap_median)
return mediansAgora vamos escrever um loop for que chama essa função 100 vezes e coleta os “95% intermediários” das medianas inicializadas a cada vez.
A célula abaixo levará vários minutos para ser executada, pois precisa realizar 100 replicações de amostragem 500 vezes aleatoriamente na tabela e gerar 5.000 amostras inicializadas.
# A GRANDE SIMULAÇÃO: Esta leva vários minutos.
# Gere 100 intervalos e coloque os pontos finais nos intervalos da tabela
left_ends = make_array()
right_ends = make_array()
for i in np.arange(100):
original_sample = sf2019.sample(500, with_replacement=False)
medians = bootstrap_median(original_sample, 5000)
left_ends = np.append(left_ends, percentile(2.5, medians))
right_ends = np.append(right_ends, percentile(97.5, medians))
intervals = Table().with_columns(
'Left', left_ends,
'Right', right_ends
) Para cada uma das 100 replicações de todo o processo, obtemos um intervalo de estimativas da mediana.
intervals| Left | Right |
|---|---|
| 125093 | 139379 |
| 129925 | 140757 |
| 133955 | 146369 |
| 129335 | 140847 |
| 132756 | 145429 |
| 130167 | 143200 |
| 125935 | 138491 |
| 131092 | 142472 |
| 128509 | 140462 |
| 131270 | 145998 |
Os bons intervalos são aqueles que contêm o parâmetro que estamos tentando estimar. Normalmente o parâmetro é desconhecido, mas nesta seção sabemos qual é o parâmetro.
pop_median| Out[8]: | 135747.0 |
Quantos dos 100 intervalos contêm a mediana da população? Esse é o número de intervalos em que a extremidade esquerda está abaixo da mediana da população e a extremidade direita está acima.
intervals.where(
'Left', are.below(pop_median)).where(
'Right', are.above(pop_median)).num_rows| Out[9]: | 93 |
Leva muitos minutos para construir todos os intervalos, mas tente novamente se tiver paciência. Muito provavelmente, cerca de 95 dos 100 intervalos serão bons: eles conterão o parâmetro.
É difícil mostrar todos os intervalos no eixo horizontal, pois eles têm grandes sobreposições – afinal, todos estão tentando estimar o mesmo parâmetro. O gráfico abaixo mostra cada intervalo nos mesmos eixos, empilhando-os verticalmente. O eixo vertical é simplesmente o número da replicação da qual o intervalo foi gerado.
A linha verde é onde o parâmetro está. Ela tem uma posição fixa, pois o parâmetro é fixo.
Bons intervalos cobrem o parâmetro. Tipicamente, há aproximadamente 95 deles.
Se um intervalo não cobre o parâmetro, ele é um fracasso. Os fracassos são aqueles onde você pode ver “claridade” ao redor da linha verde. Normalmente, há muito poucos – cerca de 5 em 100 – mas eles acontecem.
Qualquer método baseado em amostragem tem a possibilidade de estar errado. A beleza dos métodos baseados em amostragem aleatória é que podemos quantificar com que frequência eles provavelmente estarão errados.
replication_number = np.ndarray.astype(np.arange(1, 101), str)
intervals2 = Table(replication_number).with_rows(make_array(left_ends, right_ends))
plots.figure(figsize=(8,8))
for i in np.arange(100):
ends = intervals2.column(i)
plots.plot(ends, make_array(i+1, i+1), color='gold')
plots.scatter(pop_median, 0, color=parameter_green, s=40, zorder=2)
plots.plot(make_array(pop_median, pop_median), make_array(0, 100), color=parameter_green, lw=2)
plots.xlabel('Median (dollars)')
plots.ylabel('Replication')
plots.title('Population Median and Intervals of Estimates');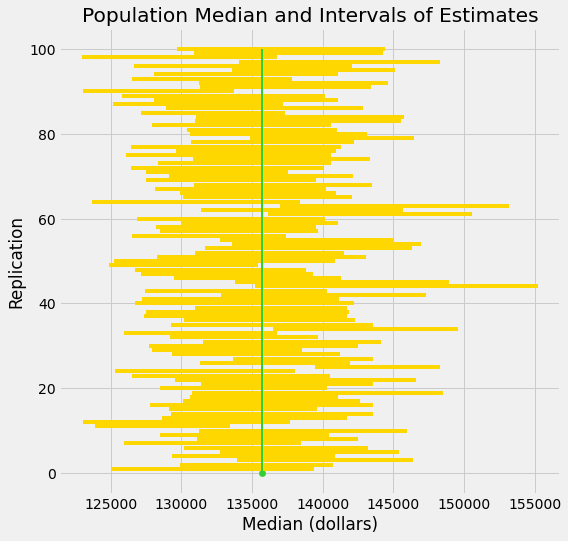
Para resumir o que a simulação mostra, suponha que você esteja estimando a mediana da população pelo seguinte processo:
- Tire uma grande amostra aleatória da população.
- Faça o bootstrap de sua amostra aleatória e obtenha uma estimativa da nova amostra aleatória.
- Repita a etapa de bootstrap acima milhares de vezes e obtenha milhares de estimativas.
- Selecione o intervalo dos “95% do meio” de todas as estimativas.
Isso lhe dá um intervalo de estimativas. Se 99 outras pessoas repetirem todo o processo, começando com uma nova amostra aleatória a cada vez, então você terminará com 100 desses intervalos. Cerca de 95 desses 100 intervalos conterão o parâmetro da população.
Em outras palavras, esse processo de estimativa captura o parâmetro em cerca de 95% das vezes.
Você pode substituir 95% por um valor diferente, desde que não seja 100. Suponha que você substitua 95% por 80% e mantenha o tamanho da amostra fixo em 500. Então seus intervalos de estimativas serão mais curtos do que os simulados aqui, porque os “80% do meio” é um intervalo menor do que os “95% do meio”. Se você continuar repetindo esse processo, apenas cerca de 80% dos seus intervalos conterão o parâmetro.
| ← Capítulo 13.1 – Percentis | Capítulo 13.3 – Intervalos de Confiança → |