
Capítulo 10.3
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
path_data = '../../../assets/data/'
import matplotlib
matplotlib.use('Agg')
%matplotlib inline
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
import numpy as np
Distribuição Empírica de uma Estatística
A Lei das Médias implica que, com alta probabilidade, a distribuição empírica de uma grande amostra aleatória se assemelhará à distribuição da população da qual a amostra foi extraída.
A semelhança é visível em dois histogramas: o histograma empírico de uma grande amostra aleatória provavelmente se assemelha ao histograma da população.
Como lembrete, aqui está o histograma dos atrasos de todos os voos em united, e um histograma empírico dos atrasos de uma amostra aleatória de 1.000 desses voos.
united = Table.read_table(path_data + 'united_summer2015.csv')
delay_bins = np.arange(-20, 201, 10)
united.hist('Delay', bins = delay_bins, unit = 'minute')
plots.title('Population');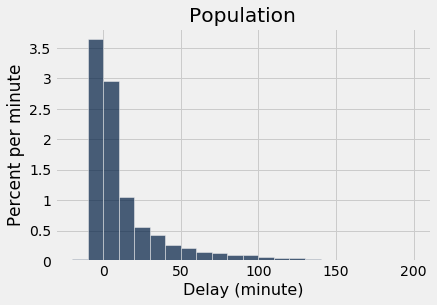
sample_1000 = united.sample(1000)
sample_1000.hist('Delay', bins = delay_bins, unit = 'minute')
plots.title('Sample of Size 1000');
Os dois histogramas claramente se assemelham, embora não sejam idênticos.
Parâmetro
Frequentemente, estamos interessados em quantidades numéricas associadas a uma população.
- Em uma população de eleitores, qual percentual votará no Candidato A?
- Em uma população de usuários do Facebook, qual é o maior número de amigos no Facebook que os usuários têm?
- Em uma população de voos da United, qual é o atraso de partida mediano?
Quantidades numéricas associadas a uma população são chamadas de parâmetros. Para a população de voos em united, sabemos o valor do parâmetro “atraso mediano”:
np.median(united.column('Delay'))| Out[1]: | 2 |
A função NumPy median retorna a mediana (ponto intermediário) de um array. Entre todos os voos em united, o atraso médio foi de 2 minutos. Ou seja, cerca de 50% dos voos da população tiveram atrasos de 2 minutos ou menos:
united.where('Delay', are.below_or_equal_to(2)).num_rows / united.num_rows| Out[2]: | 0.5017720795297 |
Metade de todos os voos partiram no máximo 2 minutos após o horário de partida programado. Isso é um atraso muito curto!
Nota. A porcentagem não é exatamente 50% por causa dos “empates”, ou seja, voos que tiveram atrasos de exatamente 2 minutos. Houve 480 desses voos. Empates são bastante comuns em conjuntos de dados e não nos preocuparemos com eles neste curso.
united.where('Delay', are.equal_to(2)).num_rows| Out[3]: | 480 |
Estatística
Em muitas situações, estaremos interessados em descobrir o valor de um parâmetro desconhecido. Para isso, vamos depender de dados de uma grande amostra aleatória retirada da população.
Uma estatística (note o singular!) é qualquer número calculado usando os dados de uma amostra. Portanto, a mediana da amostra é uma estatística.
Lembre-se de que sample_1000 contém uma amostra aleatória de 1000 voos da united. O valor observado da mediana da amostra é:
np.median(sample_1000.column('Delay'))| Out[4]: | 2.0 |
Nosso exemplo – um conjunto de 1.000 voos – nos forneceu um valor observado da estatística. Isso levanta um problema importante de inferência:
A estatística poderia ter sido diferente.
Uma consideração fundamental ao usar qualquer estatística baseada em uma amostra aleatória é que a amostra poderia ter sido diferente e, portanto, a estatística também poderia ter sido diferente.
np.median(united.sample(1000).column('Delay'))| Out[5]: | 3.0 |
Execute a célula acima algumas vezes para ver como a resposta varia. Muitas vezes é igual a 2, o mesmo valor do parâmetro populacional. Mas às vezes é diferente.
Quão diferente a estatística poderia ter sido? Uma maneira de responder a isso é simular a estatística muitas vezes e anotar os valores. Um histograma desses valores nos informará sobre a distribuição da estatística.
Vamos relembrar as principais etapas de uma simulação.
Simulando uma Estatística
Vamos simular a mediana da amostra usando os passos que configuramos em um capítulo anterior quando começamos a estudar simulação. Você pode substituir o tamanho da amostra de 1000 por qualquer outro tamanho de amostra, e a mediana da amostra por qualquer outra estatística.
Passo 1: Decida qual estatística simular. Já decidimos isso: vamos simular a mediana de uma amostra aleatória de tamanho 1000 retirada da população de atrasos de voos.
Passo 2: Defina uma função que retorne um valor simulado da estatística. Extraia uma amostra aleatória de tamanho 1000 e calcule a mediana da amostra. Fizemos isso na célula de código acima. Aqui está novamente, encapsulado em uma função.
def random_sample_median():
return np.median(united.sample(1000).column('Delay'))
Passo 3: Decidir quantos valores simulados gerar. Vamos fazer 5.000 repetições.
Passo 4: Usar um loop for para gerar um array de valores simulados. Como de costume, começaremos criando um array vazio para coletar nossos resultados. Em seguida, configuraremos um loop for para gerar todos os valores simulados. O corpo do loop consistirá em gerar um valor simulado da mediana da amostra e adicioná-lo ao nosso array de resultados.
A simulação leva um tempo perceptível para ser executada. Isso ocorre porque ela está realizando 5.000 repetições do processo de amostragem de tamanho 1.000 e computando sua mediana. Isso significa muita amostragem e repetição!
medians = make_array()
for i in np.arange(5000):
medians = np.append(medians, random_sample_median())
A simulação está concluída. Todas as 5.000 medianas de amostras simuladas foram coletadas no array medians. Agora é hora de visualizar os resultados.
Visualização
Aqui estão as medianas de amostras aleatórias simuladas exibidas na tabela simulated_medians.
simulated_medians = Table().with_column('Sample Median', medians)
simulated_medians| Sample Median |
|---|
| 2 |
| 3 |
| 1 |
| 3 |
| 2 |
| 2.5 |
| 3 |
| 3 |
| 3 |
| 2 |
Também podemos visualizar os dados simulados usando um histograma. O histograma é chamado de histograma empírico da estatística. Ele exibe a distribuição empírica da estatística. Lembre-se de que empírico significa observado.
simulated_medians.hist(bins=np.arange(0.5, 5, 1))
Você pode ver que a mediana da amostra é muito provavelmente cerca de 2, que foi o valor da mediana da população. Como amostras de 1000 atrasos de voo tendem a se assemelhar à população de atrasos, não é surpreendente que as medianas dos atrasos dessas amostras estejam próximas à mediana do atraso na população.
Este é um exemplo de como uma estatística pode fornecer uma boa estimativa de um parâmetro.
O Poder da Simulação
Se pudéssemos gerar todas as possíveis amostras aleatórias de tamanho 1000, conheceríamos todos os valores possíveis da estatística (a mediana da amostra), bem como as probabilidades de todos esses valores. Poderíamos visualizar todos os valores e probabilidades no histograma de probabilidade da estatística.
Mas em muitas situações, incluindo esta, o número de todas as amostras possíveis é grande o suficiente para exceder a capacidade do computador, e cálculos puramente matemáticos das probabilidades podem ser dificilmente tratáveis.
É aqui que entram os histogramas empíricos.
Sabemos que, pela Lei dos Grandes Números, o histograma empírico da estatística provavelmente se assemelhará ao histograma de probabilidade da estatística, se o tamanho da amostra for grande e se você repetir o processo de amostragem aleatória várias vezes.
Isso significa que simular processos aleatórios repetidamente é uma maneira de aproximar distribuições de probabilidade sem calcular as probabilidades matematicamente ou gerar todas as possíveis amostras aleatórias. Assim, as simulações computacionais se tornam uma ferramenta poderosa na ciência de dados. Elas podem ajudar os cientistas de dados a entender as propriedades de quantidades aleatórias que seriam complicadas de analisar de outras maneiras.
| ← Capítulo 10.2 – Amostragem de uma População | Capítulo 10.4 – Amostragem Aleatória em Python → |