
Capítulo 13.3
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
%matplotlib inline
path_data = '../../../assets/data/'
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
import numpy as np
Intervalos de Confiança
Desenvolvemos um método para estimar um parâmetro usando amostragem aleatória e o bootstrap. Nosso método produz um intervalo de estimativas para levar em conta a variabilidade aleatória na amostra. Ao fornecer um intervalo de estimativas em vez de apenas uma estimativa, damos a nós mesmos uma margem de manobra.
No exemplo anterior, vimos que nosso processo de estimativa produziu um bom intervalo em cerca de 95% das vezes, um “bom” intervalo sendo aquele que contém o parâmetro. Dizemos que estamos 95% confiantes de que o processo resulta em um bom intervalo. Nosso intervalo de estimativas é chamado de intervalo de confiança de 95% para o parâmetro, e 95% é chamado de nível de confiança do intervalo.
O método é chamado de método percentil bootstrap porque o intervalo é formado selecionando dois percentis das estimativas bootstrap.
A situação no exemplo anterior foi um pouco incomum. Porque sabíamos o valor do parâmetro, pudemos verificar se um intervalo era bom ou ruim, e isso, por sua vez, nos ajudou a ver que nosso processo de estimativa capturou o parâmetro em cerca de 95 de cada 100 vezes que o usamos.
Mas geralmente, os cientistas de dados não sabem o valor do parâmetro. É por isso que eles querem estimá-lo em primeiro lugar. Nesses casos, eles fornecem um intervalo de estimativas para o parâmetro desconhecido usando métodos como o que desenvolvemos. Devido à teoria estatística e demonstrações como a que vimos, os cientistas de dados podem confiar que seu processo de geração do intervalo resulta em um bom intervalo uma porcentagem conhecida do tempo.
Estimando a Mediana de uma População
Agora usaremos o método bootstrap para estimar uma mediana populacional desconhecida. Você já encontrou o conjunto de dados antes. Ele vem de uma amostra de recém-nascidos em um grande sistema hospitalar. Vamos tratá-lo como se fosse uma amostra aleatória simples, embora a amostragem tenha sido feita em várias etapas. Stat Labs por Deborah Nolan e Terry Speed tem detalhes sobre um conjunto de dados maior do qual este conjunto foi extraído.
A tabela births contém as seguintes variáveis para pares mãe-bebê: o peso do bebê ao nascer em onças, o número de dias gestacionais (o número de dias que a mãe esteve grávida), a idade da mãe em anos completos, a altura da mãe em polegadas, o peso durante a gravidez em libras e se a mãe fumou durante a gravidez.
births = Table.read_table(path_data + 'baby.csv')births.show(3)| Birth Weight | Gestational Days | Maternal Age | Maternal Height | Maternal Pregnancy Weight | Maternal Smoker |
|---|---|---|---|---|---|
| 120 | 284 | 27 | 62 | 100 | False |
| 113 | 282 | 33 | 64 | 135 | False |
| 128 | 279 | 28 | 64 | 115 | True |
O peso ao nascer é um fator importante na saúde de um recém-nascido. Bebês menores tendem a precisar de mais cuidados médicos em seus primeiros dias do que os recém-nascidos maiores. Portanto, é útil ter uma estimativa do peso ao nascer antes do nascimento do bebê. Uma maneira de fazer isso é examinar a relação entre o peso ao nascer e o número de dias gestacionais.
Uma medida simples dessa relação é a razão entre o peso ao nascer e o número de dias gestacionais. A tabela ratios contém as duas primeiras colunas de baby, bem como uma coluna com as razões. A primeira entrada dessa coluna foi calculada da seguinte forma:
ratios = births.select('Birth Weight', 'Gestational Days').with_columns(
'Ratio BW:GD', births.column('Birth Weight')/births.column('Gestational Days')
)ratios| Birth Weight | Gestational Days | Ratio BW:GD |
|---|---|---|
| 120 | 284 | 0.422535 |
| 113 | 282 | 0.400709 |
| 128 | 279 | 0.458781 |
| 108 | 282 | 0.382979 |
| 136 | 286 | 0.475524 |
| 138 | 244 | 0.565574 |
| 132 | 245 | 0.538776 |
| 120 | 289 | 0.415225 |
| 143 | 299 | 0.478261 |
| 140 | 351 | 0.39886 |
Aqui está um histograma das proporções.
ratios.select('Ratio BW:GD').hist()
À primeira vista, o histograma parece bastante simétrico, com a densidade máxima no intervalo de 0,4 onças por dia a 0,45 onças por dia. Mas um olhar mais atento revela que algumas das proporções eram bastante grandes em comparação. O valor máximo da proporção era pouco mais de 0,78 onças por dia, quase o dobro do valor típico.
ratios.sort('Ratio BW:GD', descending=True).take(0)| Birth Weight | Gestational Days | Ratio BW:GD |
|---|---|---|
| 116 | 148 | 0.783784 |
A mediana dá uma ideia da proporção típica porque não é afetada pelas proporções muito grandes ou muito pequenas. A proporção média na amostra é de cerca de 0,429 onças por dia.
percentile(50, ratios.column(2))| Out[1]: | 0.42907801418439717 |
Mas qual era a mediana na população? Não sabemos, então vamos estimá-la.
Nosso método será exatamente o mesmo da seção anterior. Vamos aplicar o bootstrap na amostra 5.000 vezes, resultando em 5.000 estimativas da mediana. Nosso intervalo de confiança de 95% será os “95% centrais” de todas as nossas estimativas.
Construindo um Intervalo de Confiança Bootstrap
Começaremos definindo uma função one_bootstrap_median. Ela aplicará o bootstrap na amostra e retornará uma mediana da razão na amostra bootstrap.
def one_bootstrap_median():
resample = ratios.sample()
return percentile(50, resample.column('Ratio BW:GD'))Execute a célula abaixo para ver como as proporções inicializadas variam. Lembre-se de que cada uma delas é uma estimativa da proporção desconhecida na população.
one_bootstrap_median()| Out[2]: | 0.43010752688172044 |
Agora podemos usar um loop for para gerar 5.000 medianas inicializadas.
# Gere medianas de 5.000 amostras de bootstrap
num_repetitions = 5000
bstrap_medians = make_array()
for i in np.arange(num_repetitions):
bstrap_medians = np.append(bstrap_medians, one_bootstrap_median())# Obtenha os pontos finais do intervalo de confiança de 95%
left = percentile(2.5, bstrap_medians)
right = percentile(97.5, bstrap_medians)
make_array(left, right)| Out[3]: | array([0.42545455, 0.43272727]) |
O intervalo de confiança de 95% vai de cerca de 0,425 onças por dia a cerca de 0,433 onças por dia. Estamos estimando que a mediana da razão “peso ao nascer para dias de gestação” na população está em algum lugar no intervalo de 0,425 onças por dia a 0,433 onças por dia.
A estimativa de 0,429 baseada na amostra original está, por acaso, exatamente no meio do intervalo, embora isso não precise ser verdade em geral.
Para visualizar nossos resultados, vamos desenhar o histograma empírico de nossas medianas de bootstrap e colocar o intervalo de confiança no eixo horizontal.
resampled_medians = Table().with_columns(
'Bootstrap Sample Median', bstrap_medians
)
resampled_medians.hist(bins=15)
plots.plot([left, right], [0, 0], color='yellow', lw=8);
Este histograma e intervalo se assemelham aos que desenhamos na seção anterior, com uma grande diferença – não há ponto verde mostrando onde está o parâmetro. Não sabemos onde esse ponto deveria estar, ou se está no intervalo.
Temos apenas um intervalo de estimativas. É um intervalo de confiança de 95% das estimativas, porque o processo que o gera produz um bom intervalo cerca de 95% das vezes. Isso certamente é melhor do que adivinhar a razão aleatoriamente!
Tenha em mente que este intervalo é um intervalo de confiança aproximado de 95%. Existem muitas aproximações envolvidas em seu cálculo. A aproximação não é ruim, mas não é exata.
Estimando uma Média Populacional
O que fizemos para as medianas também pode ser feito para as médias. Suponha que queremos estimar a idade média das mães na população. Uma estimativa natural é a idade média das mães na amostra. Aqui está a distribuição de suas idades, e sua idade média que foi cerca de 27,2 anos.
births.select('Maternal Age').hist()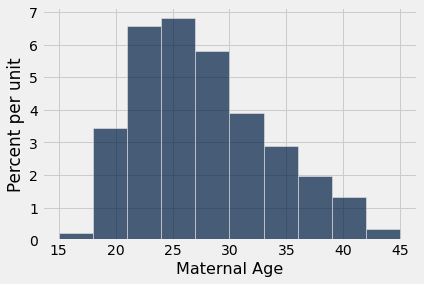
np.average(births.column('Maternal Age'))| Out[4]: | 27.228279386712096 |
Qual era a idade média das mães da população? Não sabemos o valor deste parâmetro.
Vamos estimar o parâmetro desconhecido pelo método bootstrap. Para fazer isso, adaptaremos o código de bootstrap_median para definir a função bootstrap_mean. O código é o mesmo, exceto que as estatísticas são médias (ou seja, médias) em vez de medianas, e são coletados em uma matriz chamada bstrap_means em vez de bstrap_medians.
def one_bootstrap_mean():
resample = births.sample()
return np.average(resample.column('Maternal Age'))# Gere médias a partir de 5.000 amostras de bootstrap
num_repetitions = 5000
bstrap_means = make_array()
for i in np.arange(num_repetitions):
bstrap_means = np.append(bstrap_means, one_bootstrap_mean())# Obtenha os pontos finais do intervalo de confiança de 95%
left = percentile(2.5, bstrap_means)
right = percentile(97.5, bstrap_means)
make_array(left, right)| Out[5]: | array([26.90630324, 27.55962521]) |
O intervalo de confiança de 95% vai de cerca de 26,9 anos a cerca de 27,6 anos. Ou seja, estamos estimando que a idade média das mães na população está em algum lugar no intervalo de 26,9 anos a 27,6 anos.
Observe como os dois extremos estão próximos à média de cerca de 27,2 anos na amostra original. O tamanho da amostra é muito grande – 1.174 mães – e, portanto, as médias das amostras não variam muito. Vamos explorar essa observação mais detalhadamente no próximo capítulo.
O histograma empírico das 5.000 idades médias de bootstrap é mostrado abaixo, junto com o intervalo de confiança de 95% para a idade média da população.
resampled_means = Table().with_columns(
'Bootstrap Sample Mean', bstrap_means
)
resampled_means.hist(bins=15)
plots.plot([left, right], [0, 0], color='yellow', lw=8);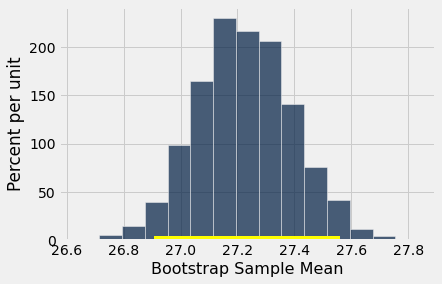
Mais uma vez, a média da amostra original (27,23 anos) está próxima do centro do intervalo. Isso não é muito surpreendente, porque cada amostra inicializada é extraída da mesma amostra original. As médias das amostras inicializadas são distribuídas aproximadamente simetricamente em ambos os lados da média da amostra da qual foram extraídos.
Observe também que o histograma empírico das médias reamostradas tem aproximadamente um formato de sino simétrico, embora o histograma das idades amostradas não fosse nada simétrico:
births.select('Maternal Age').hist()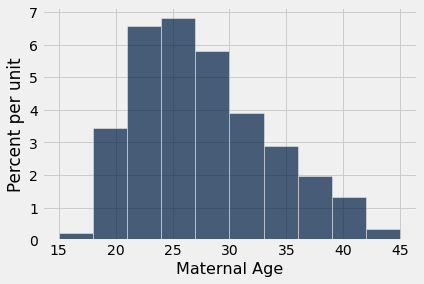
Isso é uma consequência do Teorema do Limite Central da probabilidade e da estatística. Nas seções posteriores, veremos o que o teorema diz.
Um intervalo de confiança de 80%
Você pode usar as médias amostrais bootstrapped para construir um intervalo de qualquer nível de confiança. Por exemplo, para construir um intervalo de confiança de 80% para a idade média da população, você pegaria os “80% médios” da amostra reamostrada. significa. Portanto, você desejaria 10% da distribuição em cada uma das duas caudas e, portanto, os pontos finais seriam os percentis 10 e 90 das médias reamostradas.
left_80 = percentile(10, bstrap_means)
right_80 = percentile(90, bstrap_means)
make_array(left_80, right_80)| Out[6]: | array([27.01277683, 27.44293015]) |
resampled_means.hist(bins=15)
plots.plot([left_80, right_80], [0, 0], color='yellow', lw=8);
Este intervalo de confiança de 80% é muito mais curto do que o intervalo de confiança de 95%. Ele vai apenas de cerca de 27,0 anos a cerca de 27,4 anos. Embora esse seja um conjunto estreito de estimativas, você sabe que esse processo produz um bom intervalo apenas cerca de 80% das vezes.
O processo anterior produziu um intervalo mais amplo, mas tínhamos mais confiança no processo que o gerou.
Para obter um intervalo de confiança estreito em um alto nível de confiança, você terá que começar com uma amostra maior. Veremos por que no próximo capítulo.
Estimando uma Proporção Populacional
Na amostra, 39% das mães fumaram durante a gravidez.
births.where('Maternal Smoker', are.equal_to(True)).num_rows / births.num_rows| Out[7]: | 0.3909710391822828 |
Lembre-se de que uma proporção é uma média de zeros e uns. Portanto, a proporção de mães que fumavam também poderia ser calculada usando operações de array como segue.
smoking = births.column('Maternal Smoker')
np.count_nonzero(smoking) / len(smoking)| Out[8]: | 0.3909710391822828 |
Qual a percentagem de mães na população que fumaram durante a gravidez? Este é um parâmetro desconhecido que podemos estimar através de um intervalo de confiança de bootstrap. Os passos são análogos aos que tomamos para estimar a mediana e a média da população.
Em um processo que agora é familiar, começaremos definindo uma função one_bootstrap_proportion que inicializa a amostra e retorna a proporção de fumantes na amostra inicializada. Em seguida, chamaremos a função várias vezes usando um loop for e obteremos o percentil 2,5 e o percentil 97,5 das proporções bootstrapped.
def one_bootstrap_proportion():
resample = births.sample()
smoking = resample.column('Maternal Smoker')
return np.count_nonzero(smoking) / len(smoking)# Gere proporções a partir de 5.000 amostras de bootstrap
bstrap_proportions = make_array()
num_repetitions = 5000
for i in np.arange(num_repetitions):
bstrap_proportions = np.append(bstrap_proportions, one_bootstrap_proportion())# Obtenha os pontos finais do intervalo de confiança de 95%
left = percentile(2.5, bstrap_proportions)
right = percentile(97.5, bstrap_proportions)
make_array(left, right)| Out[9]: | array([0.36286201, 0.41908007]) |
O intervalo de confiança vai de cerca de 36% para cerca de 42%.
resampled_proportions = Table().with_columns(
'Bootstrap Sample Proportion', bstrap_proportions
)
resampled_proportions.hist(bins=15)
plots.plot([left, right], [0, 0], color='yellow', lw=8);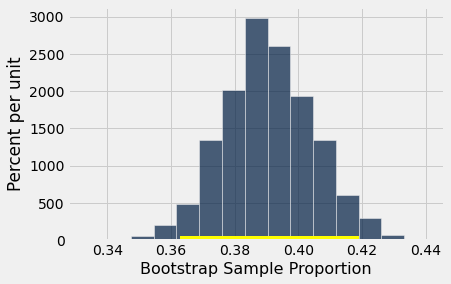
Cuidados ao Usar o Método Percentil de Bootstrap
O bootstrap é um método elegante e poderoso. Antes de usá-lo, é importante ter em mente alguns pontos.
- Comece com uma amostra aleatória grande. Se não o fizer, o método pode não funcionar. Seu sucesso é baseado em grandes amostras aleatórias (e, portanto, também em reamostras da amostra) que se assemelham à população. A Lei das Médias diz que isso é provável, desde que a amostra aleatória seja grande.
- Para aproximar a distribuição de probabilidade de uma estatística, é uma boa ideia replicar o procedimento de reamostragem tantas vezes quanto possível. Algumas milhares de replicações resultarão em aproximações decentes da distribuição da mediana da amostra, especialmente se a distribuição da população tiver um pico e for bastante simétrica. Usamos 5.000 replicações em nossos exemplos, mas recomendaríamos 10.000 em geral.
-
O método percentil de bootstrap funciona bem para estimar a mediana ou média populacional com base em uma grande amostra aleatória. No entanto, tem limitações, como todos os métodos de estimativa. Por exemplo, não se espera que funcione bem nas seguintes situações.
- O objetivo é estimar o valor mínimo ou máximo na população, ou um percentil muito baixo ou muito alto, ou parâmetros que são fortemente influenciados por elementos raros da população.
- A distribuição de probabilidade da estatística não é aproximadamente em forma de sino.
- A amostra original é muito pequena, digamos menos de 10 ou 15.
| ← Capítulo 13.2 – Bootstrap | Capítulo 13.4 – Usando os Intervalos → |