
Capítulo 14.6
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
import numpy as np
path_data = '../../../../data/'
%matplotlib inline
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
Escolhendo um Tamanho de Amostra
A candidata A está disputando uma eleição. Uma organização de pesquisa deseja estimar a proporção de eleitores que votarão nela. Vamos supor que eles planejam tirar uma amostra aleatória simples de eleitores, embora na realidade seu método de amostragem seja mais complexo. Como eles podem decidir qual deve ser o tamanho da amostra para obter um nível desejado de precisão?
Agora estamos em posição de responder a essa pergunta, depois de fazer algumas suposições:
- A população de eleitores é muito grande e, portanto, podemos supor que a amostra aleatória será retirada com reposição.
- A organização de pesquisa fará sua estimativa construindo um intervalo de confiança aproximado de 95% para a percentagem de eleitores que votarão na candidata A.
- O nível desejado de precisão é que a largura do intervalo não deve ser superior a 1%. Isso é bastante preciso! Por exemplo, o intervalo de confiança (33,2%, 34%) seria aceitável, mas (33,2%, 35%) não seria.
Vamos trabalhar com a proporção amostral de eleitores para a candidata A. Lembre-se de que uma proporção é uma média, quando os valores na população são apenas 0 (o tipo de indivíduo que você não está contando) ou 1 (o tipo de indivíduo que você está contando).
Largura do Intervalo de Confiança
Se tivéssemos uma amostra aleatória, poderíamos usar a técnica de bootstrap para construir um intervalo de confiança para a percentagem de eleitores para a candidata A. Mas ainda não temos uma amostra – estamos tentando descobrir o quão grande a amostra deve ser para que nosso intervalo de confiança seja tão estreito quanto queremos.
Em situações como esta, é útil ver o que a teoria prevê.
O Teorema do Limite Central diz que as probabilidades para a proporção da amostra são aproximadamente normalmente distribuídas, centradas na proporção populacional de 1’s, com um desvio padrão igual ao desvio padrão da população de 0’s e 1’s dividido pela raiz quadrada do tamanho da amostra.
Portanto, o intervalo de confiança ainda será o “meio 95%” de uma distribuição normal, mesmo que não possamos pegar as extremidades como o 2,5º e o 97,5º percentis das proporções bootstrapadas.
Existe outra maneira de encontrar a largura do intervalo? Sim, porque sabemos que, para variáveis normalmente distribuídas, o intervalo “centro ± 2 desvios padrão” contém 95% dos dados.
O intervalo de confiança se estenderá por 2 desvios padrão da proporção da amostra, de cada lado do centro. Portanto, a largura do intervalo será de 4 desvios padrão da proporção da amostra.
Estamos dispostos a tolerar uma largura de 1% = 0,01. Portanto, usando a fórmula desenvolvida na última seção,
Assim,
O Desvio Padrão de uma coleção de 0’s e 1’s
Se soubéssemos o desvio padrão da população, estaríamos prontos. Poderíamos calcular a raiz quadrada do tamanho da amostra e depois elevar ao quadrado para obter o tamanho da amostra. Mas não sabemos o desvio padrão da população. A população consiste em 1 para cada eleitor para a candidata A e 0 para todos os outros eleitores, e não sabemos qual proporção de cada tipo existe. É isso que estamos tentando estimar.
Então, estamos presos? Não, porque podemos limitar o desvio padrão da população. Aqui estão histogramas de duas dessas distribuições, uma para uma proporção igual de 1’s e 0’s, e outra com 90% de 1’s e 10% de 0’s. Qual delas tem o maior desvio padrão?
pop_50 = make_array(1, 1, 1, 1, 1, 0, 0, 0, 0, 0)
pop_90 = make_array(1, 1, 1, 1, 1, 1, 1, 1, 1, 0)
coins = Table().with_columns(
"Proportion of 1's: 0.5", pop_50,
"Proportion of 1's: 0.9", pop_90,
)
coins.hist(bins=np.arange(-0.5, 1.6, 1))
plots.scatter(0.5, -0.02, marker='^', color='darkblue', s=60)
plots.scatter(0.9, -0.02, marker='^', color='gold', s=60)
plots.ylim(-0.05, 1);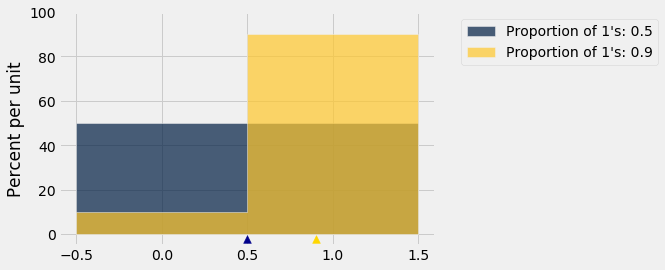
Lembre-se de que os possíveis valores na população são apenas 0 e 1.
O histograma azul (50% 1’s e 50% 0’s) tem mais dispersão do que o dourado. A média é 0.5. Metade das desvios da média é igual a 0.5 e a outra metade é igual a -0.5, então o desvio padrão é 0.5.
No histograma dourado, toda a área está concentrada em torno de 1, resultando em menos dispersão. 90% dos desvios são pequenos: 0.1. Os outros 10% são -0.9, que é grande, mas no geral a dispersão é menor do que no histograma azul.
A mesma observação seria válida se variássemos a proporção de 1’s ou deixássemos a proporção de 0’s maior do que a proporção de 1’s. Vamos verificar isso calculando os desvios padrão de populações de 10 elementos que consistem apenas em 0’s e 1’s, em proporções variadas. A função np.ones é útil para isso. Ela recebe um número inteiro positivo como argumento e retorna um array consistindo desse número de 1’s.
sd = make_array()
for i in np.arange(1, 10, 1):
# Cria um array de i 1's e (10-i) 0's
population = np.append(np.ones(i), 1-np.ones(10-i))
sd = np.append(sd, np.std(population))
zero_one_sds = Table().with_columns(
"Population Proportion of 1's", np.arange(0.1, 1, 0.1),
"Population SD", sd
)
zero_one_sds| Population Proportion of 1’s | Population SD |
|---|---|
| 0.1 | 0.3 |
| 0.2 | 0.4 |
| 0.3 | 0.458258 |
| 0.4 | 0.489898 |
| 0.5 | 0.5 |
| 0.6 | 0.489898 |
| 0.7 | 0.458258 |
| 0.8 | 0.4 |
| 0.9 | 0.3 |
Não é de surpreender que o SD de uma população com 10% de 1 e 90% de 0 seja o mesmo que o de uma população com 90% de 1 e 10% de 0. Isso ocorre porque você troca as barras de um histograma para obter o outro; há nenhuma mudança na dispersão.
Mais importante para nossos propósitos, o SD aumenta à medida que a proporção de 1 aumenta, até que a proporção de 1 seja 0,5; então começa a diminuir simetricamente.
zero_one_sds.scatter("Population Proportion of 1's")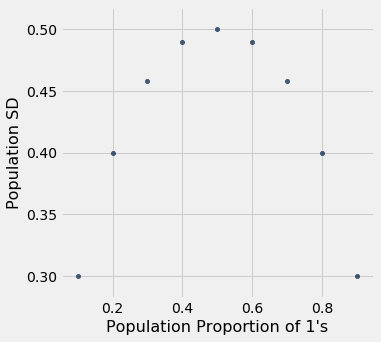
Resumo: O SD de uma população de 1 e 0 é no máximo 0,5. Esse é o valor do SD quando 50% da população é codificada como 1 e os outros 50% são codificados como 0.
O Tamanho da Amostra
Sabemos que
e que o SD da população 0-1 é no máximo 0.5, independentemente da proporção de 1’s na população. Portanto, é seguro tomar
Portanto, o tamanho da amostra deve ser pelo menos 200^2 = 40,000. É uma amostra enorme! Mas é isso que você precisa se deseja garantir uma grande precisão com alta confiança, não importa como seja a população.
| ← Capítulo 14.5 – Variabilidade da Média da Amostra | Capítulo 15 – Previsão → |