
Capítulo 7.1
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
Visualizando Distribuições Categóricas
Os dados podem assumir muitas formas que não são numéricas. Os dados podem ser pedaços de música, ou lugares em um mapa. Eles também podem ser categorias nas quais você pode colocar indivíduos. Aqui estão alguns exemplos de variáveis categóricas.
- Os indivíduos são cartões de sorvete, e a variável é o sabor no cartão.
- Os indivíduos são jogadores profissionais de basquete, e a variável é o time do jogador.
- Os indivíduos são anos, e a variável é o gênero do filme de maior bilheteria do ano.
- Os indivíduos são respondentes de pesquisa, e a variável é a resposta que escolhem entre “Nada satisfeito,” “Algo satisfeito,” e “Muito satisfeito.”
A tabela icecream contém dados de 30 caixas de sorvetes.
icecream = Table().with_columns(
'Flavor', make_array('Chocolate', 'Strawberry', 'Vanilla'),
'Number of Cartons', make_array(16, 5, 9)
)
icecream| Flavor | Number of Cartons |
|---|---|
| Chocolate | 16 |
| Strawberry | 5 |
| Vanilla | 9 |
Os valores da variável categórica “sabor” são chocolate, morango e baunilha.
Cada um dos cartões tinha exatamente um dos três sabores. Em uma distribuição, cada indivíduo pertence exatamente a uma categoria e, portanto, tem exatamente um valor. Assim, temos uma distribuição de sabores.
A tabela mostra o número de cartões de cada sabor. Chamamos isso de tabela de distribuição. Uma tabela de distribuição mostra todos os valores da variável junto com a frequência de cada um.
Gráfico de Barras
O gráfico de barras é uma maneira familiar de visualizar distribuições categóricas. Ele exibe uma barra para cada categoria. As barras são igualmente espaçadas e igualmente largas. O comprimento de cada barra é proporcional à frequência da categoria correspondente.
Desenharemos gráficos de barras com barras horizontais porque é mais fácil rotular as barras dessa maneira. O método da Tabela é, portanto, chamado de barh. Ele recebe dois argumentos: o primeiro é o rótulo da coluna das categorias, e o segundo é o rótulo da coluna das frequências.
icecream.barh('Flavor', 'Number of Cartons')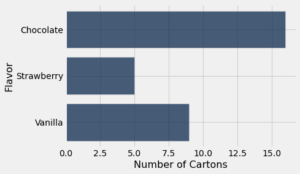
Se a tabela consistir apenas de uma coluna de categorias e uma coluna de frequências, como em icecream, a chamada do método é ainda mais simples. Você só precisa especificar a coluna que contém as categorias, e barh usará os valores na outra coluna como frequências.
icecream.barh('Flavor')
Aspectos de Design de Gráficos de Barras
Além das diferenças puramente visuais, há uma distinção fundamental importante entre gráficos de barras e os dois gráficos que vimos nas seções anteriores. Aqueles foram o gráfico de dispersão e o gráfico de linha, ambos exibem duas variáveis quantitativas – as variáveis em ambos os eixos são quantitativas. Em contraste, o gráfico de barras tem categorias em um eixo e quantidades numéricas no outro.
Isso tem consequências para o gráfico. Primeiro, a largura de cada barra e o espaço entre barras consecutivas dependem inteiramente da pessoa que está produzindo o gráfico, ou do programa sendo usado para produzi-lo. O Python fez essas escolhas por nós. Se você fosse desenhar o gráfico de barras à mão, poderia fazer escolhas completamente diferentes e ainda ter um gráfico de barras perfeitamente correto, desde que desenhasse todas as barras com a mesma
largura e mantivesse todos os espaços iguais.
O mais importante é que as barras podem ser desenhadas em qualquer ordem. As categorias “chocolate,” “baunilha” e “morango” não têm uma ordem de classificação universal, ao contrário, por exemplo, dos números 5, 7 e 10.
Isso significa que podemos desenhar um gráfico de barras que seja mais fácil de interpretar, rearranjando as barras em ordem decrescente. Para fazer isso, primeiro rearranjamos as linhas de icecream em ordem decrescente de Number of Cartons, e então desenhamos o gráfico de barras.
icecream.sort('Number of Cartons', descending=True).barh('Flavor')
Este gráfico de barras contém exatamente as mesmas informações que os anteriores, mas é um pouco mais fácil de ler. Embora não haja uma grande melhoria na leitura de um gráfico com apenas três barras, pode ser bastante significativo quando o número de categorias é grande.
Agrupando Dados Categóricos
Para construir a tabela icecream, alguém teve que olhar para todos os 30 potes de sorvete e contar o número de cada sabor. Mas se nossa tabela ainda não incluir frequências, precisamos calcular as frequências antes de podermos desenhar um gráfico de barras. Aqui está um exemplo em que isso é necessário.
A tabela top consiste nos filmes com maior bilheteria de todos os tempos dos Estados Unidos, até 2017. A primeira coluna contém o título do filme; Star Wars: O Despertar da Força tem a maior posição, com uma arrecadação de bilheteria de mais de 900 milhões de dólares nos Estados Unidos. A segunda coluna contém o nome do estúdio que produziu o filme. A terceira contém a arrecadação da bilheteria doméstica em dólares, e a quarta contém o montante bruto que teria sido obtido com a venda de ingressos a preços de 2016. A quinta contém o ano em que o filme foi lançado.
Há 200 filmes na lista. Aqui estão os dez primeiros de acordo com as arrecadações brutas não ajustadas.
top = Table.read_table(path_data + 'top_movies_2017.csv')
top| Title | Studio | Gross | Gross (Adjusted) | Year |
|---|---|---|---|---|
| Gone with the Wind | MGM | 198676459 | 1796176700 | 1939 |
| Star Wars | Fox | 460998007 | 1583483200 | 1977 |
| The Sound of Music | Fox | 158671368 | 1266072700 | 1965 |
| E.T.: The Extra-Terrestrial | Universal | 435110554 | 1261085000 | 1982 |
| Titanic | Paramount | 658672302 | 1204368000 | 1997 |
| The Ten Commandments | Paramount | 65500000 | 1164590000 | 1956 |
| Jaws | Universal | 260000000 | 1138620700 | 1975 |
| Doctor Zhivago | MGM | 111721910 | 1103564200 | 1965 |
| The Exorcist | Warner Brothers | 232906145 | 983226600 | 1973 |
| Snow White and the Seven Dwarves | Disney | 184925486 | 969010000 | 1937 |
| … (190 rows omitted) | ||||
Os estúdios MGM, Fox, Universal e Paramount aparecem mais de uma vez no top dez. Quais estúdios aparecerão com mais frequência se olharmos entre todas as 200 linhas?
Para descobrir isso, primeiro observe que tudo o que precisamos é de uma tabela com os filmes e os estúdios; as outras informações são desnecessárias.
movies_and_studios = top.select('Title', 'Studio')O método group da Tabela nos permite contar com que frequência cada estúdio aparece na tabela, chamando cada estúdio de uma categoria e coletando todas as linhas em cada uma dessas novas categorias.
O método group recebe como argumento o rótulo da coluna que contém as categorias. Ele retorna uma tabela de contagens de linhas em cada categoria.
Portanto, group cria uma tabela de distribuição que mostra como os indivíduos (filmes) estão distribuídos entre as categorias (estúdios).
O método group lista as categorias em ordem ascendente. Como nossas categorias são nomes de estúdios e, portanto, representadas como strings, a ordem ascendente significa ordem alfabética.
A coluna de contagens é sempre chamada count, mas você pode mudar isso se quiser usando relabeled.
studio_distribution = movies_and_studios.group('Studio')
studio_distribution| Studio | count |
|---|---|
| AVCO | 1 |
| Buena Vista | 35 |
| Columbia | 9 |
| Disney | 11 |
| Dreamworks | 3 |
| Fox | 24 |
| IFC | 1 |
| Lionsgate | 3 |
| MGM | 7 |
| Metro | 1 |
| … (13 rows omitted) | |
A tabela mostra que existem 23 estúdios diferentes e dá a contagem de filmes lançados por cada um. O total da contagem é 200, o total de filmes.
sum(studio_distribution.column('count'))| Out[1]: | 200 |
Agora podemos usar esta tabela, juntamente com as habilidades gráficas adquiridas acima, para desenhar um gráfico de barras que mostra quais estúdios são mais frequentes entre os 200 filmes de maior bilheteria.
studio_distribution.sort('count', descending=True).barh('Studio')
Buena Vista e Warner Brothers são os estúdios mais comuns entre os 200 melhores filmes. A Warner Brothers produz os filmes de Harry Potter e a Buena Vista produz Star Wars.
Rumo a Variáveis Quantitativas
Embora os anos sejam numéricos, poderíamos tratar o ano de lançamento como uma variável categórica e plotar sua distribuição. Ou seja, para cada ano, poderíamos encontrar quantos filmes foram lançados naquele ano e, em seguida, desenhar o gráfico de barras dessa distribuição.
Vamos fazer isso e apenas olhar para os 10 primeiros anos na distribuição.
movies_and_years = top.select('Title', 'Year')
movies_and_years.group('Year').take(np.arange(10)).barh('Year')
Os anos aparecem em ordem crescente porque group classifica as categorias de menor para maior. Isso é importante aqui porque os anos têm uma ordem cronológica que precisa ser mantida. Mas há algo inquietante sobre este gráfico de barras. As barras em 1921 e 1937 estão tão distantes umas das outras quanto as barras em 1937 e 1939. O gráfico de barras não mostra que nenhum dos 200 filmes foi lançado nos anos de 1922 a 1936, nem em 1938. Essas inconsistências e omissões tornam a distribuição nos primeiros anos difícil de entender com base nesta visualização.
A distribuição de uma variável categórica pode ser exibida usando um gráfico de barras. Mas se a variável não for categórica, mas quantitativa, então as relações numéricas entre seus valores devem ser levadas em conta ao criarmos visualizações. Esse é o tema da próxima seção.
| ← Capítulo 7 – Visualização | Capítulo 7.2 – Visualizando Distribuições Numéricas → |