
Capítulo 14.4
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
%matplotlib inline
path_data = '../../../assets/data/'
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
import math
import numpy as np
from scipy import stats
colors = Table.read_table(path_data + 'roulette_wheel.csv').column('Color')
pockets = make_array('0','00')
for i in np.arange(1, 37):
pockets = np.append(pockets, str(i))
wheel = Table().with_columns(
'Pocket', pockets,
'Color', colors
)
O Teorema Central do Limite
Muito poucos dos histogramas de dados que vimos neste curso têm forma de sino. Quando encontramos uma distribuição em forma de sino, ela quase invariavelmente tem sido um histograma empírico de uma estatística baseada em uma amostra aleatória.
Os exemplos abaixo mostram duas situações muito diferentes nas quais uma forma aproximada de sino aparece em tais histogramas.
Ganho Líquido na Roleta
Em uma seção anterior, a forma de sino apareceu como a forma aproximada do valor total de dinheiro que ganharíamos se fizéssemos a mesma aposta repetidamente em diferentes giros de uma roleta.
wheel| Color | |
|---|---|
| 0 | green |
| 00 | green |
| 1 | red |
| 2 | black |
| 3 | red |
| 4 | black |
| 5 | red |
| 6 | black |
| 7 | red |
| 8 | black |
Lembre-se de que a aposta no vermelho paga o mesmo valor, 1 para 1. Definimos a função red_winnings que retorna os ganhos líquidos em uma aposta de $1 no vermelho. Especificamente, a função usa uma cor como argumento e retorna 1 se a cor é vermelha. Para todas as outras cores retorna -1.
def red_winnings(color):
if color == 'red':
return 1
else:
return -1
red = wheel.with_column(
'Winnings: Red', wheel.apply(red_winnings, 'Color')
)
red| Color | Winnings: Red | |
|---|---|---|
| 0 | green | -1 |
| 00 | green | -1 |
| 1 | red | 1 |
| 2 | black | -1 |
| 3 | red | 1 |
| 4 | black | -1 |
| 5 | red | 1 |
| 6 | black | -1 |
| 7 | red | 1 |
| 8 | black | -1 |
Seu ganho líquido em uma aposta é um sorteio aleatório da coluna Winnings: Red. Há uma chance de 18/38 de ganhar 1 e uma chance de 20/38 de ganhar -1. Esta distribuição de probabilidade é mostrada no histograma abaixo.
red.select('Winnings: Red').hist(bins=np.arange(-1.5, 1.6, 1))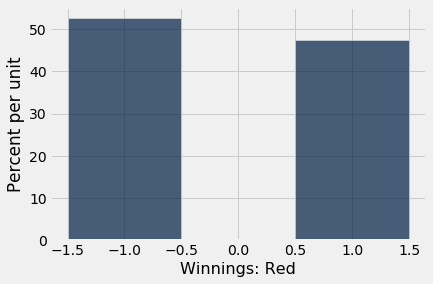
Agora suponha que você aposte muitas vezes no vermelho. Seus ganhos líquidos serão a soma de muitos sorteios feitos aleatoriamente com reposição da distribuição acima.
Será preciso um pouco de matemática para listar todos os valores possíveis de seus ganhos líquidos junto com todas as suas chances. Não faremos isso; em vez disso, aproximaremos a distribuição de probabilidade por simulação, como fizemos ao longo deste curso.
O código abaixo simula seu ganho líquido se você apostar $1 no vermelho em 400 giros diferentes da roleta.
num_bets = 400
repetitions = 10000
net_gain_red = make_array()
for i in np.arange(repetitions):
spins = red.sample(num_bets)
new_net_gain_red = spins.column('Winnings: Red').sum()
net_gain_red = np.append(net_gain_red, new_net_gain_red)
results = Table().with_column(
'Net Gain on Red', net_gain_red
)
results.hist(bins=np.arange(-80, 50, 6))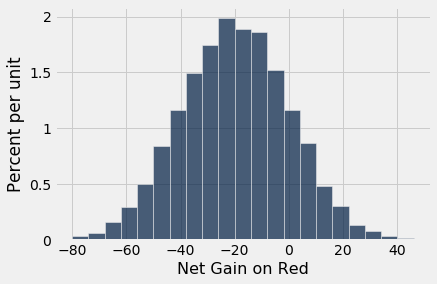
Esse é um histograma em formato de sino, embora a distribuição que estamos desenhando não esteja nem perto do formato de sino.
Centro. A distribuição está centrada perto de -20 dólares, aproximadamente. Para ver o porquê, observe que seus ganhos serão 1 em cerca de 18/38 das apostas e -1 nos 20/38 restantes. Portanto, seus ganhos médios por dólar apostado serão de aproximadamente -5,26 centavos:
average_per_bet = 1*(18/38) + (-1)*(20/38)
average_per_bet| Out[1]: | -0.05263157894736842 |
Então, em 400 apostas você espera que seu ganho líquido seja de cerca de -$21:
400 * average_per_bet| Out[2]: | -21.052631578947366 |
Para confirmação, podemos calcular a média dos 10.000 ganhos líquidos simulados:
np.mean(results.column(0))| Out[3]: | -20.9586 |
Dispersão. Passe o olho ao longo da curva começando no centro e observe que o ponto de inflexão está próximo de 0. Em uma curva em forma de sino, o SD é a distância do centro a um ponto de inflexão. O centro é aproximadamente -$20, o que significa que o SD da distribuição está em torno de $20.
Na próxima seção veremos de onde vem o $20. Por enquanto, vamos confirmar nossa observação simplesmente calculando o DP dos 10.000 ganhos líquidos simulados:
np.std(results.column(0))| Out[4]: | 20.029115957525438 |
Resumo. O ganho líquido em 400 apostas é a soma dos 400 valores ganhos em cada aposta individual. A distribuição de probabilidade dessa soma é aproximadamente normal, com uma média e um SD que podemos aproximar.
Atraso médio de voo
A tabela united contém dados sobre atrasos nas partidas de 13.825 voos domésticos da United Airlines saindo do aeroporto de São Francisco no verão de 2015. Como vimos antes, a distribuição dos atrasos tem uma longa cauda à direita.
united = Table.read_table(path_data + 'united_summer2015.csv')
united.select('Delay').hist(bins=np.arange(-20, 300, 10))
O atraso médio foi de cerca de 16,6 minutos e o SD foi de cerca de 39,5 minutos. Observe como o SD é grande, comparado à média. Esses grandes desvios à direita têm um efeito, embora sejam uma proporção muito pequena dos dados.
mean_delay = np.mean(united.column('Delay'))
sd_delay = np.std(united.column('Delay'))
mean_delay, sd_delay| Out[5]: | (16.658155515370705, 39.480199851609314) |
Agora, suponha que amostramos 400 atrasos aleatoriamente com reposição. Você poderia fazer uma amostragem sem reposição, se quiser, mas os resultados seriam muito semelhantes aos da amostragem com reposição. Se você amostrar algumas centenas de 13.825 sem reposição, dificilmente alterará a população cada vez que você extrai um valor.
Na amostra, qual poderia ser o atraso médio? Esperamos que seja em torno de 16 ou 17, porque essa é a média da população; mas é provável que esteja um pouco errado. Vamos ver o que obtemos por amostragem. Trabalharemos com a tabela delay que contém apenas a coluna de atrasos.
delay = united.select('Delay')
np.mean(delay.sample(400).column('Delay'))| Out[6]: | 15.59 |
A média amostral varia de acordo com o resultado da amostra, então vamos simular o processo de amostragem repetidamente e desenhar o histograma empírico da média amostral. Isso será uma aproximação do histograma de probabilidade da média amostral.
sample_size = 400
repetitions = 10000
means = make_array()
for i in np.arange(repetitions):
sample = delay.sample(sample_size)
new_mean = np.mean(sample.column('Delay'))
means = np.append(means, new_mean)
results = Table().with_column(
'Sample Mean', means
)
results.hist(bins=np.arange(10, 25, 0.5))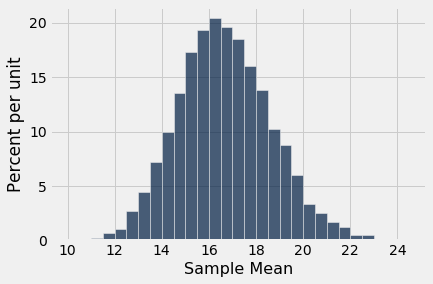
Mais uma vez, vemos um formato de sino aproximado, embora estejamos partindo de uma distribuição muito distorcida. O sino está centralizado em algum lugar entre 16 e 17, como esperamos.
Teorema Central do Limite
A razão pela qual a forma de sino aparece em tais configurações é um resultado notável da teoria da probabilidade chamado de Teorema Central do Limite.
O Teorema Central do Limite diz que a distribuição de probabilidade da soma ou média de uma grande amostra aleatória retirada com reposição será aproximadamente normal, independentemente da distribuição da população da qual a amostra é retirada.
Como observamos quando estávamos estudando os limites de Chebychev, resultados que podem ser aplicados a amostras aleatórias independentemente da distribuição da população são muito poderosos, porque em ciência de dados raramente conhecemos a distribuição da população.
O Teorema Central do Limite torna possível fazer inferências com muito pouco conhecimento sobre a população, desde que tenhamos uma grande amostra aleatória. Por isso, ele é central para o campo da inferência estatística.
Proporção de Flores Roxas
Relembre o modelo de probabilidade de Mendel para as cores das flores de uma espécie de planta de ervilha. O modelo diz que as cores das flores das plantas são como retiradas aleatórias com reposição de {Roxa, Roxa, Roxa, Branca}.
Em uma grande amostra de plantas, qual proporção terá flores roxas? Esperaríamos que a resposta fosse cerca de 0,75, a proporção de roxo no modelo. E, como proporções são médias, o Teorema Central do Limite diz que a distribuição da proporção amostral de plantas roxas é aproximadamente normal.
Podemos confirmar isso por simulação. Vamos simular a proporção de plantas com flores roxas em uma amostra de 200 plantas.
colors = make_array('Purple', 'Purple', 'Purple', 'White')
model = Table().with_column('Color', colors)
model| Color |
|---|
| Purple |
| Purple |
| Purple |
| White |
props = make_array()
num_plants = 200
repetitions = 10000
for i in np.arange(repetitions):
sample = model.sample(num_plants)
new_prop = np.count_nonzero(sample.column('Color') == 'Purple')/num_plants
props = np.append(props, new_prop)
results = Table().with_column('Sample Proportion: 200', props)
results.hist(bins=np.arange(0.65, 0.85, 0.01))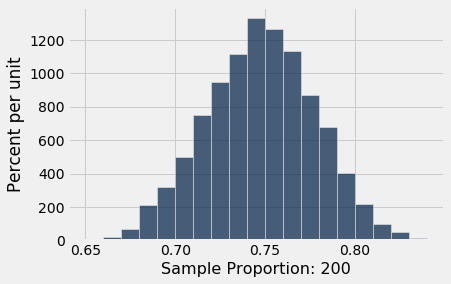
Há aquela curva normal novamente, conforme previsto pelo Teorema do Limite Central, centrada em torno de 0,75, exatamente como seria de esperar.
Como essa distribuição mudaria se aumentássemos o tamanho da amostra? Vamos executar o código novamente com um tamanho de amostra de 800 e coletar os resultados das simulações na mesma tabela em que coletamos simulações com base em um tamanho de amostra de 200. Iremos manter o número de repetitions igual ao anterior para que as duas colunas tenham o mesmo comprimento.
props2 = make_array()
num_plants = 800
for i in np.arange(repetitions):
sample = model.sample(num_plants)
new_prop = np.count_nonzero(sample.column('Color') == 'Purple')/num_plants
props2 = np.append(props2, new_prop)
results = results.with_column('Sample Proportion: 800', props2)
results.hist(bins=np.arange(0.65, 0.85, 0.01))
Ambas as distribuições são aproximadamente normais, mas uma é mais estreita do que a outra. As proporções baseadas em um tamanho de amostra de 800 estão mais agrupadas em torno de 0,75 do que aquelas de um tamanho de amostra de 200. Aumentar o tamanho da amostra reduziu a variabilidade na proporção da amostra.
Isso não deveria ser surpreendente. Muitas vezes, confiamos na intuição de que um tamanho de amostra maior geralmente reduz a variabilidade de uma estatística. No entanto, no caso de uma média amostral, podemos quantificar a relação entre o tamanho da amostra e a variabilidade.
Exatamente como o tamanho da amostra afeta a variabilidade de uma média amostral ou proporção? Essa é a pergunta que examinaremos na próxima seção.
| ← Capítulo 14.3 – DP e a Curva Normal | Capítulo 14.5 – Variabilidade da Média da Amostra → |