
Capítulo 13.4
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
%matplotlib inline
path_data = '../../../assets/data/'
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
import numpy as np
Usando Intervalos de Confiança
Um intervalo de confiança tem um único propósito – estimar um parâmetro desconhecido com base em dados de uma amostra aleatória. Na última seção, dissemos que o intervalo (36%, 42%) era um intervalo de confiança aproximado de 95% para a porcentagem de fumantes entre as mães da população Essa foi uma forma formal de dizer que, pela nossa estimativa, a porcentagem de fumantes entre as mães da população estava entre 36% e 42%, e que nosso processo de estimativa está correto em cerca de
95% dos casos.
É importante resistir ao impulso de usar intervalos de confiança para outros fins. Por exemplo, lembre-se que calculamos o intervalo (26,9 anos, 27,6 anos) como um intervalo de confiança aproximado de 95% para a idade média das mães na população. O uso indevido e assustadoramente comum do intervalo é concluir que cerca de 95% das mulheres tinham entre 26,9 e 27,6 anos de idade. Você não precisa saber muito sobre intervalos de confiança para ver que isso não pode estar certo – você não
estaria certo. Esperamos que 95% das mães tenham idades próximas de alguns meses. Na verdade, o histograma das idades amostradas mostra bastante variação.
births = Table.read_table(path_data + 'baby.csv')births.select('Maternal Age').hist()
Uma pequena percentagem das idades amostradas está no intervalo (26,9, 27,6), e esperado uma pequena percentagem semelhante na população. O intervalo apenas estima um número: a média de todas as idades da população.
No entanto, estimar um parâmetro por intervalos de confiança tem uma utilidade importante além de apenas nos dizer aproximadamente o tamanho do parâmetro.
Usando um Intervalo de Confiança para Testar Hipóteses
Nosso intervalo de confiança aproximado de 95% para a idade média na população vai de 26,9 anos a 27,6 anos. Suponha que alguém queira testar as seguintes hipóteses:
Hipótese nula: A idade média na população é de 30 anos.
Hipótese alternativa: A idade média na população não é de 30 anos.
Então, se você estivesse usando o limite de 5% para o p-valor, você rejeitaria a hipótese nula. Isso porque 30 não está no intervalo de confiança de 95% para a média populacional. No nível de significância de 5%, 30 não é um valor plausível para a média populacional.
Este uso dos intervalos de confiança é o resultado de uma dualidade entre intervalos de confiança e testes: se você está testando se a média populacional é um valor particular x, e usa o limite de 5% para o p-valor, então você rejeitará a hipótese nula se x não estiver no seu intervalo de confiança de 95% para a média.
Isso pode ser estabelecido pela teoria estatística. Na prática, basta verificar se o valor especificado na hipótese nula está no intervalo de confiança.
Se você estivesse usando o limite de 1% para o p-valor, teria que verificar se o valor especificado na hipótese nula está em um intervalo de confiança de 99% para a média populacional.
Aproximadamente, essas afirmações também são verdadeiras para proporções populacionais, desde que a amostra seja grande.
Embora agora tenhamos uma maneira de usar intervalos de confiança para testar um tipo específico de hipótese, você pode se perguntar sobre o valor de testar se a idade média em uma população é igual a 30. De fato, o valor não é claro. Mas existem algumas situações em que um teste desse tipo de hipótese é tanto natural quanto útil.
Comparando Pontuações de Linha de Base e Pós-Tratamento
Estudaremos isso no contexto de dados que são um subconjunto das informações coletadas em um ensaio controlado randomizado sobre tratamentos para a doença de Hodgkin. A doença de Hodgkin é um câncer que tipicamente afeta jovens. A doença é curável, mas o tratamento pode ser muito severo. O objetivo do ensaio era encontrar uma dosagem que curasse o câncer, mas minimizasse os efeitos adversos nos pacientes.
Esta tabela hodgkins contém dados sobre o efeito que o tratamento teve nos pulmões de 22 pacientes. As colunas são:
- Altura em cm
- Uma medida de radiação para a região do manto (pescoço, tórax, axilas)
- Uma medida de quimioterapia
- Uma pontuação da saúde dos pulmões na linha de base, ou seja, no início do tratamento; pontuações mais altas correspondem a pulmões mais saudáveis
- A mesma pontuação da saúde dos pulmões, 15 meses após o tratamento
hodgkins = Table.read_table(path_data + 'hodgkins.csv')hodgkins.show(3)| height | rad | chemo | base | month15 |
|---|---|---|---|---|
| 164 | 679 | 180 | 160.57 | 87.77 |
| 168 | 311 | 180 | 98.24 | 67.62 |
| 173 | 388 | 239 | 129.04 | 133.33 |
Compararemos as pontuações iniciais e de 15 meses. Como cada linha corresponde a um paciente, dizemos que a amostra de pontuações iniciais e a amostra de pontuações de 15 meses estão pareadas – não são apenas dois conjuntos de 22 valores cada, mas 22 pares de valores, um para cada paciente.
À primeira vista, você pode ver que as pontuações de 15 meses tendem a ser mais baixas do que as pontuações iniciais – os pulmões dos pacientes da amostra parecem estar piorando 15 meses após o tratamento. Isto é confirmado pelos valores em sua maioria positivos na coluna drop, o valor pelo qual a pontuação caiu da linha de base para 15 meses.
hodgkins = hodgkins.with_columns(
'drop', hodgkins.column('base') - hodgkins.column('month15')
)hodgkins| height | rad | chemo | base | month15 | drop |
|---|---|---|---|---|---|
| 164 | 679 | 180 | 160.57 | 87.77 | 72.8 |
| 168 | 311 | 180 | 98.24 | 67.62 | 30.62 |
| 173 | 388 | 239 | 129.04 | 133.33 | -4.29 |
| 157 | 370 | 168 | 85.41 | 81.28 | 4.13 |
| 160 | 468 | 151 | 67.94 | 79.26 | -11.32 |
| 170 | 341 | 96 | 150.51 | 80.97 | 69.54 |
| 163 | 453 | 134 | 129.88 | 69.24 | 60.64 |
| 175 | 529 | 264 | 87.45 | 56.48 | 30.97 |
| 185 | 392 | 240 | 149.84 | 106.99 | 42.85 |
| 178 | 479 | 216 | 92.24 | 73.43 | 18.81 |
hodgkins.select('drop').hist(bins=np.arange(-20, 81, 20))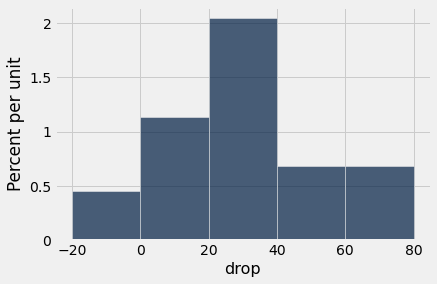
np.average(hodgkins.column('drop'))| Out[1]: | 28.615909090909096 |
No exemplo, a queda média é de cerca de 28,6. Mas isso poderia ser resultado de uma variação ao acaso? Os dados são de uma amostra aleatória. Poderia ser que em toda a população de pacientes, a queda média seja apenas 0?
Para responder a isso, podemos estabelecer duas hipóteses:
Hipótese nula: Na população, a queda média é 0.
Hipótese alternativa: Na população, a queda média não é 0.
Para testar essa hipótese com um limite de 1% para o p-valor, vamos construir um intervalo de confiança aproximado de 99% para a queda média na população.
def one_bootstrap_mean():
resample = hodgkins.sample()
return np.average(resample.column('drop'))# Gere 10.000 meios de bootstrap
num_repetitions = 10000
bstrap_means = make_array()
for i in np.arange(num_repetitions):
bstrap_means = np.append(bstrap_means, one_bootstrap_mean())# Obtenha os pontos finais do intervalo de confiança de 99%
left = percentile(0.5, bstrap_means)
right = percentile(99.5, bstrap_means)
make_array(left, right)| Out[2]: | array([17.46863636, 40.97681818]) |
resampled_means = Table().with_columns(
'Bootstrap Sample Mean', bstrap_means
)
resampled_means.hist()
plots.plot([left, right], [0, 0], color='yellow', lw=8);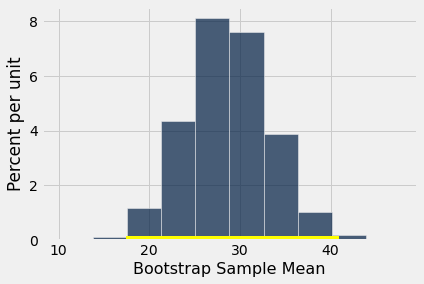
O intervalo de confiança de 99% para a queda média na população vai de cerca de 17 a cerca de 40. O intervalo não contém 0. Portanto, rejeitamos a hipótese nula.
Mas observe que fizemos mais do que simplesmente concluir que a queda média na população não é 0. Estimamos o quão grande é a queda média. Isso é um resultado mais útil do que apenas dizer: “Não é 0.”
Uma nota sobre a precisão: Nosso intervalo de confiança é bastante amplo, por dois motivos principais:
- O nível de confiança é alto (99%).
- O tamanho da amostra é relativamente pequeno em comparação com os exemplos anteriores.
No próximo capítulo, examinaremos como o tamanho da amostra afeta a precisão. Também examinaremos como as distribuições empíricas das médias amostrais frequentemente apresentam formato de sino, mesmo que as distribuições dos dados subjacentes não apresentem esse formato de forma alguma.
Nota final
A terminologia de um campo geralmente vem dos principais pesquisadores desse campo. Brad Efron, que propôs pela primeira vez a técnica bootstrap, usou um termo que tem origens americanas. Para não ficar atrás, estatísticos chineses propuseram seu próprio método.
| ← Capítulo 13.3 – Intervalos de Confiança | Capítulo 14 – Por que a Média é Importante → |