
Capítulo 11.3
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
%matplotlib inline
path_data = '../../../assets/data/'
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
import numpy as np
Decisões e Incerteza
A metodologia estatística e computacional que desenvolvemos para avaliar modelos sobre seleção de júris se encaixa em um quadro geral de tomada de decisão chamado testes estatísticos de hipóteses. Usar testes estatísticos como uma maneira de tomar decisões é padrão em muitos campos e possui uma terminologia padronizada.
Nesta seção, descreveremos a sequência geral das etapas usadas em testes estatísticos, junto com alguns termos técnicos.
Embora nosso exemplo seja das ciências biológicas, você verá que as etapas estatísticas e computacionais no processo são consistentes com as etapas correspondentes em nossas análises de dados do sistema legal. No entanto, os dados biológicos são sobre plantas, não seres humanos e injustiça. Portanto, o contexto e a interpretação dos cálculos abaixo são muito mais simples.
Gregor Mendel (1822-1884) foi um monge austríaco amplamente reconhecido como o fundador do campo moderno da genética. Mendel realizou experimentos cuidadosos em larga escala com plantas para formular leis fundamentais da genética.
Muitos de seus experimentos foram com variedades de plantas de ervilha. Ele formulou conjuntos de pressupostos sobre cada variedade; esses eram seus modelos. Em seguida, ele testou a validade de seus modelos cultivando as plantas e coletando dados.
Para plantas de ervilha de uma variedade específica, Mendel propôs o seguinte modelo.
Modelo de Mendel
Para cada planta, há uma chance de 75% de que ela tenha flores roxas, e uma chance de 25% de que as flores sejam brancas, independentemente das cores de todas as outras plantas.
Para ver se seu modelo era válido, Mendel cultivou 929 plantas de ervilha dessa variedade. Entre essas 929 plantas, 705 tinham flores roxas.
Usaremos esses dados para realizar um teste de hipóteses e ver se o modelo de Mendel parece bom.
Etapa 1: As Hipóteses
Todos os testes estatísticos tentam escolher entre duas visões de mundo. Especificamente, a escolha é entre duas visões sobre como os dados foram gerados. Essas duas visões são chamadas de hipóteses.
A hipótese nula. Esta é um modelo claramente definido sobre chances. Ela diz que os dados foram gerados aleatoriamente sob pressupostos claramente especificados sobre a aleatoriedade. A palavra “nula” reforça a ideia de que, se os dados parecem diferentes do que a hipótese nula prevê, a diferença é devida apenas ao acaso.
Do ponto de vista prático, a hipótese nula é uma hipótese sob a qual você pode simular dados.
No exemplo sobre o modelo de Mendel para as cores das plantas de ervilha, a hipótese nula é que os pressupostos de seu modelo são bons: cada planta tem uma chance de 75% de ter flores roxas, independentemente de todas as outras plantas.
Sob esta hipótese, podemos simular amostras aleatórias usando sample_proportions.
A hipótese alternativa. Isso diz que alguma razão diferente do acaso fez os dados diferirem das previsões do modelo na hipótese nula.
No exemplo das plantas de Mendel, a hipótese alternativa é simplesmente que seu modelo não é bom.
Lembre-se de que a alternativa não diz como ou por que o modelo não é bom. Apenas diz que o modelo não é bom.
Passo 2: O Estatístico de Teste
Para decidir entre as duas hipóteses, devemos escolher uma estatística que possamos usar para tomar a decisão. Isso é chamado de estatístico de teste.
Estaremos comparando duas distribuições categóricas: a de modelo de Mendel e a que obteremos em nossa amostra aleatória. Queremos ver se essas duas distribuições são próximas ou distantes uma da outra. Portanto, uma estatística de teste natural é a distância de variação total (TVD) desenvolvida na seção anterior.
Acontece que, com apenas duas categorias, o TVD é bastante simples e fácil de interpretar. Vamos olhar um exemplo. O modelo de Mendel diz que a distribuição “roxo, branco” é [0.75, 0.25]. Suponha que a distribuição em nossa amostra seja [0.7, 0.3].
Por haver apenas duas categorias, algo interessante acontece quando calculamos o TVD. Primeiro, observe que
Então, o TVD é
Isso é apenas a distância entre as duas proporções de plantas com flores roxas. Também é apenas a distância entre as duas proporções de plantas com flores brancas.
Por um pouco de matemática que não faremos aqui, isso é verdade sempre que houver apenas duas categorias: o TVD é igual à distância entre as duas proporções em uma categoria.
Portanto, um estatístico de teste perfeitamente adequado seria a distância entre a proporção da amostra de plantas roxas e 0,75, que é a proporção correspondente no modelo de Mendel.
Como os percentuais são mais fáceis de interpretar do que as proporções, trabalharemos com percentuais.
Nosso estatístico de teste será a distância entre o percentual da amostra de plantas roxas e 75%, que é o percentual correspondente no modelo de Mendel.
Este estatístico de teste é uma distância entre as duas distribuições. Faz sentido e é fácil de usar. Um percentual de amostra em torno de 75% será consistente com o modelo, mas percentuais muito maiores ou muito menores que 75 farão você pensar que o modelo não é bom. Portanto, valores pequenos da distância farão você tender para a hipótese nula. Valores grandes do estatístico farão você tender para a alternativa.
Para escolher um estatístico de teste em outras situações, observe a hipótese alternativa. Que valores do estatístico farão você pensar que a hipótese alternativa é uma escolha melhor do que a nula?
- Se a resposta for “valores grandes”, você tem uma boa escolha de estatístico.
- Também se a resposta for “valores pequenos”.
- Mas se a resposta for “tanto valores grandes quanto valores pequenos”, recomendamos que você olhe novamente para seu estatístico. Veja se usar uma distância em vez de uma diferença pode mudar a resposta para apenas “valores grandes”.
Valor Observado do Estatístico de Teste
O valor observado do estatístico de teste é o valor do estatístico que você obtém a partir dos dados no estudo, não um valor simulado. Entre as 929 plantas de Mendel, 705 tinham flores roxas. Portanto, o valor observado do estatístico de teste foi
observed_statistic = abs ( 100 * (705 / 929) - 75)
observed_statistic| Out[1]: | 0.8880516684607045 |
Passo 3: A Distribuição do Estatístico de Teste, Sob a Hipótese Nula
O aspecto computacional principal de um teste de hipóteses é descobrir o que o modelo na hipótese nula prevê. Especificamente, temos que descobrir quais são os valores do estatístico de teste que poderiam ocorrer se a hipótese nula fosse verdadeira.
O estatístico de teste é simulado com base nas suposições do modelo na hipótese nula. Esse modelo envolve chance, então o estatístico se comporta de maneira diferente quando você o simula várias vezes.
Ao simular o estatístico repetidamente, obtemos uma boa ideia de seus possíveis valores e quais são mais prováveis do que outros. Em outras palavras, obtemos uma boa aproximação da distribuição de probabilidade do estatístico, conforme previsto pelo modelo na hipótese nula.
Como em todas as distribuições, é muito útil visualizar essa distribuição por meio de um histograma, como fizemos em nossos exemplos anteriores. Vamos passar por todo o processo aqui.
Começaremos atribuindo alguns quantitativos conhecidos a nomes.
mendel_proportions = make_array(0.75, 0.25)
mendel_proportion_purple = mendel_proportions.item(0)
sample_size = 929A seguir, definiremos uma função que retorna um valor simulado da estatística de teste. Em seguida, usaremos um loop for para coletar 10.000 valores simulados em um array.
def one_simulated_distance():
sample_proportion_purple = sample_proportions(929, mendel_proportions).item(0)
return 100 * abs(sample_proportion_purple - mendel_proportion_purple)repetitions = 10000
distances = make_array()
for i in np.arange(repetitions):
distances = np.append(distances, one_simulated_distance())Agora podemos desenhar o histograma desses valores. Este é o histograma da distribuição da estatística de teste prevista pela hipótese nula.
Table().with_column(
'Distance between Sample % and 75%', distances
).hist()
plots.title('Prediction Made by the Null Hypothesis');
Observe no eixo horizontal para ver os valores típicos da distância, como previsto pelo modelo. Eles são bastante pequenos. Por exemplo, uma alta proporção das distâncias está na faixa de 0 a 1, o que significa que, para uma alta proporção das amostras, o percentual de plantas com flores roxas está na faixa de 75% +/- 1%. Ou seja, o percentual da amostra está na faixa de 74% a 76%.
Observe também que essa predição foi feita apenas usando o modelo de Mendel, não as proporções observadas por Mendel nas plantas que ele cultivou. É hora de comparar agora as previsões e a observação de Mendel.
Passo 4. A Conclusão do Teste
A escolha entre as hipóteses nula e alternativa depende da comparação entre o que você calculou nos Passos 2 e 3: o valor observado da estatística do teste e sua distribuição conforme previsto pela hipótese nula.
Se os dois não forem consistentes entre si, então os dados não suportam a hipótese nula. Em outras palavras, a hipótese alternativa é melhor suportada pelos dados. Dizemos que o teste rejeita a hipótese nula.
Se os dois forem consistentes entre si, então o valor observado da estatística do teste está alinhado com o que a hipótese nula prevê. Em outras palavras, a hipótese nula é melhor suportada pelos dados. Dizemos que os dados são consistentes com a hipótese nula.
Em nosso exemplo, o valor observado da estatística do teste é aproximadamente 0,89, conforme calculado no Passo 2 acima. Apenas olhando, localize aproximadamente onde 0,89 está no eixo horizontal do histograma. Você verá que está claramente no centro da distribuição prevista pelo modelo de Mendel.
A célula abaixo redesenha o histograma com o valor observado plotado no eixo horizontal.
Table().with_column(
'Distance between Sample % and 75%', distances
).hist()
plots.ylim(-0.02, 0.5)
plots.title('Prediction Made by the Null Hypothesis')
plots.scatter(observed_statistic, 0, color='red', s=40);
A estatística observada é como uma distância típica prevista pela hipótese nula. A hipótese nula é o modelo de Mendel. Portanto, nosso teste conclui que os dados são consistentes com o modelo de Mendel.
Com base em nossos dados, o modelo de Mendel parece adequado.
O Significado de “Consistente”
Em todos os nossos exemplos de avaliação de modelos, não houve dúvida sobre se os dados eram consistentes com as previsões do modelo. Eles estavam ou muito longe do que o modelo previa, como nos exemplos sobre painéis de júri, ou similares ao que o modelo previa, como no exemplo sobre o modelo de Mendel.
Mas os resultados nem sempre são tão claros. Até que ponto é “longe”? Exatamente o que “similar” deve significar? Embora essas perguntas não tenham respostas universais, existem algumas diretrizes e convenções que você pode seguir.
Mas primeiro, é importante entender que se a estatística de teste observada é consistente com sua distribuição prevista sob a hipótese nula é uma questão de opinião e julgamento subjetivo. Recomendamos que você forneça seu julgamento junto com o valor da estatística de teste e um gráfico de sua distribuição prevista sob o nulo. Isso permitirá que seus leitores façam seu próprio julgamento sobre se os dois são consistentes.
No exemplo acima, o julgamento é claro. Mas suponha que alguém cultivou mais 929 plantas de alguma variedade relacionada e quis ver se o modelo de Mendel funcionava para plantas dessa variedade também. O que você concluiria se a distância observada deles fosse de 3.2, como mostrado abaixo?
different_observed_statistic = 3.2
Table().with_column(
'Distance between Sample % and 75%', distances
).hist()
plots.ylim(-0.02, 0.5)
plots.title('Prediction Made by the Null Hypothesis')
plots.scatter(different_observed_statistic, 0, color='red', s=40);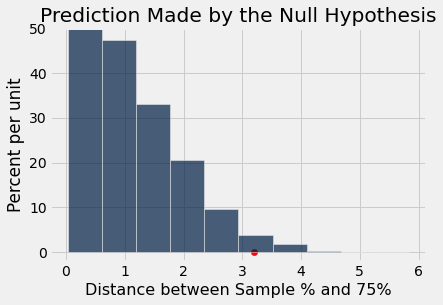
A observação baseada na nova variedade de plantas é consistente com as previsões no histograma, ou não?
Agora a resposta não é tão clara. Isso depende se você acha que o ponto vermelho está muito distante da maioria dos valores previstos para ser consistente com a previsão baseada no modelo de Mendel.
Limites Convencionais e o Valor P
Se você não quer usar seu próprio julgamento, existem convenções que você pode seguir. Essas convenções nos dizem até onde convencionalmente é considerado “muito longe” nas caudas.
As convenções são baseadas na área na cauda, começando pelo estatístico observado (o ponto vermelho) e olhando na direção que nos faz tender para a alternativa. Neste exemplo, é o lado direito, porque grandes distâncias favorecem a alternativa que diz que o modelo não é bom.
Se a área da cauda for pequena, o estatístico observado estará longe dos valores mais comumente previstos pela hipótese nula.
Lembre-se de que em um histograma, a área representa percentuais. Para encontrar a área na cauda, temos que encontrar o percentual de distâncias maiores ou iguais a 3.2, onde está o ponto vermelho. O array distances contém as médias para todas as 10.000 repetições da amostragem aleatória sob o modelo de Mendel, e different_observed_statistic é 3.2.
np.count_nonzero(distances >= different_observed_statistic) / repetitions| Out[2]: | 0.0243 |
Aproximadamente 2,4% das distâncias simuladas sob o modelo de Mendel foram de 3,2 ou mais. Pela lei das médias, podemos concluir que se o modelo de Mendel fosse correto para estas novas plantas, há cerca de 2,4% de chance de que a estatística de teste seja 3,2 ou mais.
Isso não parece ser uma grande chance. Se o modelo de Mendel for verdadeiro para estas plantas, algo bastante improvável aconteceu. Esta ideia dá origem às convenções.
O Valor-p
Esta chance tem um nome impressionante. É chamado de nível de significância observado do teste. Isso é um bocado, e por isso é comumente chamado de valor-p do teste.
Definição: O valor-p de um teste é a chance, com base no modelo na hipótese nula, de que a estatística de teste será igual ao valor observado na amostra ou ainda mais na direção que suporta a hipótese alternativa.
Se um valor-p for pequeno, isso significa que a cauda além da estatística observada é pequena e, portanto, a estatística observada está longe do que a nula prevê. Isso implica que os dados suportam mais a hipótese alternativa do que a nula.
Quão pequeno é “pequeno”? De acordo com as convenções:
- Se o valor-p for inferior a 5%, é considerado pequeno e o resultado é chamado de “estatisticamente significativo”.
- Se o valor-p for ainda menor – inferior a 1% – o resultado é chamado de “altamente estatisticamente significativo”.
Por esta convenção, nosso valor-p de 2,4% é considerado pequeno. Portanto, a conclusão convencional seria rejeitar a hipótese nula e dizer que o modelo de Mendel não parece bom para as novas plantas. Formalmente, o resultado do teste é estatisticamente significativo.
Ao fazer uma conclusão desta forma, recomendamos que você não apenas diga se o resultado é estatisticamente significativo ou não. Junto com sua conclusão, forneça também a estatística observada e o valor-p, para que os leitores possam usar seu próprio julgamento.
Nota Histórica sobre as Convenções
A determinação da significância estatística, conforme definido acima, tornou-se padrão em análises estatísticas em todos os campos de aplicação. Quando uma convenção é tão universalmente seguida, é interessante examinar como ela surgiu.
O método de teste estatístico – escolher entre hipóteses com base em dados em amostras aleatórias – foi desenvolvido por Sir Ronald Fisher no início do século 20. Sir Ronald pode ter definido a convenção para a significância estatística um tanto inconscientemente, na seguinte declaração em seu livro de 1925 Statistical Methods for Research Workers. Sobre o nível de 5%, ele escreveu: “É conveniente tomar este ponto como um limite para julgar se um desvio deve ser considerado significativo ou não”.
O que era “conveniente” para Sir Ronald tornou-se um limite que adquiriu o status de uma constante universal. Não importa que Sir Ronald mesmo tenha feito o ponto de que o valor foi sua escolha pessoal entre muitos: em um artigo em 1926, ele escreveu: “Se um em vinte não parece odds altos suficientes, nós podemos, se nós preferimos, desenhar a linha em um em cinquenta (o ponto 2 por cento), ou um em cem (o ponto 1 por cento). Pessoalmente, o autor prefere estabelecer um
baixo padrão de significância no ponto de 5 por cento …”
Fisher sabia que “baixo” é uma questão de julgamento e não tem definição única. Sugerimos que você também mantenha isso em mente. Forneça seus dados, faça seu julgamento e explique por que o fez.
Se você usar um corte convencional ou seu próprio julgamento, é importante manter os seguintes pontos em mente.
- Sempre forneça o valor observado da estatística de teste e o valor-p, para que os leitores possam decidir se acham ou não que o valor-p é pequeno.
- Não busque desafiar a convenção apenas quando o resultado derivado convencionalmente não lhe agrada.
- Mesmo que um teste conclua que os dados não suportam o modelo de chance na hipótese nula, o teste geralmente não explica por que o modelo não funciona. Não faça conclusões causais sem análise adicional, a menos que você esteja executando um ensaio controlado randomizado. Analisaremos esses casos em uma seção posterior.
| ← Capítulo 11.2 – Múltiplas Categorias | Capítulo 11.4 – Probabilidades de Erro → |