
Capítulo 15.4
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
%matplotlib inline
path_data = '../../../assets/data/'
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
import numpy as np
Regressão de Mínimos Quadrados
Em uma seção anterior, desenvolvemos fórmulas para a inclinação e a interceptação da linha de regressão por meio de um diagrama de dispersão em formato de bola de futebol. Acontece que a inclinação e a interceptação da linha de mínimos quadrados têm as mesmas fórmulas daquelas que desenvolvemos, independentemente da forma do gráfico de dispersão.
Vimos isso no exemplo sobre Little Women, mas vamos confirmar em um exemplo em que o gráfico de dispersão claramente não tem o formato de um futebol americano. Pelos dados, estamos mais uma vez em dívida com os ricos arquivos de dados do Prof. Larry Winner da Universidade da Flórida. Um estudo de 2013 no International Journal of Exercise Science estudou atletas universitários de arremesso de peso e examinou a relação entre força e distância de arremesso de peso. A população consiste em 28 atletas universitárias. A força foi medida pela maior quantidade (em quilogramas) que o atleta levantou. o “1RM power clean” na pré-temporada A distância (em metros) foi a melhor marca pessoal do atleta.
def standard_units(any_numbers):
"Converta qualquer array de números em unidades padrão."
return (any_numbers - np.mean(any_numbers))/np.std(any_numbers)
def correlation(t, x, y):
return np.mean(standard_units(t.column(x))*standard_units(t.column(y)))
def slope(table, x, y):
r = correlation(table, x, y)
return r * np.std(table.column(y))/np.std(table.column(x))
def intercept(table, x, y):
a = slope(table, x, y)
return np.mean(table.column(y)) - a * np.mean(table.column(x))
def fit(table, x, y):
"""Retorne a altura da linha de regressão em cada valor de x."""
a = slope(table, x, y)
b = intercept(table, x, y)
return a * table.column(x) + b
shotput = Table.read_table(path_data + 'shotput.csv')
shotput| Weight Lifted | Shot Put Distance |
|---|---|
| 37.5 | 6.4 |
| 51.5 | 10.2 |
| 61.3 | 12.4 |
| 61.3 | 13 |
| 63.6 | 13.2 |
| 66.1 | 13 |
| 70 | 12.7 |
| 92.7 | 13.9 |
| 90.5 | 15.5 |
| 90.5 | 15.8 |
shotput.scatter('Weight Lifted')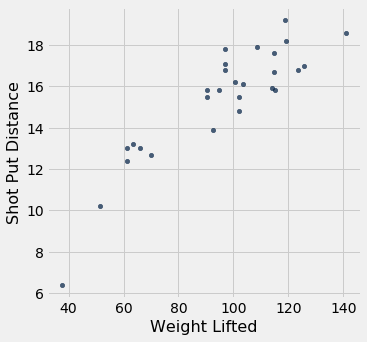
Esse não é um gráfico de dispersão em forma de bola de futebol. Na verdade, parece ter um leve componente não linear. Mas se insistirmos em usar uma linha reta para fazer nossas previsões, ainda existe uma melhor linha reta entre todas as linhas retas.
Nossas fórmulas para a inclinação e interceptação da linha de regressão, derivadas de gráficos de dispersão em formato de futebol, fornecem os seguintes valores.
slope(shotput, 'Weight Lifted', 'Shot Put Distance')| Out[1]: | 0.09834382159781997 |
intercept(shotput, 'Weight Lifted', 'Shot Put Distance')| Out[2]: | 5.959629098373952 |
Ainda faz sentido usar essas fórmulas mesmo que o gráfico de dispersão não tenha o formato de uma bola de futebol? Podemos responder isso encontrando a inclinação e a interceptação da linha que minimiza o mse.
Definiremos a função shotput_linear_mse para obter uma inclinação arbitrária e interceptar como argumentos e retornar o mse correspondente. Então minimize aplicado a shotput_linear_mse retornará a melhor inclinação e interceptação.
def shotput_linear_mse(any_slope, any_intercept):
x = shotput.column('Weight Lifted')
y = shotput.column('Shot Put Distance')
fitted = any_slope*x + any_intercept
return np.mean((y - fitted) ** 2)
minimize(shotput_linear_mse)| Out[3]: | array([0.09834382, 5.95962911]) |
Esses valores são os mesmos que obtivemos usando nossas fórmulas. Para resumir:
Independentemente da forma do gráfico de dispersão, existe uma linha única que minimiza o erro quadrático médio da estimativa. Ela é chamada de linha de regressão, e sua inclinação e intercepto são dados por
fitted = fit(shotput, 'Weight Lifted', 'Shot Put Distance')
shotput.with_column('Best Straight Line', fitted).scatter('Weight Lifted')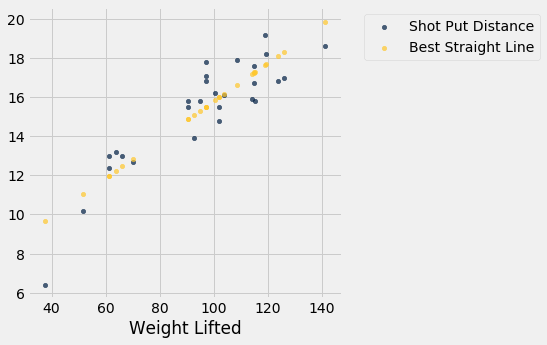
Regressão Não Linear
O gráfico acima reforça nossa observação anterior de que o gráfico de dispersão é um pouco curvado. Portanto, é melhor ajustar uma curva do que uma linha reta. O estudo postulou uma relação quadrática entre o peso levantado e a distância do arremesso de peso. Então, vamos usar funções quadráticas como nossos preditores e ver se conseguimos encontrar a melhor.
Temos que encontrar a melhor função quadrática entre todas as funções quadráticas, em vez da melhor linha reta entre todas as linhas retas. O método dos mínimos quadrados nos permite fazer isso.
A matemática dessa minimização é complicada e não é fácil de ver apenas examinando o gráfico de dispersão. Mas a minimização numérica é tão fácil quanto com preditores lineares! Podemos obter o melhor preditor quadrático usando novamente minimize. Vamos ver como isso funciona.
Lembre-se de que uma função quadrática tem a forma
para constantes a, b e c.
Para encontrar a melhor função quadrática para prever a distância com base no peso levantado, usando o critério dos mínimos quadrados, primeiro escreveremos uma função que recebe as três constantes como argumentos, calcula os valores ajustados usando a função quadrática acima e, em seguida, retorna o erro quadrático médio.
A função é chamada shotput_quadratic_mse. Observe que a definição é análoga à de lw_mse, exceto que os valores ajustados são baseados em uma função quadrática em vez de linear.
def shotput_quadratic_mse(a, b, c):
x = shotput.column('Weight Lifted')
y = shotput.column('Shot Put Distance')
fitted = a*(x**2) + b*x + c
return np.mean((y - fitted) ** 2)
Agora podemos usar minimize como antes para encontrar as constantes que minimizam o erro quadrático médio.
best = minimize(shotput_quadratic_mse)
best| Out[4]: | array([-1.04004838e-03, 2.82708045e-01, -1.53182115e+00]) |
Nossa previsão da distância do arremesso de peso para um atleta que levanta x quilogramas é de cerca de
metros. Por exemplo, se o atleta consegue levantar 100 quilos, a distância prevista é de 16,33 metros. No gráfico de dispersão, isso está próximo ao centro de uma faixa vertical em torno de 100 quilos.
(-0.00104)*(100**2) + 0.2827*100 - 1.5318| Out[5]: | 16.3382 |
Aqui estão as previsões para todos os valores de Weight Lifted. Você pode ver que eles passam pelo centro do gráfico de dispersão, numa aproximação aproximada.
x = shotput.column(0)
shotput_fit = best.item(0)*(x**2) + best.item(1)*x + best.item(2)
shotput.with_column('Best Quadratic Curve', shotput_fit).scatter(0)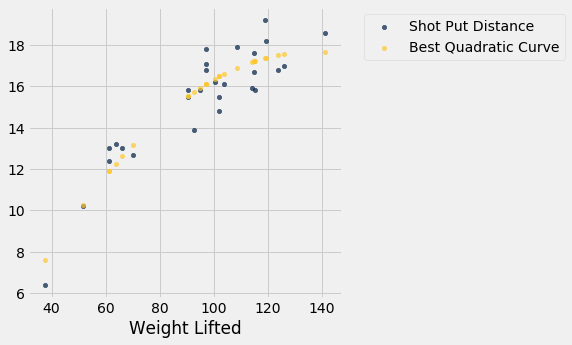
Nota: Ajustamos uma quadrática aqui porque foi sugerida no estudo original. Mas é importante notar que na extremidade direita do gráfico, a curva quadrática parece estar próxima do pico, após o qual a curva irá começar a descer. Portanto, talvez não queiramos usar este modelo para novos atletas que conseguem levantar pesos muito maiores do que aqueles em nosso conjunto de dados.
| ← Capítulo 15.3 – Método dos Mínimos Quadrados | Capítulo 15.5 – Diagnósticos Visuais → |