
Capítulo 14.3
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
%matplotlib inline
path_data = '../../../assets/data/'
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
import math
import numpy as np
O Desvio Padrão (SD) e a Curva Normal
Sabemos que a média é o ponto de equilíbrio do histograma. Ao contrário da média, o SD geralmente não é fácil de identificar apenas olhando para o histograma.
No entanto, há um formato de distribuição para o qual o SD é quase tão claramente identificável quanto a média. Esse é o formato de sino. Esta seção examina esse formato, pois ele aparece frequentemente em histogramas de probabilidade e também em alguns histogramas de dados.
Um Histograma Aproximadamente em Forma de Sino de Dados
Vamos olhar para a distribuição das alturas das mães em nossa amostra familiar de 1.174 pares mãe-recém-nascido. As alturas das mães têm uma média de 64 polegadas e um SD de 2,5 polegadas. Ao contrário das alturas dos jogadores de basquete, as alturas das mães são distribuídas de forma bastante simétrica em torno da média em uma curva em forma de sino.
baby = Table.read_table(path_data + 'baby.csv')
heights = baby.column('Maternal Height')
mean_height = np.round(np.mean(heights), 1)
mean_height| Out[1]: | 64.0 |
sd_height = np.round(np.std(heights), 1)
sd_height| Out[2]: | 2.5 |
baby.hist('Maternal Height', bins=np.arange(55.5, 72.5, 1), unit='inch')
positions = np.arange(-3, 3.1, 1)*sd_height + mean_height
plots.xticks(positions);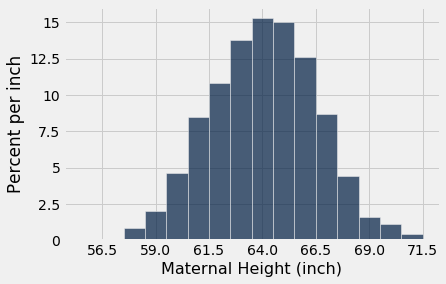
As duas últimas linhas de código na célula acima alteram a rotulagem do eixo horizontal. Agora, os rótulos correspondem a “média ± z SDs” para z = 0, ± 1, ± 2, e ± 3. Devido ao formato da distribuição, o “centro” tem um significado inequívoco e é claramente visível em 64.
Como identificar o SD em uma curva em forma de sino
Para ver como o SD está relacionado à curva, comece no topo da curva e olhe para a direita. Note que há um ponto onde a curva muda de um formato de ‘U’ invertido para um formato de ‘U’ normal”; formalmente, a curva tem um ponto de inflexão. Esse ponto está um desvio padrão acima da média. É o ponto z=1, que é “média mais 1 SD” = 66.5 polegadas.
Simetricamente, no lado esquerdo da média, o ponto de inflexão está em z=-1, ou seja, “média menos 1 SD” = 61.5 polegadas.
Em geral, para distribuições em forma de sino, o SD é a distância entre a média e os pontos de inflexão de cada lado.
A curva normal padrão
Todos os histogramas em forma de sino que vimos têm essencialmente a mesma aparência, exceto pelos rótulos nos eixos. De fato, há apenas uma curva básica da qual todas essas curvas podem ser desenhadas apenas rotulando os eixos de maneira apropriada.
Para desenhar essa curva básica, usaremos as unidades nas quais podemos converter cada lista: unidades padrão. A curva resultante é, portanto, chamada de curva normal padrão.
A curva normal padrão tem uma equação impressionante. Mas, por enquanto, é melhor pensá-la como um contorno suavizado de um histograma de uma variável que foi medida em unidades padrão e tem uma distribuição em forma de sino.
# A curva normal padrão
plot_normal_cdf()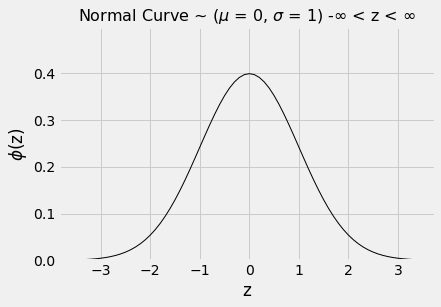
Como sempre ao examinar um novo histograma, comece olhando para o eixo horizontal. No eixo horizontal da curva normal padrão, os valores são unidades padrão.
Aqui estão algumas propriedades da curva. Algumas são aparentes por observação, e outras requerem uma quantidade considerável de matemática para serem estabelecidas.
- A área total sob a curva é 1. Então, você pode pensar nela como um histograma desenhado na escala de densidade.
- A curva é simétrica em torno de 0. Portanto, se uma variável tem essa distribuição, sua média e mediana são ambas 0.
- Os pontos de inflexão da curva estão em -1 e +1.
- Se uma variável tem essa distribuição, seu desvio padrão é 1. A curva normal é uma das poucas distribuições que tem um desvio padrão tão claramente identificável no histograma.
Como estamos pensando na curva como um histograma suavizado, queremos representar proporções do total de dados por áreas sob a curva.
Áreas sob curvas suaves são frequentemente encontradas por cálculo, usando um método chamado integração. No entanto, é um fato da matemática que a curva normal padrão não pode ser integrada de nenhuma das maneiras usuais do cálculo.
Portanto, as áreas sob a curva devem ser aproximadas. É por isso que quase todos os livros de estatística carregam tabelas de áreas sob a curva normal. Também é por isso que todos os sistemas estatísticos, incluindo um módulo do Python, incluem métodos que fornecem excelentes aproximações dessas áreas.
from scipy import stats
A “cdf” normal padrão
A função fundamental para encontrar áreas sob a curva normal é stats.norm.cdf. Ela recebe um argumento numérico e retorna toda a área sob a curva à esquerda desse número. Formalmente, é chamada de “função de distribuição cumulativa” da curva normal padrão. Esse termo bastante complicado é abreviado como cdf.
Vamos usar essa função para encontrar a área à esquerda de z=1 sob a curva normal padrão.
# Área sob a curva normal padrão, abaixo de 1
plot_normal_cdf(1)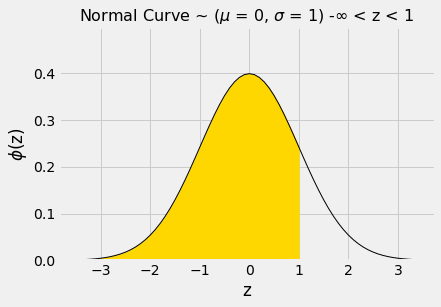
O valor numérico da área sombreada pode ser encontrado chamando stats.norm.cdf.
stats.norm.cdf(1)| Out[3]: | 0.8413447460685429 |
Isso é cerca de 84%. Agora podemos usar a simetria da curva e o fato de que a área total sob a curva é 1 para encontrar outras áreas.
A área à direita de z=1 é cerca de 100% – 84% = 16%.
# Área sob a curva normal padrão, acima de 1
plot_normal_cdf(lbound=1)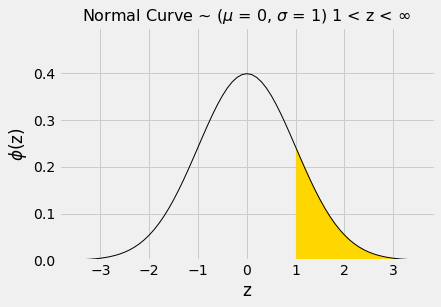
1 - stats.norm.cdf(1)| Out[4]: | 0.15865525393145707 |
A área entre z=-1 e z=1 pode ser calculada de várias maneiras diferentes. É a área de ouro sob a curva abaixo.
# Área sob a curva normal padrão, entre -1 e 1
plot_normal_cdf(1, lbound=-1)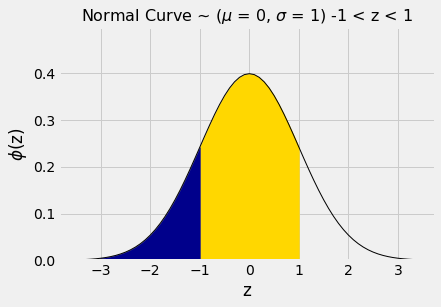
Por exemplo, poderíamos calcular a área como “100% – duas caudas iguais”, o que resulta em aproximadamente 100% – 2×16% = 68%.
Ou poderíamos notar que a área entre z=1 e z=-1 é igual a toda a área à esquerda de z=1, menos toda a área à esquerda de z=-1.
stats.norm.cdf(1) - stats.norm.cdf(-1)| Out[5]: | 0.6826894921370859 |
Por um cálculo semelhante, vemos que a área entre -2 e 2 é de cerca de 95%.
# Área sob a curva normal padrão, entre -2 e 2
plot_normal_cdf(2, lbound=-2)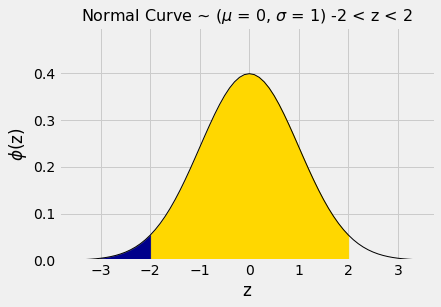
stats.norm.cdf(2) - stats.norm.cdf(-2)| Out[5]: | 0.9544997361036416 |
Em outras palavras, se um histograma tem uma forma aproximadamente de sino, a proporção de dados no intervalo “média ± 2 SDs” é de cerca de 95%.
Isso é consideravelmente maior do que o limite inferior de Chebychev de 75%. O limite de Chebychev é mais fraco porque precisa funcionar para todas as distribuições. Se sabemos que uma distribuição é normal, temos boas aproximações para as proporções, não apenas limites.
A tabela abaixo compara o que sabemos sobre todas as distribuições e sobre distribuições normais. Note que quando z=1, o limite de Chebychev está correto, mas não é esclarecedor.
| Percentual no Intervalo | Todas as Distribuições: Limite | Distribuição Normal: Aproximação |
|---|---|---|
| média ± 1 SD | pelo menos 0% | cerca de 68% |
| média ± 2 SDs | pelo menos 75% | cerca de 95% |
| média ± 3 SDs | pelo menos 88.888…% | cerca de 99.73% |
| ← Capítulo 14.2 – Variabilidade | Capítulo 14.4 – O Teorema Central do Limite → |