
Capítulo 10.1
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
path_data = '../../../assets/data/'
import matplotlib
matplotlib.use('Agg')
%matplotlib inline
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
import numpy as np
Distribuições Empíricas
Em ciência de dados, a palavra “empírica” significa “observada”. Distribuições empíricas são distribuições de dados observados, como dados em amostras aleatórias.
Nesta seção, vamos gerar dados e ver como é a distribuição empírica.
Nosso cenário é um experimento simples: lançar um dado várias vezes e acompanhar qual face aparece. A tabela die contém os números de pontos nas faces de um dado. Todos os números aparecem exatamente uma vez, pois estamos assumindo que o dado é justo.
die = Table().with_column('Face', np.arange(1, 7, 1))
die| Face |
|---|
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
Uma Distribuição de Probabilidade
O histograma abaixo nos ajuda a visualizar o fato de que cada face aparece com probabilidade de 1/6. Dizemos que o histograma mostra a distribuição das probabilidades sobre todas as faces possíveis. Como todas as barras representam a mesma chance percentual, a distribuição é chamada de uniforme nos inteiros de 1 a 6.
die_bins = np.arange(0.5, 6.6, 1)
die.hist(bins = die_bins)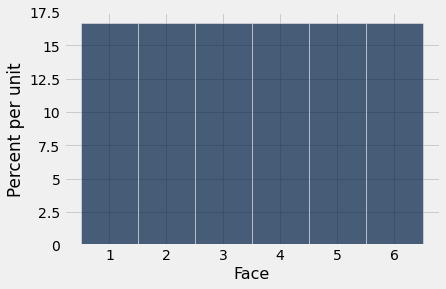
Variáveis cujos valores sucessivos são separados pela mesma quantidade fixa, como os valores nos lançamentos de um dado (valores sucessivos separados por 1), pertencem a uma classe de variáveis chamadas discretas. O histograma acima é chamado de histograma discreto. Seus intervalos são especificados pelo array die_bins e garantem que cada barra esteja centralizada sobre o valor inteiro correspondente.
É importante lembrar que o dado não pode mostrar 1,3 pontos ou 5,2 pontos – ele sempre mostra um número inteiro de pontos. Mas nossa visualização distribui a probabilidade de cada valor sobre a área de uma barra. Embora isso possa parecer um pouco arbitrário neste estágio do curso, será importante mais tarde quando sobrepormos curvas suaves sobre histogramas discretos.
Antes de prosseguir, vamos garantir que os números nos eixos façam sentido. A probabilidade de cada face é 1/6, o que é 16,67% quando arredondado para duas casas decimais. A largura de cada intervalo é de 1 unidade. Portanto, a altura de cada barra é de 16,67% por unidade. Isso concorda com as escalas horizontal e vertical do gráfico.
Distribuições Empíricas
A distribuição acima consiste na probabilidade teórica de cada face. É chamada de distribuição de probabilidade e não é baseada em dados observados. Pode ser estudada e entendida sem que qualquer dado seja lançado.
Distribuições empíricas, por outro lado, são distribuições de dados observados. Elas podem ser visualizadas por histogramas empíricos.
Vamos obter alguns dados simulando lançamentos de um dado. Isso pode ser feito amostrando aleatoriamente com reposição dos inteiros de 1 a 6. Já usamos np.random.choice para essas simulações antes. Mas agora vamos introduzir um método da Tabela para fazer isso. Isso tornará mais fácil usarmos nossos métodos de Tabela familiares para visualização.
O método da Tabela é chamado sample. Ele faz sorteios aleatórios com reposição das linhas de uma tabela. Seu argumento é o tamanho da amostra, e ele retorna uma tabela consistindo das linhas que foram selecionadas. Um argumento opcional with_replacement=False especifica que a amostra deve ser extraída sem reposição. Mas isso não se aplica ao lançamento de um dado.
Aqui estão os resultados de 10 lançamentos de um dado.
die.sample(10)| Face |
|---|
| 2 |
| 5 |
| 1 |
| 3 |
| 6 |
| 4 |
| 3 |
| 1 |
| 5 |
| 2 |
Podemos usar o mesmo método para simular quantas jogadas quisermos e, em seguida, desenhar histogramas empíricos dos resultados. Como faremos isso repetidamente, definimos uma função empirical_hist_die que toma o tamanho da amostra como argumento, lança um dado tantas vezes quanto o argumento e depois desenha um histograma dos resultados observados.
def empirical_hist_die(n):
die.sample(n).hist(bins = die_bins)Histogramas Empíricos
Aqui está um histograma empírico de 10 lançamentos. Não se parece muito com o histograma de probabilidade acima. Execute a célula algumas vezes para ver como ela varia.
empirical_hist_die(10)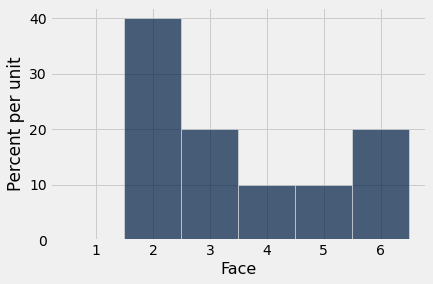
Quando o tamanho da amostra aumenta, o histograma empírico começa a se parecer mais com o histograma de probabilidades teóricas.
empirical_hist_die(100)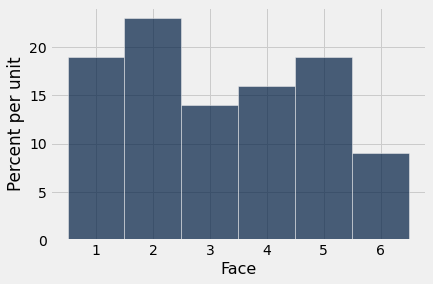
empirical_hist_die(1000)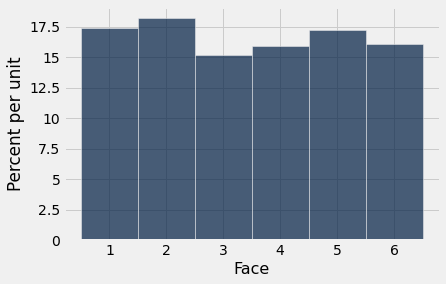
À medida que aumentamos o número de lançamentos na simulação, a área de cada barra se aproxima de 16,67%, que é a área de cada barra no histograma de probabilidade.
A Lei das Médias
O que observamos acima é um exemplo de uma regra geral chamada lei das médias:
Se um experimento aleatório é repetido de forma independente e em condições idênticas, então, a longo prazo, a proporção de vezes que um evento ocorre se aproxima cada vez mais da probabilidade teórica do evento.
Por exemplo, a longo prazo, a proporção de vezes que a face com quatro pontos aparece se aproxima cada vez mais de 1/6.
Aqui, “independentemente e em condições idênticas” significa que cada repetição é realizada da mesma maneira, independentemente dos resultados de todas as outras repetições.
Sob essas condições, a lei acima implica que, se o experimento aleatório for repetido um grande número de vezes, a proporção de vezes que um evento ocorre tem grande probabilidade de se aproximar da probabilidade teórica do evento.
| ← Capítulo 10 – Amostragem e Distribuições Empíricas | Capítulo 10.2 – Amostragem de uma População → |