
Capítulo 7.2
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
import numpy as np
path_data = '../../../assets/data/'
%matplotlib inline
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')Visualizando Distribuições Numéricas
Muitas das variáveis que os cientistas de dados estudam são quantitativas ou numéricas. Seus valores são números nos quais você pode realizar operações aritméticas. Exemplos que vimos incluem o número de períodos em capítulos de um livro, a quantidade de dinheiro feita por filmes e a idade das pessoas nos Estados Unidos.
Os valores de uma variável categórica podem receber códigos numéricos, mas isso não torna a variável quantitativa. No exemplo em que estudamos os dados do Censo divididos por faixa etária, a variável categórica SEX tinha os códigos numéricos 1 para ‘Masculino’, 2 para ‘Feminino’ e 0 para o agregado de ambos os grupos 1 e 2. Embora 0, 1 e 2 sejam números, neste contexto não faz sentido subtrair 1 de 2, ou tirar a média de 0, 1 e 2, ou realizar outras operações aritméticas nos três valores. SEXO é uma variável categórica, mesmo que os valores tenham recebido um código numérico.
Para o nosso exemplo principal, vamos voltar a um conjunto de dados que estudamos quando estávamos visualizando dados categóricos. É a tabela top, que consiste em dados dos filmes com maior arrecadação de todos os tempos nos Estados Unidos (até 2017). Para conveniência, aqui está a descrição da tabela novamente.
A primeira coluna contém o título do filme. A segunda coluna contém o nome do estúdio que produziu o filme. A terceira contém a arrecadação doméstica de bilheteria em dólares, e a quarta contém o valor bruto que teria sido ganho com a venda de ingressos a preços de 2016. A quinta contém o ano de lançamento do filme.
Há 200 filmes na lista. Aqui estão os dez melhores de acordo com a arrecadação bruta não ajustada na coluna Gross.
top = Table.read_table(path_data + 'top_movies_2017.csv')
# Faça com que os números nas colunas Bruto e Bruto (Ajustado) pareçam mais bonitos:
top.set_format([2, 3], NumberFormatter)| Title | Studio | Gross | Gross (Adjusted) | Year |
|---|---|---|---|---|
| Gone with the Wind | MGM | 198,676,459 | 1,796,176,700 | 1939 |
| Star Wars | Fox | 460,998,007 | 1,583,483,200 | 1977 |
| The Sound of Music | Fox | 158,671,368 | 1,266,072,700 | 1965 |
| E.T.: The Extra-Terrestrial | Universal | 435,110,554 | 1,261,085,000 | 1982 |
| Titanic | Paramount | 658,672,302 | 1,204,368,000 | 1997 |
| The Ten Commandments | Paramount | 65,500,000 | 1,164,590,000 | 1956 |
| Jaws | Universal | 260,000,000 | 1,138,620,700 | 1975 |
| Doctor Zhivago | MGM | 111,721,910 | 1,103,564,200 | 1965 |
| The Exorcist | Warner Brothers | 232,906,145 | 983,226,600 | 1973 |
| Snow White and the Seven Dwarves | Disney | 184,925,486 | 969,010,000 | 1937 |
| … (190 rows omitted) | ||||
Nesta seção, iremos desenhar gráficos da distribuição da variável numérica na coluna Gross (Adjusted). Para simplificar, vamos criar uma tabela menor que contenha as informações que precisamos. E como números de três dígitos são mais fáceis de trabalhar do que números de nove dígitos, vamos medir as receitas de Adjusted Gross em milhões de dólares. Observe como np.round é usado para manter apenas duas casas decimais em cada entrada da coluna.
millions = top.select(0).with_columns('Adjusted Gross',np.round(top.column(3)/1e6, 2))
millions| Title | Adjusted Gross |
|---|---|
| Gone with the Wind | 1796.18 |
| Star Wars | 1583.48 |
| The Sound of Music | 1266.07 |
| E.T.: The Extra-Terrestrial | 1261.08 |
| Titanic | 1204.37 |
| The Ten Commandments | 1164.59 |
| Jaws | 1138.62 |
| Doctor Zhivago | 1103.56 |
| The Exorcist | 983.23 |
| Snow White and the Seven Dwarves | 969.01 |
| … (190 rows omitted) | |
Agrupando os Dados
Observe os valores da variável quantitativa Adjusted Gross. Provavelmente haverá apenas um filme em cada valor individual, já que os valores estão sendo medidos de forma bastante refinada. É mais interessante agrupar os valores em intervalos, conhecidos como bins, e ver quantos filmes há em cada bin. Esse processo é chamado de agrupamento.
As contagens de indivíduos (ou seja, linhas) nos bins podem ser calculadas usando o método bin, análogo ao método group usado no caso de dados categóricos. O método bin recebe como argumento um rótulo de coluna ou índice e um argumento opcional no qual você pode especificar os bins desejados.
O resultado é uma tabela de duas colunas que contém o número de linhas em cada bin. A primeira coluna lista os pontos de extremidade esquerdos dos bins (mas veja a observação sobre o último bin, abaixo).
Vamos experimentar o método e examinar os detalhes da saída. Para escolher alguns bins, começaremos olhando para os valores mais baixos e mais altos de Adjusted Gross.
adj_gross = millions.column('Adjusted Gross')
min(adj_gross), max(adj_gross)| Out[2]: | (338.41, 1796.18) |
Vamos tentar caixas de largura 100, começando em 300 e indo até 2.000. Você pode fazer outras escolhas. É comum começar com algo que parece razoável e depois ajustar com base nos resultados.
bin_counts = millions.bin('Adjusted Gross', bins=np.arange(300,2001,100))
bin_counts.show()| bin | Adjusted Gross count |
|---|---|
| 300 | 68 |
| 400 | 60 |
| 500 | 32 |
| 600 | 15 |
| 700 | 7 |
| 800 | 7 |
| 900 | 3 |
| 1000 | 0 |
| 1100 | 3 |
| 1200 | 3 |
| 1300 | 0 |
| 1400 | 0 |
| 1500 | 1 |
| 1600 | 0 |
| 1700 | 1 |
| 1800 | 0 |
| 1900 | 0 |
| 2000 | 0 |
Vamos examinar a Coluna 0, a coluna bin. Esta coluna especifica o ponto de extremidade esquerdo de cada bin, exceto na última linha, conforme explicado abaixo.
Como os bins dividem a reta numérica em intervalos, eles são contíguos. Portanto, devemos ter cuidado com os valores nos pontos de extremidade. Pela convenção usual do Python, cada bin, exceto o último, inclui seu ponto de extremidade esquerdo, mas não seu ponto de extremidade direito.
Para destacar este ponto, usaremos a notação [a, b) para nos referirmos ao bin que contém todos os valores que são maiores ou iguais a a e estritamente menores que b.
Para entender a primeira linha da tabela, você precisa olhar também para a segunda linha. Essas duas linhas nos dizem que houve 68 filmes no bin [300, 400). Ou seja, 68 filmes tiveram receitas brutas ajustadas de pelo menos 300 milhões de dólares, mas menos de 400 milhões de dólares.
Em geral, cada elemento na coluna Adjusted Gross count conta todos os valores de Adjusted Gross que são maiores ou iguais ao valor em bin, mas menores que o próximo valor em bin.
O último bin: Observe o valor bin 2000 na última linha. Esse não é o ponto de extremidade esquerdo de nenhum bin. Em vez disso, é o ponto de extremidade direito do último bin. Este bin é diferente de todos os outros porque tem a forma [a, b]. Ele inclui os dados em ambos os pontos de extremidade. Em nosso exemplo, isso não importa porque nenhum filme ganhou 2 bilhões de dólares (ou seja, 2000 milhões). Mas este aspecto do agrupamento é importante ter em mente no caso de você querer que os bins terminem exatamente no valor máximo dos dados. Todas as contagens para este último bin aparecem na penúltima linha, e a contagem para a última linha é sempre zero.
Existem outras maneiras de usar o método bin. Se você não especificar nenhum bin, o padrão é produzir 10 bins igualmente largos entre os valores mínimo e máximo dos dados. Isso geralmente é útil para obter uma ideia rápida da distribuição, mas os pontos de extremidade dos bins tendem a ser alarmantes.
millions.bin('Adjusted Gross').show()| bin | Adjusted Gross count |
|---|---|
| 338.41 | 115 |
| 484.187 | 50 |
| 629.964 | 14 |
| 775.741 | 10 |
| 921.518 | 3 |
| 1067.3 | 4 |
| 1213.07 | 2 |
| 1358.85 | 0 |
| 1504.63 | 1 |
| 1650.4 | 1 |
| 1796.18 | 0 |
Você pode especificar vários compartimentos igualmente largos. Por exemplo, a opção bins=4 leva a 4 compartimentos igualmente espaçados.
millions.bin('Adjusted Gross', bins=4)| bin | Adjusted Gross count |
|---|---|
| 338.41 | 177 |
| 702.852 | 15 |
| 1067.3 | 6 |
| 1431.74 | 2 |
| 1796.18 | 0 |
Mas com dados quantitativos, as caixas não precisam ser igualmente largas. Veremos um exemplo de caixas desiguais mais tarde.
Histograma
Um histograma é uma visualização da distribuição de uma variável quantitativa. Ele se parece muito com um gráfico de barras, mas há algumas diferenças importantes que examinaremos nesta seção. Primeiro, vamos apenas desenhar um histograma dos recibos ajustados.
O método hist gera um histograma dos valores em uma coluna. O argumento opcional unit é usado nos rótulos dos dois eixos. O histograma abaixo mostra a distribuição dos valores dos recibos ajustados, em milhões de dólares de 2016. Não especificamos os bins, então o hist cria 10 bins igualmente largos entre os valores mínimo e máximo dos dados.
millions.hist('Adjusted Gross', unit="Million Dollars")
Esta figura tem dois eixos numéricos. Primeiro daremos uma olhada rápida no eixo horizontal e depois examinaremos cuidadosamente o eixo vertical. Por enquanto, apenas observe que o eixo vertical não representa porcentagens.
O Eixo Horizontal
Embora neste conjunto de dados nenhum filme tenha obtido um valor exatamente na borda entre dois bins, hist precisa lidar com situações em que pode ter havido valores nas bordas. Portanto, hist usa a mesma convenção de pontos finais que o método bin. Bins incluem os dados em seu ponto final esquerdo, mas não os dados em seu ponto final direito, exceto para o bin mais à direita, que inclui ambos os pontos finais.
Podemos ver que existem 10 bins (algumas barras são tão baixas que é difícil de vê-las), e que todos têm a mesma largura. Também podemos ver que nenhum dos filmes arrecadou menos de 300 milhões de dólares; isso porque estamos considerando apenas os filmes de maior bilheteria.
É um pouco mais difícil ver exatamente onde estão localizadas as extremidades dos bins. Portanto, é difícil julgar exatamente onde uma barra termina e a próxima começa.
O argumento opcional bins pode ser usado com hist para especificar os pontos finais dos bins exatamente como com o método bin. Vamos começar definindo os números em bins como 300, 400, 500, e assim por diante, terminando com 2000.
millions.hist('Adjusted Gross', bins=np.arange(300,2001,100), unit="Million Dollars")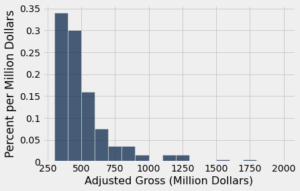
O eixo horizontal desta figura é mais fácil de ler. Por exemplo, você pode ver exatamente onde está 600, mesmo que não esteja rotulado.
Um número muito pequeno de filmes arrecadou um bilhão de dólares (1000 milhões) ou mais. Isso resulta na figura sendo inclinada para a direita, ou, de forma menos formal, tendo uma cauda longa à direita. Distribuições de variáveis como renda ou aluguel em grandes populações também frequentemente têm esse tipo de forma.
O Princípio da Área
Ambos os eixos de um histograma são numéricos, então você pode fazer aritmética em ambos. Por exemplo, você pode multiplicar os valores em um ou ambos os eixos por um fator. Para ver como isso poderia afetar a percepção visual, vamos dar um passo para trás dos histogramas e olhar para um gráfico fornecido para este propósito pelo site Flowing Data. É uma comparação entre os tamanhos de bateria de dois modelos de iPad.

A bateria maior deve ser 70% maior do que a menor. Então, deveria ser maior, mas não exatamente duas vezes maior. No entanto, a bateria maior na imagem parece quase quatro vezes maior que a menor.
O motivo desse problema é que o olho percebe a área como a medida do tamanho, não apenas a altura ou apenas a largura. Na imagem, ambas as dimensões foram aumentadas em 70%, levando a um efeito multiplicativo na área.
O princípio da área da visualização diz que quando representamos uma magnitude por uma figura que tem duas dimensões, como um retângulo, então a área da figura deve representar a magnitude.
O Histograma: Princípios Gerais e Cálculo
Os histogramas seguem o princípio da área e têm duas propriedades definidoras:
- Os bins são desenhados em escala e são contíguos (embora alguns possam estar vazios), porque os valores no eixo horizontal são numéricos e, portanto, têm posições fixas na reta numérica.
- A área de cada barra é proporcional ao número de entradas no bin.
A Propriedade 2 é a chave para desenhar um histograma, e é geralmente alcançada da seguinte forma:
Como as áreas representam percentuais, as alturas representam algo diferente de percentuais. O cálculo numérico das alturas apenas usa o fato de que a barra é um retângulo:
e então
As unidades de altura são “porcentagem por unidade no eixo horizontal.” A altura é a porcentagem no bin em relação à largura do bin. Portanto, é chamada densidade ou concentração.
Quando desenhado usando este método, o histograma é dito ser desenhado na escala de densidade. Nesta escala:
- A área de cada barra é igual ao percentual de valores de dados que estão no bin correspondente.
- A área total de todas as barras no histograma é 100%. Em termos de proporções, podemos dizer que as áreas de todas as barras em um histograma “somam 1”.
O Eixo Vertical: Escala de Densidade
Como acabamos de ver, a altura de cada barra é o percentual de elementos que caem no bin correspondente, em relação à largura do bin. Agora veremos como o hist calculou as alturas de todas as barras do histograma acima.
Aqui está o histograma novamente para facilitar a referência.
millions.hist('Adjusted Gross', bins=np.arange(300,2001,100), unit="Million Dollars")
Lembre-se de que a tabela bin_counts possui as contagens em todos os compartimentos do histograma, especificados por bins=np.arange(300, 2000, 100). Lembre-se também de que existem 200 filmes no total.
bin_counts.show(3)| bin | Adjusted Gross count |
|---|---|
| 300 | 68 |
| 400 | 60 |
| 500 | 32 |
| … (15 rows omitted) | |
O intervalo [300, 400) contém 68 filmes. Isso representa 34% de todos os filmes:
A largura do intervalo [300, 400) é 400 − 300 = 100. Portanto,
Unidades: A altura da barra é 34% dividida por 100 milhões de dólares, então a altura é 0.34% por milhão de dólares.
A altura da barra não representa a porcentagem de entradas no intervalo. Ela representa a porcentagem de entradas no intervalo em relação à quantidade de espaço no intervalo. Por isso, a altura mede a lotação ou densidade. O eixo vertical é dito estar na escala de densidade.
Por que não simplesmente plotar as contagens?
A principal razão para plotar a densidade no eixo vertical em vez de contagens ou porcentagens é poder comparar histogramas e aproximá-los com curvas suaves onde as proporções são representadas por áreas sob a curva.
Por exemplo, mais tarde no curso você verá histogramas que são aproximadamente em forma de sino. A figura abaixo mostra tal forma. A área sombreada em dourado acontece de ser 95% da área total sob a curva. Note que isso é bastante crível com base nas áreas que você vê na figura, mesmo que não haja números nos eixos. É por isso que desenhamos histogramas para que as áreas representem porcentagens.

Desenhar histogramas na escala de densidade também nos permite comparar histogramas que são baseados em conjuntos de dados de tamanhos diferentes ou têm escolhas diferentes de bins. Nesses casos, nem contagens de bins nem porcentagens podem ser diretamente comparáveis. Mas se ambos os histogramas forem desenhados na escala de densidade, então áreas e densidades são comparáveis.
Se um histograma tiver bins desiguais, então plotar na escala de densidade é um requisito para interpretabilidade. Para algumas variáveis, bins desiguais podem ser naturais. Por exemplo, no sistema educacional dos EUA, a escola primária consiste nos anos 1-5, a escola secundária é nos anos 6-8, o ensino médio é nos anos 9-12, e um diploma de bacharel requer mais quatro anos. Dados sobre anos de educação podem ser agrupados usando esses intervalos. De fato, não importa qual seja a variável, os bins não precisam ser iguais. É bastante comum ter um bin muito amplo em direção ao final esquerdo ou direito dos dados, onde não há muitos valores.
Vamos plotar um histograma de receitas brutas ajustadas usando bins desiguais e depois ver o que acontece se plotarmos contagens em vez disso.
uneven = make_array(300, 350, 400, 500, 1800)
millions.hist('Adjusted Gross', bins=uneven, unit="Million Dollars")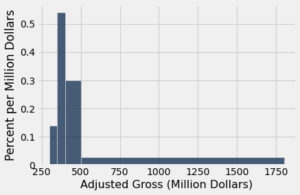
Observe que a barra [400, 500) tem a mesma altura (0,3% por milhão de dólares) que nos histogramas acima.
As áreas das outras barras representam as porcentagens nas caixas, como sempre. O método bin nos permite ver as contagens em cada caixa.
millions.bin('Adjusted Gross', bins=uneven)| bin | Adjusted Gross count |
|---|---|
| 300 | 14 |
| 350 | 54 |
| 400 | 60 |
| 500 | 72 |
| 1800 | 0 |
O bin [300, 350) possui apenas 14 filmes, enquanto o bin [500, 1800] possui 72 filmes. Mas a barra sobre o bin [500, 1800] é muito mais curta do que a barra sobre [300, 350). O bin [500, 1800] é tão amplo que seus 72 filmes são muito menos densamente agrupados do que os 14 filmes no estreito bin [300, 350). Em outras palavras, há menos densidade sobre o intervalo [500, 1800].
Se em vez disso você apenas plotar as contagens usando a opção normed=False como mostrado abaixo, a figura parece completamente diferente e distorce os dados.
millions.hist('Adjusted Gross', bins=uneven, normed=False)
Mesmo que hist tenha sido usado, a figura acima NÃO É UM HISTOGRAMA. Exagera de forma enganosa os filmes que arrecadaram pelo menos 500 milhões de dólares. A altura de cada barra é simplesmente plotada no número de filmes no bin, sem levar em consideração a diferença nas larguras dos bins. Nesta figura baseada em contagem, a forma da distribuição de filmes é completamente perdida.
Tops Planos e o Nível de Detalhe
Mesmo que a escala de densidade represente corretamente porcentagens usando área, algum detalhe é perdido ao agrupar valores em bins.
Dê mais uma olhada no bin [400, 500) na figura abaixo. O topo plano da barra, no nível de 0.3% por milhão de dólares, esconde o fato de que os filmes estão um pouco irregularmente distribuídos por esse bin.
millions.hist('Adjusted Gross', bins=uneven, unit="Million Dollars")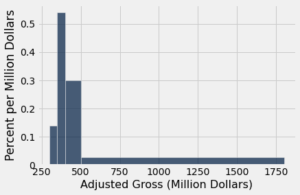
Para ver isso, vamos dividir a caixa [400, 500) em 10 caixas mais estreitas, cada uma com largura de 10 milhões de dólares.
some_tiny_bins = make_array(
300, 350, 400, 410, 420, 430, 440, 450, 460, 470, 480, 490, 500, 1800)
millions.hist('Adjusted Gross', bins=some_tiny_bins, unit='Million Dollars')
Algumas das barras estreitas são mais altas do que 0,3 e outras são mais baixas. Ao colocar um topo plano no nível 0,3 em todo o bin, estamos decidindo ignorar os detalhes mais finos e estamos usando o nível plano como uma aproximação grosseira. Muitas vezes, embora nem sempre, isso é suficiente para entender a forma geral da distribuição.
A altura como uma aproximação grosseira. Essa observação nos dá uma maneira diferente de pensar sobre a altura. Olhe novamente para o bin [400, 500) nos histogramas anteriores. Como vimos, o bin tem 100 milhões de dólares de largura e contém 30% dos dados. Portanto, a altura da barra correspondente é de 0,3% por milhão de dólares.
Agora, pense no bin como consistindo em 100 bins estreitos, cada um com 1 milhão de dólares de largura. A altura da barra de “0,3% por milhão de dólares” significa que, como uma aproximação grosseira, 0,3% dos filmes estão em cada um desses 100 bins estreitos com largura de 1 milhão de dólares.
Temos todo o conjunto de dados que está sendo usado para desenhar os histogramas. Portanto, podemos desenhar os histogramas com o nível de detalhe que os dados e nossa paciência permitirem. Bins menores levarão a uma imagem mais detalhada. No entanto, se você estiver olhando para um histograma em um livro ou em um site e não tiver acesso ao conjunto de dados subjacente, torna-se importante ter uma compreensão clara da “aproximação grosseira” criada pelos topos planos.
Computando Todas as Alturas
Nós sabemos como encontrar a altura de cada barra do histograma. Vamos usar isso para desenvolver um código que calcula todas as alturas de uma vez.
Usaremos o histograma abaixo como nosso exemplo. Os bins são especificados no array uneven.
millions.hist('Adjusted Gross', bins=uneven, unit="Million Dollars")
Começaremos colocando as contagens nas caixas.
histogram_elements = millions.bin('Adjusted Gross', bins=uneven).relabeled(1, 'count')
histogram_elements| bin | count |
|---|---|
| 300 | 14 |
| 350 | 54 |
| 400 | 60 |
| 500 | 72 |
| 1800 | 0 |
Agora podemos adicionar uma coluna contendo a porcentagem em cada compartimento.
total_count = sum(histogram_elements.column('count'))
percents = np.round(100*histogram_elements.column('count')/total_count, 2)
histogram_elements = histogram_elements.with_columns('percent', percents)
histogram_elements| bin | count | percent |
|---|---|---|
| 300 | 14 | 7.0 |
| 350 | 54 | 27.0 |
| 400 | 60 | 30.0 |
| 500 | 72 | 36.0 |
| 1800 | 0 | 0.0 |
A coluna 0 contém os extremos esquerdos de todos os bins, exceto seu último elemento, que é o extremo direito do último bin. Portanto, podemos usar np.diff para encontrar as larguras de todos os bins. Em seguida, adicionaremos as larguras à tabela histogram_elements, removendo primeiro a última linha.
bin_widths = np.diff(histogram_elements.column('bin'))
num_bins = histogram_elements.num_rows - 1 # the number of bins
histogram_elements = histogram_elements.take(
np.arange(num_bins)).with_columns(
'width', bin_widths
)
histogram_elements| bin | count | percent | width |
|---|---|---|---|
| 300 | 14 | 7.0 | 50 |
| 350 | 54 | 27.0 | 50 |
| 400 | 60 | 30.0 | 100 |
| 500 | 72 | 36.0 | 1300 |
Finalmente, podemos adicionar uma coluna de alturas.
heights = np.round(
histogram_elements.column('percent')/histogram_elements.column('width'),2)
histogram_elements = histogram_elements.with_columns('height', heights)
histogram_elements| bin | count | percent | width | height |
|---|---|---|---|---|
| 300 | 14 | 7.0 | 50 | 0.14 |
| 350 | 54 | 27.0 | 50 | 0.54 |
| 400 | 60 | 30.0 | 100 | 0.3 |
| 500 | 72 | 36.0 | 1300 | 0.03 |
Aqui está o histograma novamente por conveniência. Compare-o com a tabela acima para confirmar se o cálculo das alturas parece bom.
millions.hist('Adjusted Gross', bins=uneven)
Diferenças entre Gráficos de Barras e Histogramas
- Gráficos de barras exibem uma quantidade numérica por categoria. Eles são frequentemente usados para exibir as distribuições de variáveis categóricas. Histogramas exibem as distribuições de variáveis quantitativas.
- Todas as barras em um gráfico de barras têm a mesma largura, e há uma quantidade igual de espaço entre barras consecutivas. As barras podem estar em qualquer ordem porque a distribuição é categórica. As barras de um histograma são contíguas; os bins são desenhados em escala na linha numérica.
- Os comprimentos (ou alturas, se as barras forem desenhadas verticalmente) das barras em um gráfico de barras são proporcionais à contagem em cada categoria. As alturas das barras em um histograma medem densidades; as áreas das barras em um histograma são proporcionais às contagens nos bins.
| ← Capítulo 7.1 – Visualizando Distribuições Categóricas | Capítulo 7.3 – Gráficos Sobrepostos → |