
Capítulo 15.5
Índice
- 1. O que é Ciência de Dados?
- 2. Causalidade e Experimentos
- 3. Progamando em Python
- 4. Tipos de Dados
- 5. Sequências
- 6. Tabelas
- 7. Visualização
- 8. Funções e Tabelas
- 9. Aleatoriedade
- 10. Amostragem e Distribuições Empíricas
- 11. Testando Hipóteses
- 12. Comparando Duas Amostras
- 13. Estimação
- 14. Por que a Média é Importante
- 15. Previsão
from datascience import *
path_data = '../../../assets/data/'
import numpy as np
from scipy import stats
import matplotlib
matplotlib.use('Agg')
%matplotlib inline
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
Diagnósticos Visuais
Suponha que um cientista de dados tenha decidido usar a regressão linear para estimar valores de uma variável (chamada de variável de resposta) com base em outra variável (chamada de preditora). Para ver quão bem esse método de estimativa funciona, o cientista de dados deve medir quão distantes as estimativas estão dos valores reais. Essas diferenças são chamadas de resíduos.
Um resíduo é o que sobra – o resíduo – após a estimativa.
Os resíduos são as distâncias verticais dos pontos à linha de regressão. Há um resíduo para cada ponto no diagrama de dispersão. O resíduo é a diferença entre o valor observado de y e o valor ajustado de y, então para o ponto (x, y),
A função residual calcula os resíduos. O cálculo assume todas as funções relevantes que já definimos: standard_units, correlation, slope, intercept, e fit.
family_heights = Table.read_table(path_data + 'family_heights.csv')
heights = family_heights.select('midparentHeight', 'childHeight')
heights = heights.relabel(0, 'MidParent').relabel(1, 'Child')
hybrid = Table.read_table(path_data + 'hybrid.csv')def standard_units(x):
return (x - np.mean(x))/np.std(x)
def correlation(table, x, y):
x_in_standard_units = standard_units(table.column(x))
y_in_standard_units = standard_units(table.column(y))
return np.mean(x_in_standard_units * y_in_standard_units)
def slope(table, x, y):
r = correlation(table, x, y)
return r * np.std(table.column(y))/np.std(table.column(x))
def intercept(table, x, y):
a = slope(table, x, y)
return np.mean(table.column(y)) - a * np.mean(table.column(x))
def fit(table, x, y):
a = slope(table, x, y)
b = intercept(table, x, y)
return a * table.column(x) + bdef residual(table, x, y):
return table.column(y) - fit(table, x, y)Continuando nosso exemplo de estimativa da altura dos filhos adultos (a resposta) com base na altura dos pais médios (o preditor), vamos calcular os valores ajustados e os resíduos.
heights = heights.with_columns(
'Fitted Value', fit(heights, 'MidParent', 'Child'),
'Residual', residual(heights, 'MidParent', 'Child')
)
heights| MidParent | Child | Fitted Value | Residual |
|---|---|---|---|
| 75.43 | 73.2 | 70.7124 | 2.48763 |
| 75.43 | 69.2 | 70.7124 | -1.51237 |
| 75.43 | 69 | 70.7124 | -1.71237 |
| 75.43 | 69 | 70.7124 | -1.71237 |
| 73.66 | 73.5 | 69.5842 | 3.91576 |
| 73.66 | 72.5 | 69.5842 | 2.91576 |
| 73.66 | 65.5 | 69.5842 | -4.08424 |
| 73.66 | 65.5 | 69.5842 | -4.08424 |
| 72.06 | 71 | 68.5645 | 2.43553 |
| 72.06 | 68 | 68.5645 | -0.564467 |
Quando há tantas variáveis para trabalhar, é sempre útil começar com a visualização. A função scatter_fit desenha o gráfico de dispersão dos dados, bem como a linha de regressão.
def scatter_fit(table, x, y):
table.scatter(x, y, s=15)
plots.plot(table.column(x), fit(table, x, y), lw=4, color='gold')
plots.xlabel(x)
plots.ylabel(y)scatter_fit(heights, 'MidParent', 'Child')
Um gráfico residual pode ser desenhado plotando os resíduos em relação à variável preditora. A função residual_plot faz exatamente isso.
def residual_plot(table, x, y):
x_array = table.column(x)
t = Table().with_columns(
x, x_array,
'residuals', residual(table, x, y)
)
t.scatter(x, 'residuals', color='r')
xlims = make_array(min(x_array), max(x_array))
plots.plot(xlims, make_array(0, 0), color='darkblue', lw=4)
plots.title('Residual Plot')residual_plot(heights, 'MidParent', 'Child')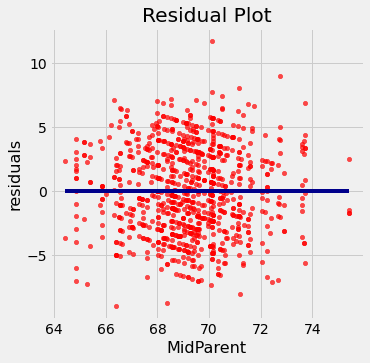
As alturas dos pais médios estão no eixo horizontal, como no gráfico de dispersão original. Mas agora o eixo vertical mostra os resíduos. Observe que o gráfico parece estar centralizado em torno da linha horizontal no nível 0 (mostrado em azul escuro). Observe também que o gráfico não mostra nenhuma tendência ascendente ou descendente. Observaremos mais tarde que esta falta de tendência é verdadeira para todas as regressões.
Diagnóstico de Regressão
Os gráficos residuais nos ajudam a fazer avaliações visuais da qualidade de uma análise de regressão linear. Tais avaliações são chamadas de diagnósticos. A função regression_diagnostic_plots desenha o gráfico de dispersão original, bem como o gráfico residual para facilitar a comparação.
def regression_diagnostic_plots(table, x, y):
scatter_fit(table, x, y)
residual_plot(table, x, y)regression_diagnostic_plots(heights, 'MidParent', 'Child')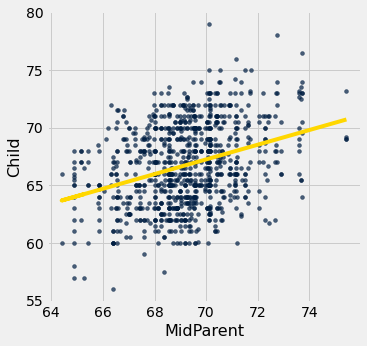
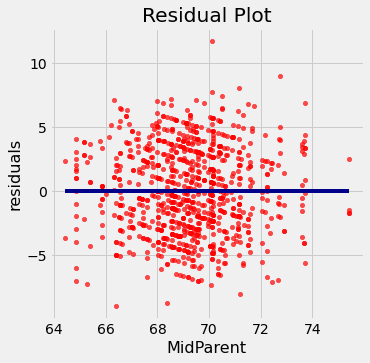
Este gráfico de resíduos indica que a regressão linear foi um método razoável de estimativa. Observe como os resíduos estão distribuídos de forma bastante simétrica acima e abaixo da linha horizontal em 0, correspondendo ao gráfico de dispersão original sendo aproximadamente simétrico acima e abaixo. Note também que a dispersão vertical do gráfico é bastante uniforme ao longo dos valores mais comuns das alturas das crianças. Em outras palavras, com exceção de alguns pontos fora do padrão, o gráfico não é mais estreito em alguns lugares e mais largo em outros.
Em outras palavras, a precisão da regressão parece ser aproximadamente a mesma ao longo do intervalo observado da variável preditora.
O gráfico de resíduos de uma boa regressão não mostra nenhum padrão. Os resíduos parecem semelhantes, acima e abaixo da linha horizontal em 0, ao longo do intervalo da variável preditora.
Detectando Não Linearidade
Desenhar o gráfico de dispersão dos dados geralmente dá uma indicação de se a relação entre as duas variáveis é não linear. Muitas vezes, no entanto, é mais fácil detectar não linearidade em um gráfico de resíduos do que no gráfico de dispersão original. Isso geralmente se deve às escalas dos dois gráficos: o gráfico de resíduos nos permite aumentar o zoom nos erros e, portanto, facilita a identificação de padrões.

Nossos dados são um conjunto de dados sobre a idade e o comprimento dos dugongos, que são mamíferos marinhos relacionados aos peixes-boi e vacas-marinhas (imagem da Wikimedia Commons). Os dados estão em uma tabela chamada dugong. A idade é medida em anos e o comprimento em metros. Como os dugongos tendem a não acompanhar seus aniversários, as idades são estimadas com base em variáveis como a condição de seus dentes.
{kind=link}
dugong = Table.read_table(path_data + 'dugongs.csv')
dugong = dugong.move_to_start('Length')
dugong| Length | Age |
|---|---|
| 1.8 | 1 |
| 1.85 | 1.5 |
| 1.87 | 1.5 |
| 1.77 | 1.5 |
| 2.02 | 2.5 |
| 2.27 | 4 |
| 2.15 | 5 |
| 2.26 | 5 |
| 2.35 | 7 |
| 2.47 | 8 |
Se pudéssemos medir o comprimento de um dugongo, o que poderíamos dizer sobre a sua idade? Vamos examinar o que os nossos dados dizem. Aqui está uma regressão da idade (a resposta) no comprimento (o preditor). A correlação entre as duas variáveis é substancial, em 0,83.
correlation(dugong, 'Length', 'Age')| Out[1]: | 0.8296474554905714 |
Apesar da alta correlação, o gráfico mostra um padrão curvo que é muito mais visível no gráfico residual.
regression_diagnostic_plots(dugong, 'Length', 'Age')
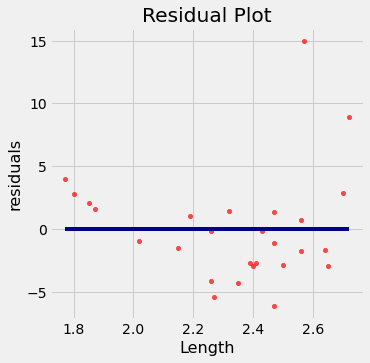
Enquanto você pode identificar a não linearidade na dispersão original, ela é mais claramente evidente no gráfico de resíduos.
No extremo inferior dos comprimentos, os resíduos são quase todos positivos; depois são quase todos negativos; e, em seguida, positivos novamente no extremo superior dos comprimentos. Em outras palavras, as estimativas de regressão têm um padrão de serem muito altas, depois muito baixas, depois altas novamente. Isso significa que teria sido melhor usar uma curva em vez de uma linha reta para estimar as idades.
Quando um gráfico de resíduos mostra um padrão, pode haver uma relação não linear entre as variáveis.
Detectando Heterocedasticidade
Heterocedasticidade é uma palavra que certamente será de interesse para aqueles que estão se preparando para competições de soletração. Para os cientistas de dados, seu interesse reside em seu significado, que é “distribuição desigual”.
Lembre-se da tabela hybrid que contém dados sobre carros híbridos nos EUA. Aqui está uma regressão da eficiência de combustível sobre a taxa de aceleração. A associação é negativa: carros que aceleram rapidamente tendem a ser menos eficientes.
regression_diagnostic_plots(hybrid, 'acceleration', 'mpg')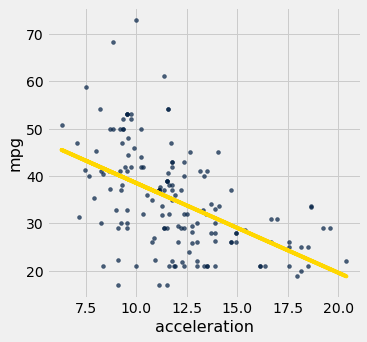
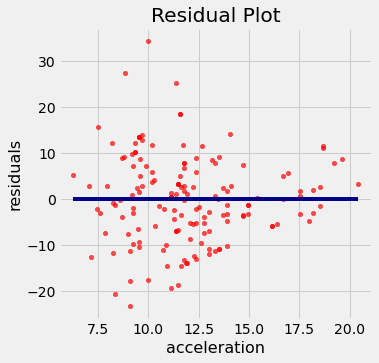
Observe como o gráfico residual se alarga em direção ao limite inferior das acelerações. Em outras palavras, a variabilidade no tamanho dos erros é maior para valores baixos de aceleração do que para valores altos. A variação desigual é frequentemente mais facilmente percebida em um valor residual gráfico de dispersão do que no gráfico de dispersão original.
Se o gráfico residual mostrar variação desigual em relação à linha horizontal em 0, as estimativas de regressão não serão igualmente precisas em todo o intervalo da variável preditora.
| ← Capítulo 15.4 – Regressão de Mínimos Quadrados | Capítulo 15.6 – Diagnóstico Numérico → |