
Capítulo 14.5
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
import numpy as np
path_data = '../../../assets/data/'
%matplotlib inline
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
A Variabilidade da Média da Amostra
Pelo Teorema Central do Limite, a distribuição de probabilidade da média de uma grande amostra aleatória é aproximadamente normal. A curva em forma de sino é centrada na média da população. Algumas das médias da amostra são maiores e outras menores, mas os desvios da média da população são aproximadamente simétricos de ambos os lados, como vimos repetidamente. Formalmente, a teoria da probabilidade mostra que a média da amostra é uma estimativa imparcial da média da
população.
Em nossas simulações, também observamos que as médias de amostras maiores tendem a se agrupar mais firmemente em torno da média da população do que as médias de amostras menores. Nesta seção, quantificaremos a variabilidade da média da amostra e desenvolveremos uma relação entre a variabilidade e o tamanho da amostra.
Vamos começar com nossa tabela de atrasos de voo. O atraso médio é de aproximadamente 16,7 minutos, e a distribuição dos atrasos é assimétrica para a direita.
united = Table.read_table(path_data + 'united_summer2015.csv')
delay = united.select('Delay')pop_mean = np.mean(delay.column('Delay'))
pop_mean| Out[1]: | 16.658155515370705 |
delay.hist(bins=np.arange(-20, 300, 10))
plots.scatter(pop_mean, -0.0008, marker='^', color='darkblue', s=60)
plots.ylim(-0.004, 0.04);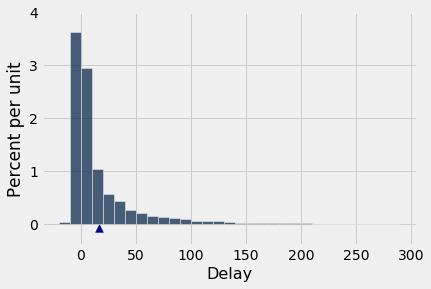
Agora vamos pegar amostras aleatórias e observar a distribuição de probabilidade da média amostral. Como de costume, usaremos simulação para obter uma aproximação empírica dessa distribuição.
Definiremos uma função simulate_sample_mean para fazer isso, pois iremos variar o tamanho da amostra posteriormente. Os argumentos são o nome da tabela, o rótulo da coluna que contém a variável, o tamanho da amostra e o número de simulações.
"""Distribuição empírica de amostra aleatória significa"""
def simulate_sample_mean(table, label, sample_size, repetitions):
means = make_array()
for i in range(repetitions):
new_sample = table.sample(sample_size)
new_sample_mean = np.mean(new_sample.column(label))
means = np.append(means, new_sample_mean)
sample_means = Table().with_column('Sample Means', means)
# Exibir histograma empírico e imprimir todas as quantidades relevantes
sample_means.hist(bins=20)
plots.xlabel('Sample Means')
plots.title('Sample Size ' + str(sample_size))
print("Sample size: ", sample_size)
print("Population mean:", np.mean(table.column(label)))
print("Average of sample means: ", np.mean(means))
print("Population SD:", np.std(table.column(label)))
print("SD of sample means:", np.std(means))Vamos simular a média de uma amostra aleatória de 100 atrasos, depois de 400 atrasos e finalmente de 625 atrasos. Realizaremos 10.000 repetições de cada um desses processos. As linhas xlim e ylim definem os eixos consistentemente em todos os gráficos para facilitar a comparação. Você pode simplesmente ignorar essas duas linhas de código em cada célula.
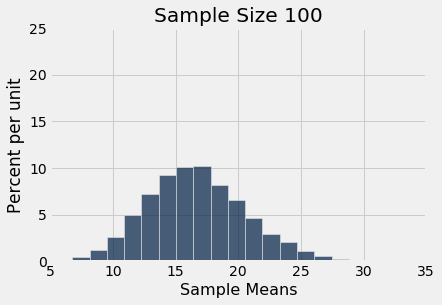
simulate_sample_mean(delay, 'Delay', 100, 10000)
plots.xlim(5, 35)
plots.ylim(0, 0.25);| Out[2]: | Sample size: 100 Population mean: 16.658155515370705 Average of sample means: 16.672836 Population SD: 39.480199851609314 SD of sample means: 3.92467202924066 |
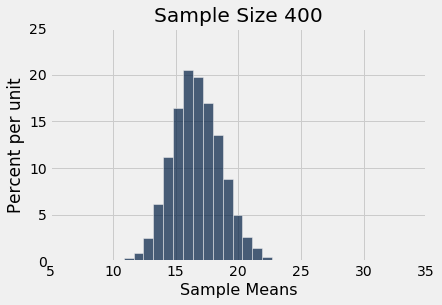
simulate_sample_mean(delay, 'Delay', 400, 10000)
plots.xlim(5, 35)
plots.ylim(0, 0.25);| Out[3]: | Sample size: 400 Population mean: 16.658155515370705 Average of sample means: 16.678091499999997 Population SD: 39.480199851609314 SD of sample means: 1.9474592014668113 |
simulate_sample_mean(delay, 'Delay', 625, 10000)
plots.xlim(5, 35)
plots.ylim(0, 0.25);| Out[4]: | Sample size: 625 Population mean: 16.658155515370705 Average of sample means: 16.649224 Population SD: 39.480199851609314 SD of sample means: 1.5883338034053167 |
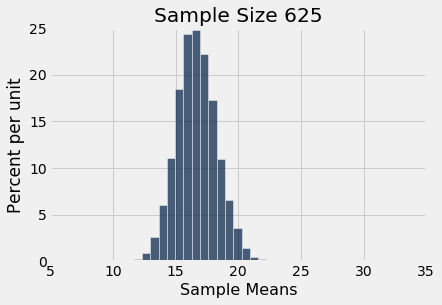
Você pode ver o Teorema Central do Limite em ação – os histogramas das médias das amostras são aproximadamente normais, mesmo que o histograma dos atrasos em si esteja longe de ser normal.
Você também pode ver que cada um dos três histogramas das médias das amostras está centrado muito próximo da média da população. Em cada caso, a “média das médias das amostras” é muito próxima de 16,66 minutos, a média da população. Ambos os valores são fornecidos na impressão acima de cada histograma. Como esperado, a média da amostra é uma estimativa não tendenciosa da média da população.
O Desvio Padrão de Todas as Médias das Amostras
Você também pode ver que os histogramas ficam mais estreitos e, portanto, mais altos, à medida que o tamanho da amostra aumenta. Já vimos isso antes, mas agora prestaremos mais atenção à medida de dispersão.
O desvio padrão de toda a população de atrasos é de aproximadamente 40 minutos.
pop_sd = np.std(delay.column('Delay'))
pop_sd| Out[5]: | 39.480199851609314 |
Dê uma olhada nos desvios padrão (SDs) nos histogramas das médias das amostras acima. Em todos os três, o SD da população de atrasos é de cerca de 40 minutos, porque todas as amostras foram retiradas da mesma população.
Agora, observe o SD de todas as 10.000 médias das amostras, quando o tamanho da amostra é 100. Esse SD é cerca de um décimo do SD da população. Quando o tamanho da amostra é 400, o SD de todas as médias das amostras é cerca de um vigésimo do SD da população. Quando o tamanho da amostra é 625, o SD das médias das amostras é cerca de um vigésimo quinto do SD da população.
Parece uma boa ideia comparar o SD da distribuição empírica das médias das amostras com a quantidade “SD da população dividido pela raiz quadrada do tamanho da amostra.”
Aqui estão os valores numéricos. Para cada tamanho de amostra na primeira coluna, foram retiradas 10.000 amostras aleatórias desse tamanho, e as 10.000 médias das amostras foram calculadas. A segunda coluna contém o SD dessas 10.000 médias das amostras. A terceira coluna contém o resultado do cálculo “SD da população dividido pela raiz quadrada do tamanho da amostra.”
A célula leva um tempo para ser executada, pois é uma simulação grande. Mas logo você verá que vale a pena esperar.
repetitions = 10000
sample_sizes = np.arange(25, 626, 25)
sd_means = make_array()
for n in sample_sizes:
means = make_array()
for i in np.arange(repetitions):
means = np.append(means, np.mean(delay.sample(n).column('Delay')))
sd_means = np.append(sd_means, np.std(means))
sd_comparison = Table().with_columns(
'Sample Size n', sample_sizes,
'SD of 10,000 Sample Means', sd_means,
'pop_sd/sqrt(n)', pop_sd/np.sqrt(sample_sizes)
)sd_comparison| Sample Size n | SD of 10,000 Sample Means | pop_sd/sqrt(n) |
|---|---|---|
| 25 | 7.94482 | 7.89604 |
| 50 | 5.6131 | 5.58334 |
| 75 | 4.57417 | 4.55878 |
| 100 | 3.98687 | 3.94802 |
| 125 | 3.49769 | 3.53122 |
| 150 | 3.22776 | 3.22354 |
| 175 | 3.00675 | 2.98442 |
| 200 | 2.77764 | 2.79167 |
| 225 | 2.64268 | 2.63201 |
| 250 | 2.49447 | 2.49695 |
Os valores na segunda e terceira colunas são muito próximos. Se traçarmos cada uma dessas colunas com o tamanho da amostra no eixo horizontal, os dois gráficos serão essencialmente indistinguíveis.
sd_comparison.plot('Sample Size n')
Na verdade, há duas curvas ali. Mas elas estão tão próximas uma da outra que parece que há apenas uma.
O que estamos vendo é um exemplo de um resultado geral. Lembre-se de que o gráfico acima é baseado em 10.000 replicatas para cada tamanho da amostra. Mas há muito mais do que 10.000 amostras de cada tamanho. A distribuição de probabilidade da média da amostra é baseada nas médias de todas as amostras possíveis de um tamanho fixo.
Fixe um tamanho de amostra. Se as amostras são retiradas aleatoriamente com reposição da população, então
Este é o desvio padrão das médias de todas as amostras possíveis que poderiam ser retiradas. Isso mede aproximadamente quão distantes as médias das amostras estão da média da população.
O Teorema do Limite Central para a Média da Amostra
Se você retirar uma grande amostra aleatória com reposição de uma população, então, independentemente da distribuição da população, a distribuição de probabilidade da média da amostra é aproximadamente normal, centrada na média da população, com um desvio padrão igual ao desvio padrão da população dividido pela raiz quadrada do tamanho da amostra.
A Precisão da Média da Amostra
O desvio padrão de todas as médias de amostra possíveis mede quão variável pode ser a média da amostra. Como tal, é considerado uma medida da precisão da média da amostra como uma estimativa da média da população. Quanto menor o desvio padrão, mais precisa é a estimativa.
A fórmula mostra que:
- O tamanho da população não afeta a precisão da média da amostra. O tamanho da população não aparece em nenhum lugar na fórmula.
- O desvio padrão da população é uma constante; é o mesmo para todas as amostras retiradas da população. O tamanho da amostra pode ser variado. Como o tamanho da amostra aparece no denominador, a variabilidade da média da amostra diminui à medida que o tamanho da amostra aumenta, e, portanto, a precisão aumenta.
A Lei da Raiz Quadrada
A partir da tabela de comparações de desvios padrão, pode-se ver que o desvio padrão das médias de amostras aleatórias de 25 atrasos de voo é cerca de 8 minutos. Se você multiplicar o tamanho da amostra por 4, obterá amostras de tamanho 100. O desvio padrão das médias de todas essas amostras é cerca de 4 minutos. Isso é menor do que 8 minutos, mas não é 4 vezes menor; é apenas 2 vezes menor. Isso ocorre porque o tamanho da amostra no denominador tem uma raiz quadrada sobre ele. O tamanho da amostra aumentou em um fator de 4, mas o desvio padrão diminuiu em um fator de 2 = √4. Em outras palavras, a precisão aumentou em um fator de 2 = √4.
Em geral, quando você multiplica o tamanho da amostra por um fator, a precisão da média da amostra aumenta pela raiz quadrada desse fator.
Portanto, para aumentar a precisão em um fator de 10, você precisa multiplicar o tamanho da amostra por um fator de 100. Precisão não vem barato!
| ← Capítulo 14.4 – O Teorema Central do Limite | Capítulo 14.6 – Escolhendo um Tamanho de Amostra → |