
Capítulo 8.1
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
Aplicando uma função a uma coluna
Temos visto muitos exemplos de criação de novas colunas de tabelas aplicando funções a colunas existentes ou a outros arrays. Todas essas funções tomavam arrays como argumentos. Mas frequentemente desejaremos converter as entradas em uma coluna por uma função que não recebe um array como seu argumento. Por exemplo, ele pode usar apenas um número como argumento, como na função cut_off_at_100 definida abaixo.
def cut_off_at_100(x):
"""O menor entre x e 100"""
return min(x, 100)cut_off_at_100(17)| Out[1]: | 17 |
cut_off_at_100(117)| Out[2]: | 100 |
cut_off_at_100(100)| Out[3]: | 100 |
A função cut_off_at_100 simplesmente retorna seu argumento se o argumento for menor ou igual a 100. Mas se o argumento for maior que 100, ela retorna 100.
Em nossos exemplos anteriores usando dados do censo, vimos que a variável AGE tinha um valor de 100 que significava “100 anos ou mais”. Cortar idades em 100 desta maneira é exatamente o que cut_off_at_100 faz.
Para usar esta função em muitas idades de uma vez, precisaremos ser capazes de referenciar a função em si, sem realmente chamá-la. Analogamente, poderíamos mostrar uma receita de bolo a um chef e pedir a ele para usá-la para assar 6 bolos. Nesse cenário, não estamos usando a receita para assar nenhum bolo nós mesmos; nosso papel é apenas referir o chef à receita. Da mesma forma, podemos pedir a uma tabela para chamar cut_off_at_100 em 6 números diferentes em uma coluna.
Primeiro, criamos a tabela ages com uma coluna para as pessoas e outra para suas idades. Por exemplo, a pessoa C tem 52 anos.
ages = Table().with_columns(
'Person', make_array('A', 'B', 'C', 'D', 'E', 'F'),
'Age', make_array(17, 117, 52, 100, 6, 101)
)
ages| Person | Age |
|---|---|
| A | 17 |
| B | 117 |
| C | 52 |
| D | 100 |
| E | 6 |
| F | 101 |
apply
Para cortar cada uma das idades em 100, usaremos um novo método Table. O método apply chama uma função em cada elemento de uma coluna, formando um novo array de valores de retorno. Para indicar qual função chamar, basta nomeá-la (sem aspas ou parênteses). O nome da coluna de valores de entrada é uma string que ainda deve aparecer entre aspas.
ages.apply(cut_off_at_100, 'Age')| Out[5]: | array([ 17, 100, 52, 100, 6, 100]) |
O que fizemos aqui foi apply a função cut_off_at_100 a cada valor na coluna Age da tabela ages. A saída é a matriz de valores de retorno correspondentes da função. Por exemplo, 17 permaneceu 17, 117 se tornou 100, 52 permaneceu 52, e assim por diante.
Esta matriz, que tem o mesmo comprimento que a coluna Age original da tabela ages, pode ser usada como os valores em uma nova coluna chamada Cut Off Age junto com as colunas existentes Person e Age.
ages.with_column(
'Cut Off Age', ages.apply(cut_off_at_100, 'Age')
)| Person | Age | Cut Off Age |
|---|---|---|
| A | 17 | 17 |
| B | 117 | 100 |
| C | 52 | 52 |
| D | 100 | 100 |
| E | 6 | 6 |
| F | 101 | 100 |
Funções como Valores
Já vimos que o Python possui muitos tipos de valores. Por exemplo, 6 é um valor numérico, "bolo" é um valor de texto, Table() é uma tabela vazia, e ages é um nome para um valor de tabela (já que o definimos acima).
Em Python, cada função, incluindo cut_off_at_100, também é um valor. Voltando à analogia anterior, iremos pensar novamente sobre receitas. Uma receita para bolo é uma coisa real, distinta de bolos ou ingredientes, e você pode dar a ela um nome como “Receita de bolo da Ani”. Quando definimos cut_off_at_100 com uma instrução def, na verdade fizemos duas coisas separadas: criamos uma função que corta números em 100, e a nomeamos de cut_off_at_100.
Podemos nos referir a qualquer função escrevendo seu nome, sem os parênteses ou argumentos necessários para realmente chamá-la. Fizemos isso quando chamamos apply acima. Quando escrevemos o nome de uma função sozinho como a última linha em uma célula, o Python produz uma representação de texto da função, assim como imprimiria um número ou um valor de string.
cut_off_at_100| Out[7]: | <function __main__.cut_off_at_100(x)> |
Observe que não escrevemos "cut_off_at_100" com aspas (que é apenas um pedaço de texto), ou cut_off_at_100() (que é uma chamada de função, e uma inválida). Simplesmente escrevemos cut_off_at_100 para nos referirmos à função.
Assim como podemos definir novos nomes para outros valores, podemos definir novos nomes para funções. Por exemplo, suponha que queiramos nos referir à nossa função como cut_off em vez de cut_off_at_100. Podemos simplesmente escrever isso:
cut_off = cut_off_at_100Agora cut_off é o nome de uma função. É a mesma função que cut_off_at_100, então o valor impresso é exatamente o mesmo.
cut_off| Out[8]: | <function __main__.cut_off_at_100(x)> |
Vejamos outra aplicação de apply.
Exemplo: Previsão
A ciência de dados é frequentemente usada para fazer previsões sobre o futuro. Se estivermos tentando prever um resultado para um determinado indivíduo – por exemplo, como ele responderá a um tratamento ou se ele comprará um produto – é natural basear-se a previsão dos resultados de outros indivíduos semelhantes.
A tabela abaixo foi adaptada de um conjunto de dados históricos sobre a altura dos pais e de seus filhos adultos. Cada linha corresponde a um filho adulto. As variáveis são um código numérico para a família, as alturas (em polegadas) do pai e da mãe , o número de filhos na família, bem como a classe de nascimento da criança (1 = mais velho), sexo (codificado apenas como “masculino” ou “feminino”) e altura em polegadas.
# Dados sobre a altura dos pais e dos filhos adultos
family_heights = Table.read_table(path_data + 'family_heights.csv').drop(3)
family_heights| family | father | mother | children | childNum | sex | childHeight |
|---|---|---|---|---|---|---|
| 1 | 78.5 | 67.0 | 4 | 1 | male | 73.2 |
| 1 | 78.5 | 67.0 | 4 | 2 | female | 69.2 |
| 1 | 78.5 | 67.0 | 4 | 3 | female | 69.0 |
| 1 | 78.5 | 67.0 | 4 | 4 | female | 69.0 |
| 2 | 75.5 | 66.5 | 4 | 1 | male | 73.5 |
| 2 | 75.5 | 66.5 | 4 | 2 | male | 72.5 |
| 2 | 75.5 | 66.5 | 4 | 3 | female | 65.5 |
| 2 | 75.5 | 66.5 | 4 | 4 | female | 65.5 |
| 3 | 75.0 | 64.0 | 2 | 1 | male | 71.0 |
| 3 | 75.0 | 64.0 | 2 | 2 | female | 68.0 |
Um dos principais motivos para coletar os dados era poder prever a altura adulta de uma criança nascida de pais semelhantes aos da base de dados. Vamos tentar fazer isso, usando a média simples da altura dos pais como a variável na qual basearemos nossa previsão.
Esta altura média dos pais é nossa variável preditora. Na célula abaixo, seus valores estão no array parent_averages.
A tabela heights consiste apenas das alturas médias dos pais e das alturas das crianças. O gráfico de dispersão das duas variáveis mostra uma associação positiva, como esperado para essas variáveis.
parent_averages = (family_heights.column('father') + family_heights.column('mother'))/2
heights = Table().with_columns(
'Parent Average', parent_averages,
'Child', family_heights.column('childHeight')
)
heights| Parent Average | Child |
|---|---|
| 72.75 | 73.2 |
| 72.75 | 69.2 |
| 72.75 | 69.0 |
| 72.75 | 69.0 |
| 71.0 | 73.5 |
| 71.0 | 72.5 |
| 71.0 | 65.5 |
| 71.0 | 65.5 |
| 69.5 | 71.0 |
| 69.5 | 68.0 |
heights.scatter('Parent Average')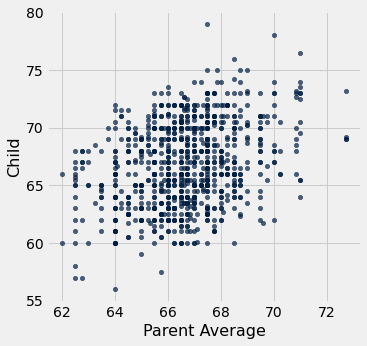
Agora, suponha que os pesquisadores encontrem um novo casal, semelhante aos da base de dados, e se perguntem qual seria a altura de seu filho. Qual seria uma boa maneira para eles preverem a altura da criança, dado que a altura média dos pais era, digamos, 68 polegadas?
Uma abordagem razoável seria basear a previsão em todos os pontos que correspondem a uma altura média dos pais de cerca de 68 polegadas. A previsão seria igual à média da altura das crianças calculada apenas a partir desses pontos.
Vamos executar esse plano. Por enquanto, faremos uma definição razoável do que significa “cerca de 68 polegadas” e trabalharemos com isso. Mais tarde no curso, examinaremos as consequências de tais escolhas.
Vamos considerar “próximo” como “dentro de meia polegada”. A figura abaixo mostra todos os pontos correspondentes a uma altura média dos pais entre 67,5 polegadas e 68,5 polegadas. Esses são todos os pontos na faixa entre as linhas vermelhas. Cada um desses pontos corresponde a uma criança; nossa previsão da altura do filho do novo casal é a altura média de todas as crianças na faixa. Isso é representado pelo ponto dourado.
Ignore o código e concentre-se apenas em entender o processo mental de chegar a esse ponto dourado.
heights.scatter('Parent Average')
plots.plot([67.5, 67.5], [50, 85], color='red', lw=2)
plots.plot([68.5, 68.5], [50, 85], color='red', lw=2)
plots.scatter(68, 67.62, color='gold', s=40);
Para calcular exatamente onde o ponto dourado deveria estar, primeiro precisamos identificar todos os pontos na faixa. Eles correspondem às linhas onde a Parente Average está entre 67,5 polegadas e 68,5 polegadas.
close_to_68 = heights.where('Parent Average', are.between(67.5, 68.5))
close_to_68| Parent Average | Child |
|---|---|
| 68.0 | 74.0 |
| 68.0 | 70.0 |
| 68.0 | 68.0 |
| 68.0 | 67.0 |
| 68.0 | 67.0 |
| 68.0 | 66.0 |
| 68.0 | 63.5 |
| 68.0 | 63.0 |
| 67.5 | 65.0 |
| 68.1 | 62.7 |
A altura prevista de uma criança cuja altura média dos pais é de 68 polegadas é a altura média das crianças nessas fileiras. Isso é 67,62 polegadas.
np.average(close_to_68.column('Child'))| Out[12]: | 67.625 |
Agora temos uma maneira de prever a altura de uma criança, dado qualquer valor da altura média dos pais próximo daqueles em nosso conjunto de dados. Podemos definir uma função predict_child que faz isso. O corpo da função consiste no código nas duas células acima, além das escolhas de nomes.
def predict_child(p_avg):
"""Preveja a altura de uma criança cujos pais têm uma altura média dos pais de p_avg.
A previsão é a altura média das crianças cuja altura média dos pais está
no intervalo p_avg mais ou menos 0,5.
"""
close_points = heights.where('Parent Average', are.between(p_avg-0.5, p_avg + 0.5))
return np.average(close_points.column('Child'))Dada uma altura média dos pais de 68 polegadas, a função predict_child retorna a mesma previsão (67,62 polegadas) que obtivemos anteriormente. A vantagem de definir a função é que podemos facilmente alterar o valor do preditor e obter uma nova previsão.
predict_child(68)| Out[13]: | 67.625 |
predict_child(66)| Out[14]: | 66.83333333333333 |
Quão boas são essas previsões? Podemos ter uma ideia disso comparando as previsões com os dados que já temos. Para fazer isso, primeiro aplicamos a função predict_child à coluna de alturas Parent Average e coletamos os resultados em uma nova coluna chamada Prediction.
# Aplique predict_child a todas as alturas médias dos pais
heights_with_predictions = heights.with_column(
'Prediction', heights.apply(predict_child, 'Parent Average')
)heights_with_predictions| Parent Average | Child | Prediction |
|---|---|---|
| 72.75 | 73.2 | 70.1 |
| 72.75 | 69.2 | 70.1 |
| 72.75 | 69.0 | 70.1 |
| 72.75 | 69.0 | 70.1 |
| 71.0 | 73.5 | 70.4158 |
| 71.0 | 72.5 | 70.4158 |
| 71.0 | 65.5 | 70.4158 |
| 71.0 | 65.5 | 70.4158 |
| 69.5 | 71.0 | 68.5025 |
| 69.5 | 68.0 | 68.5025 |
Para ver onde as previsões estão em relação aos dados observados, podemos desenhar gráficos de dispersão sobrepostos com Parent Average como o eixo horizontal comum.
heights_with_predictions.scatter('Parent Average')
O gráfico de pontos dourados é chamado de gráfico de médias, porque cada ponto dourado é o centro de uma faixa vertical como a que desenhamos anteriormente. Cada um fornece uma previsão da altura de uma criança dada a altura média dos pais. Por exemplo, o gráfico de dispersão mostra que para uma altura média dos pais de 65 polegadas, a altura prevista da criança seria pouco acima de 65 polegadas, e de fato predict_child(65) avalia para cerca de 65.84.
predict_child(65)| Out[16]: | 65.84 |
Observe que o gráfico de médias segue aproximadamente uma linha reta. Esta linha reta é agora chamada de linha de regressão e é um dos métodos mais comuns de fazer previsões. O cálculo que acabamos de fazer é muito semelhante ao cálculo que levou ao desenvolvimento do método de regressão, usando os mesmos dados.
Este exemplo, assim como o exemplo da análise das mortes por cólera de John Snow, mostra como alguns dos conceitos fundamentais da ciência de dados moderna têm raízes que remontam a muito tempo atrás. O método usado aqui foi um precursor dos métodos de previsão vizinho mais próximo que agora têm aplicações poderosas em diversos contextos. O campo moderno de aprendizado de máquina inclui a automação de tais métodos para fazer previsões com base em conjuntos de dados vastos e em rápida evolução.
| ← Capítulo 8 – Funções e Tabelas | Capítulo 8.2 – Classificando por uma Variável → |