
Capítulo 10.2
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
path_data = '../../../assets/data/'
import matplotlib
matplotlib.use('Agg')
%matplotlib inline
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
import numpy as np
Amostragem de uma População
A lei das médias também se aplica quando a amostra aleatória é extraída de indivíduos em uma grande população.
Como exemplo, vamos estudar uma população de tempos de atraso de voo. A tabela united contém dados de voos domésticos da United Airlines partindo de São Francisco no verão de 2015. Os dados são disponibilizados publicamente pelo Bureau of Transportation Statistics do Departamento de Transporte dos Estados Unidos.
Há 13.825 linhas, cada uma correspondendo a um voo. As colunas são a data do voo, o número do voo, o código do aeroporto de destino e o tempo de atraso na partida em minutos. Alguns tempos de atraso são negativos: esses voos partiram adiantados.
united = Table.read_table(path_data + 'united_summer2015.csv')
united| Date | Flight Number | Destination | Delay |
|---|---|---|---|
| 6/1/15 | 73 | HNL | 257 |
| 6/1/15 | 217 | EWR | 28 |
| 6/1/15 | 237 | STL | -3 |
| 6/1/15 | 250 | SAN | 0 |
| 6/1/15 | 267 | PHL | 64 |
| 6/1/15 | 273 | SEA | -6 |
| 6/1/15 | 278 | SEA | -8 |
| 6/1/15 | 292 | EWR | 12 |
| 6/1/15 | 300 | HNL | 20 |
| 6/1/15 | 317 | IND | -10 |
Um voo partiu 16 minutos mais cedo e outro atrasou 580 minutos. Os outros atrasos foram quase todos entre -10 minutos e 200 minutos, como mostra o histograma abaixo.
united.column('Delay').min()| Out[1]: | -16 |
united.column('Delay').max()| Out[2]: | 580 |
delay_bins = np.append(np.arange(-20, 301, 10), 600)
united.hist('Delay', bins = delay_bins, unit = 'minute')
Para efeitos desta seção, basta ampliar o grosso dos dados e ignorar os 0,8% dos voos que tiveram atrasos superiores a 200 minutos.
united.where('Delay', are.above(200)).num_rows/united.num_rows| Out[3]: | 0.008101989873417 |
delay_bins = np.arange(-20, 201, 10)
united.hist('Delay', bins = delay_bins, unit = 'minute')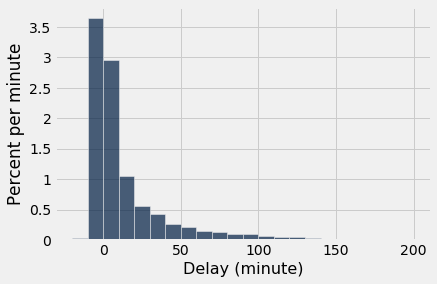
A altura da barra [0, 10) é pouco menos de 3% por minuto, o que significa que pouco menos de 30% dos voos tiveram atrasos entre 0 e 10 minutos. Isso é confirmado pela contagem das linhas:
united.where('Delay', are.between(0, 10)).num_rows/united.num_rows| Out[4]: | 0.2954935985895 |
Distribuição Empírica da Amostra
Vamos agora pensar nos 13.825 voos como uma população e extrair amostras aleatórias dela com reposição. É útil empacotar nosso código em uma função. A função empirical_hist_delay toma o tamanho da amostra como argumento e desenha um histograma empírico dos resultados.
def empirical_hist_delay(n):
united.sample(n).hist('Delay', bins = delay_bins, unit = 'minute')
Como vimos com os dados, à medida que o tamanho da amostra aumenta, o histograma empírico da amostra se assemelha mais ao histograma da população. Compare esses histogramas com o histograma da população acima.
empirical_hist_delay(10)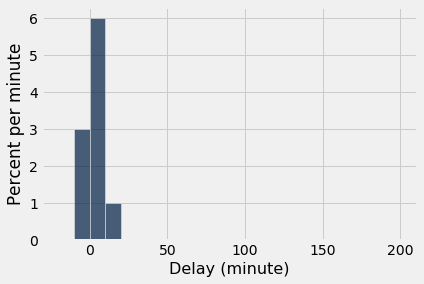
empirical_hist_delay(100)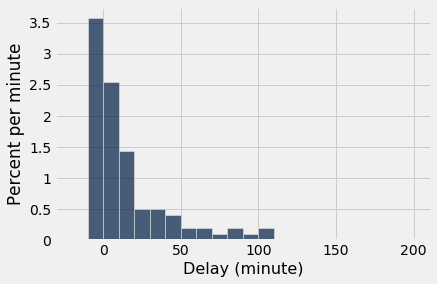
As discrepâncias mais consistentemente visíveis estão entre os valores que são raros na população. No nosso exemplo, esses valores estão na cauda direita da distribuição. Mas à medida que o tamanho da amostra aumenta, mesmo esses valores começam a aparecer na amostra aproximadamente nas proporções corretas.
empirical_hist_delay(1000)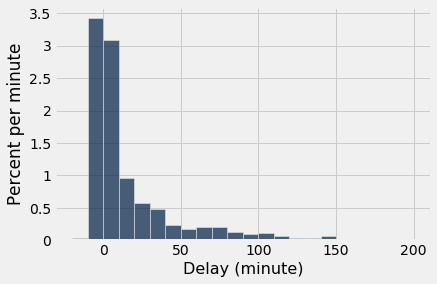
Convergência do Histograma Empírico da Amostra
O que observamos nesta seção pode ser resumido da seguinte forma:
Para uma grande amostra aleatória, o histograma empírico da amostra se assemelha ao histograma da população, com alta probabilidade.
Isso justifica o uso de grandes amostras aleatórias na inferência estatística. A ideia é que, como uma grande amostra aleatória provavelmente se assemelha à população da qual foi extraída, as quantidades calculadas a partir dos valores na amostra provavelmente estarão próximas das quantidades correspondentes na população.
| ← Capítulo 10.1 – Distribuições Empíricas | Capítulo 10.3 – Distribuição Empírica de Estatística → |